Curriculum Temperature for Knowledge Distillation
Metadata
- AAAI 2023
- Authors: [[Zheng Li]], [[Xiang Li]], [[Lingfeng Yang]], [[Borui Zhao]], [[Renjie Song]], [[Lei Luo]], [[Jun Li]], [[Jian Yang]]
- Date: [[2022-12-24]]
- Date Added: [[2023-12-12]]
- URL: http://arxiv.org/abs/2211.16231
- Topics: [[privacy]]
- Tags: #Computer-Science—Computer-Vision-and-Pattern-Recognition, #/unread, #zotero, #literature-notes, #reference
- PDF Attachments
Abstract
Most existing distillation methods ignore the flexible role of the temperature in the loss function and fix it as a hyper-parameter that can be decided by an inefficient grid search. In general, the temperature controls the discrepancy between two distributions and can faithfully determine the difficulty level of the distillation task. Keeping a constant temperature, i.e., a fixed level of task difficulty, is usually sub-optimal for a growing student during its progressive learning stages. In this paper, we propose a simple curriculum-based technique, termed Curriculum Temperature for Knowledge Distillation (CTKD), which controls the task difficulty level during the student’s learning career through a dynamic and learnable temperature. Specifically, following an easy-to-hard curriculum, we gradually increase the distillation loss w.r.t. the temperature, leading to increased distillation difficulty in an adversarial manner. As an easy-to-use plug-in technique, CTKD can be seamlessly integrated into existing knowledge distillation frameworks and brings general improvements at a negligible additional computation cost. Extensive experiments on CIFAR-100, ImageNet-2012, and MS-COCO demonstrate the effectiveness of our method. Our code is available at https://github.com/zhengli97/CTKD.
Zotero links
Highlights and Annotations
- [[Curriculum Temperature for Knowledge Distillation - Comment AAAI 2023]]
KD 的 temperature 可以决定两个分布的差异性,以及确定蒸馏任务的困难水平。
保持恒定的温度,即任务难度的固定水平,对于正处于渐进学习阶段的成长中的学生来说,通常不是最佳选择。
本文提出的通过动态和可学习的温度,在学生的学习生涯中控制任务难度。从易到难的过程中,我们会逐渐增加蒸馏损失,从而以对抗的方式增加蒸馏难度。温度控制着分布的平滑度,可以忠实地确定损失最小化过程的难度级别
在人类教育中,教师总是用简单的课程来培养学生,从较容易的知识开始,到学生长大后逐渐呈现出更抽象、更复杂的概念
在学生的训练过程中,温度的学习采用反向梯度,目的是以对抗的方式最大限度地减少教师和学生之间的蒸馏损失(即增加学习难度)。
我们逐步增加蒸馏损失,并随温度的变化而变化,从而通过简单地动态调整温度来增加学习难度
较低的温度会使蒸馏更注重教师输出的最大对数。
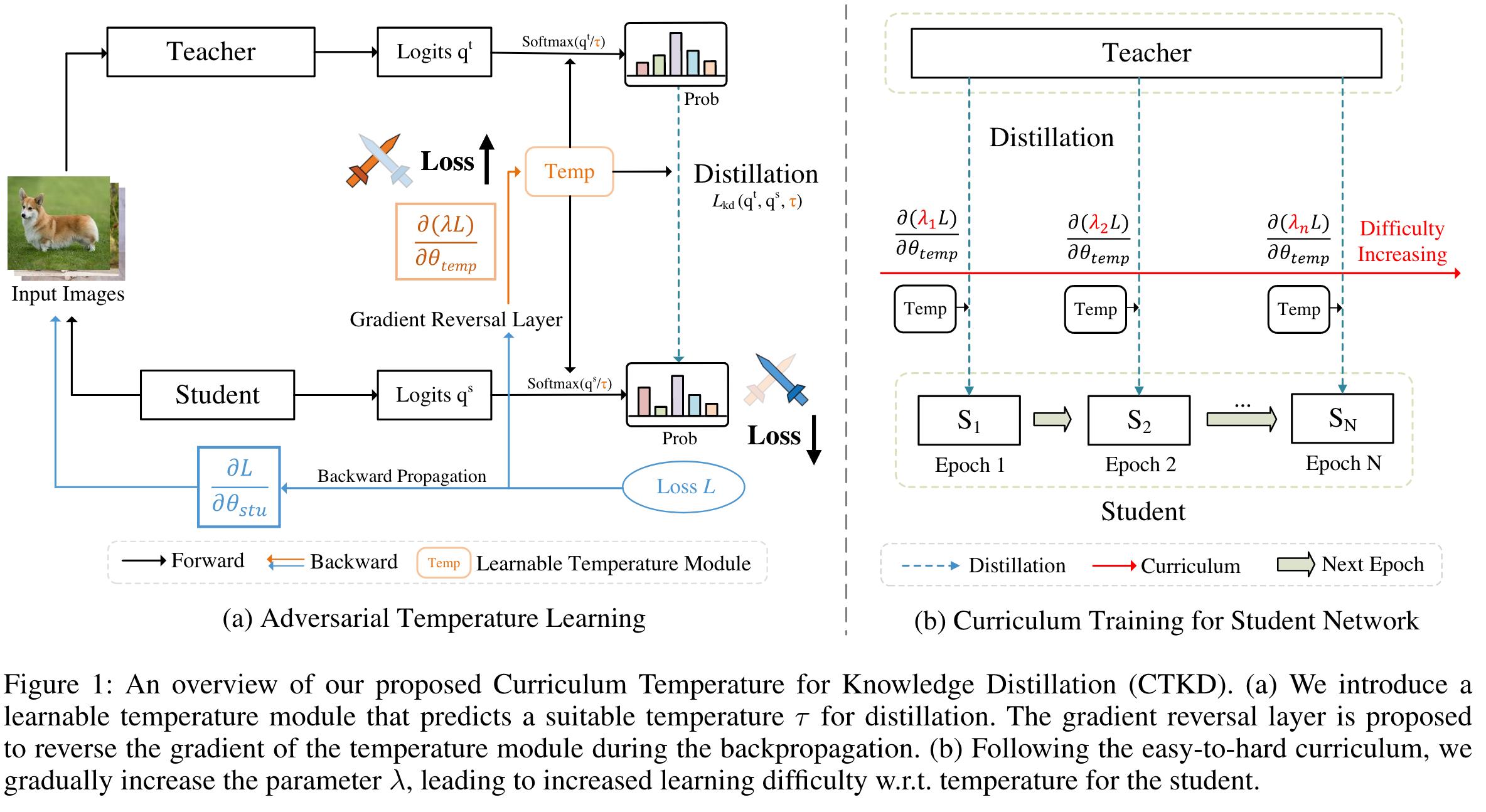
Adversarial Distillation
传统的蒸馏方法: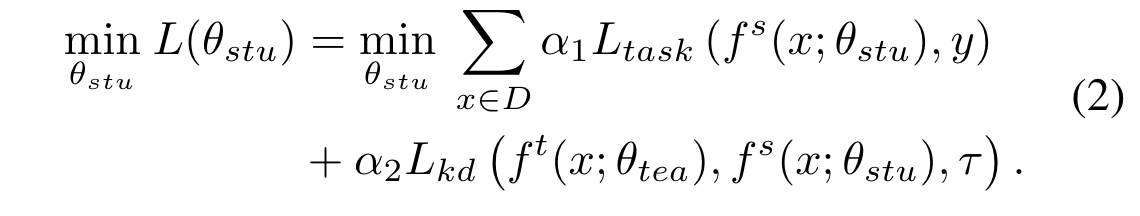
为了控制 student 学习的难度,对抗训练一个参数$\theta_{temp}$ 用于预测一个合适的温度值 $\tau$,这个模块是与 training 过程相反的方向优化,是为了最大化 student 和 teacher 的 distillation loss。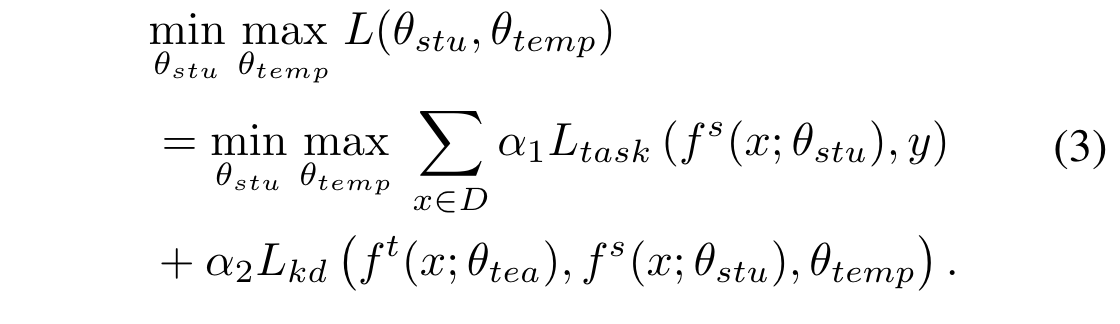
固定一个变量,训练另一个,转换为两个子问题: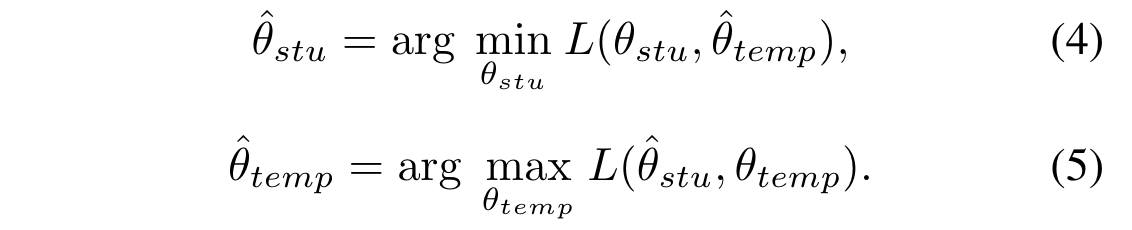
这两个子问题,通过随机梯度下降解决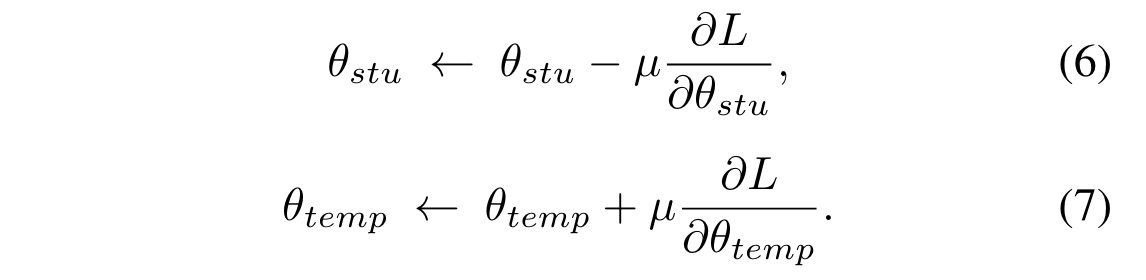
Curriculum Temperature
引入一个控制课程难度的变量$\lambda$, 用来放缩 loss 值 $L\rightarrow \lambda L$ ,此时,更新温度参数 temp: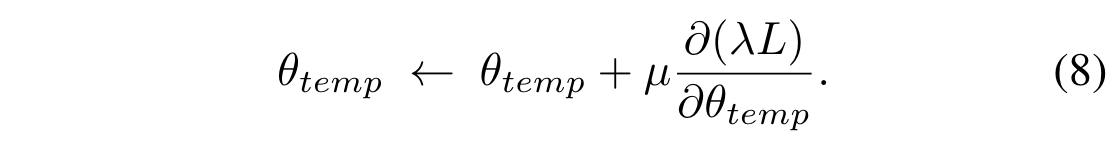
在初始的时候,学生只有有限的表征能力,学习能力比较差,设置初始的 $\lambda$ 为 0,通过逐渐增大 $\lambda$,学生学习更加复杂先进的知识作为蒸馏难度的增加。
两个限制条件:
逐渐增加 $\lambda$,以 cosine 形式: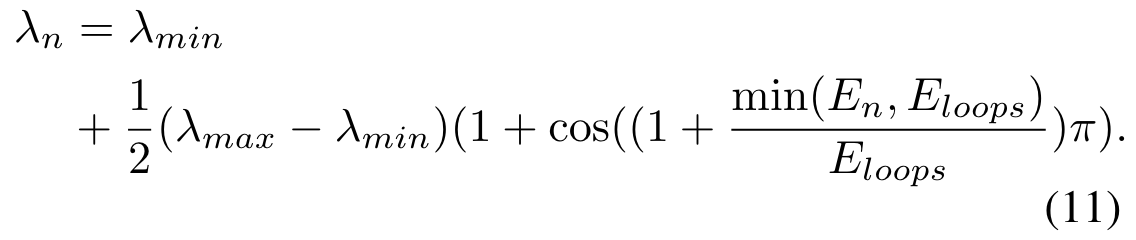
Learnable Temperature Module
两种可学习的参数模块:Global-T,Instance-T
Global-T
这种高效版本不会给蒸馏过程带来额外的计算成本,因为它只涉及一个可学习的参数。
Instance-T
一个 global 温度并不能准确地适用于所有情况。
我们进一步探索了实例方面的变体,称为实例-T,它可以单独预测所有实例的温度,例如,对于一批 128 个样本,我们 预测 128 个相应的温度值。受 GFLv2 的启发,我们提出利用概率分布的统计信息来控制自身的平滑度。
具体来说,我们的工作中引入了一个 2 层 MLP,它将两个预测值作为输入,并输出预测值 Tpred,如图 2(b)所示。在训练过程中,模块将自动学习原始分布和平滑分布之间的隐含关系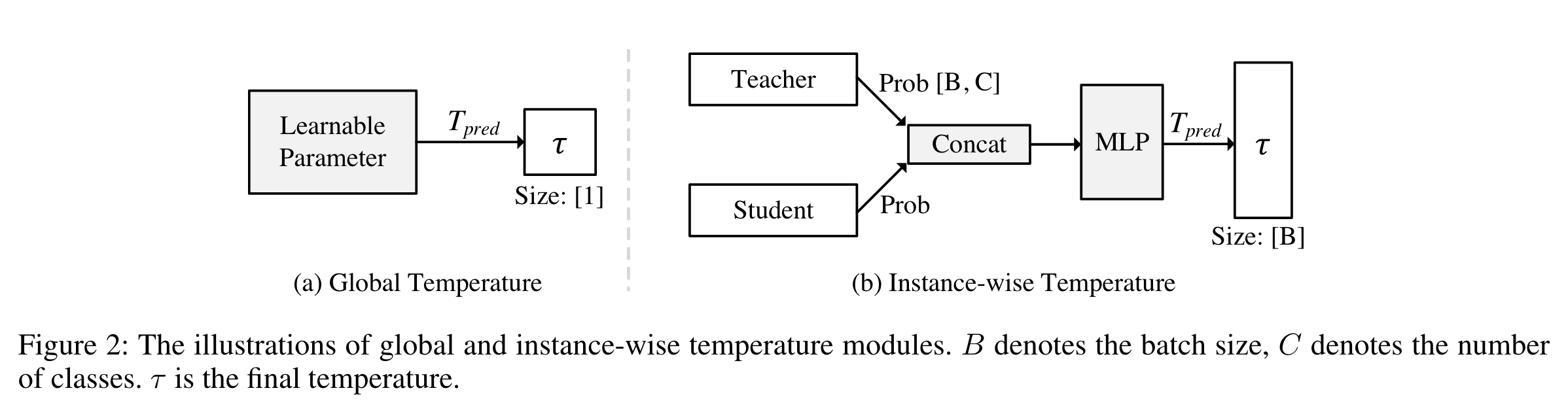
为确保温度参数的非负性并将其值保持在适当范围内,我们用以下公式对预测的 Tpred 值进行缩放
$\delta(\cdot)$ 是sigmoid 函数,$\tau_{init}=1,\tau_{range}=20$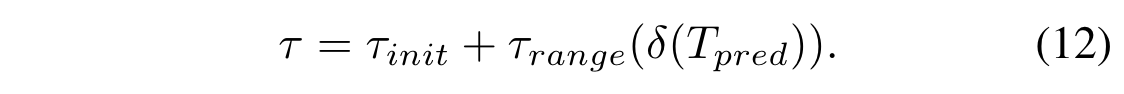
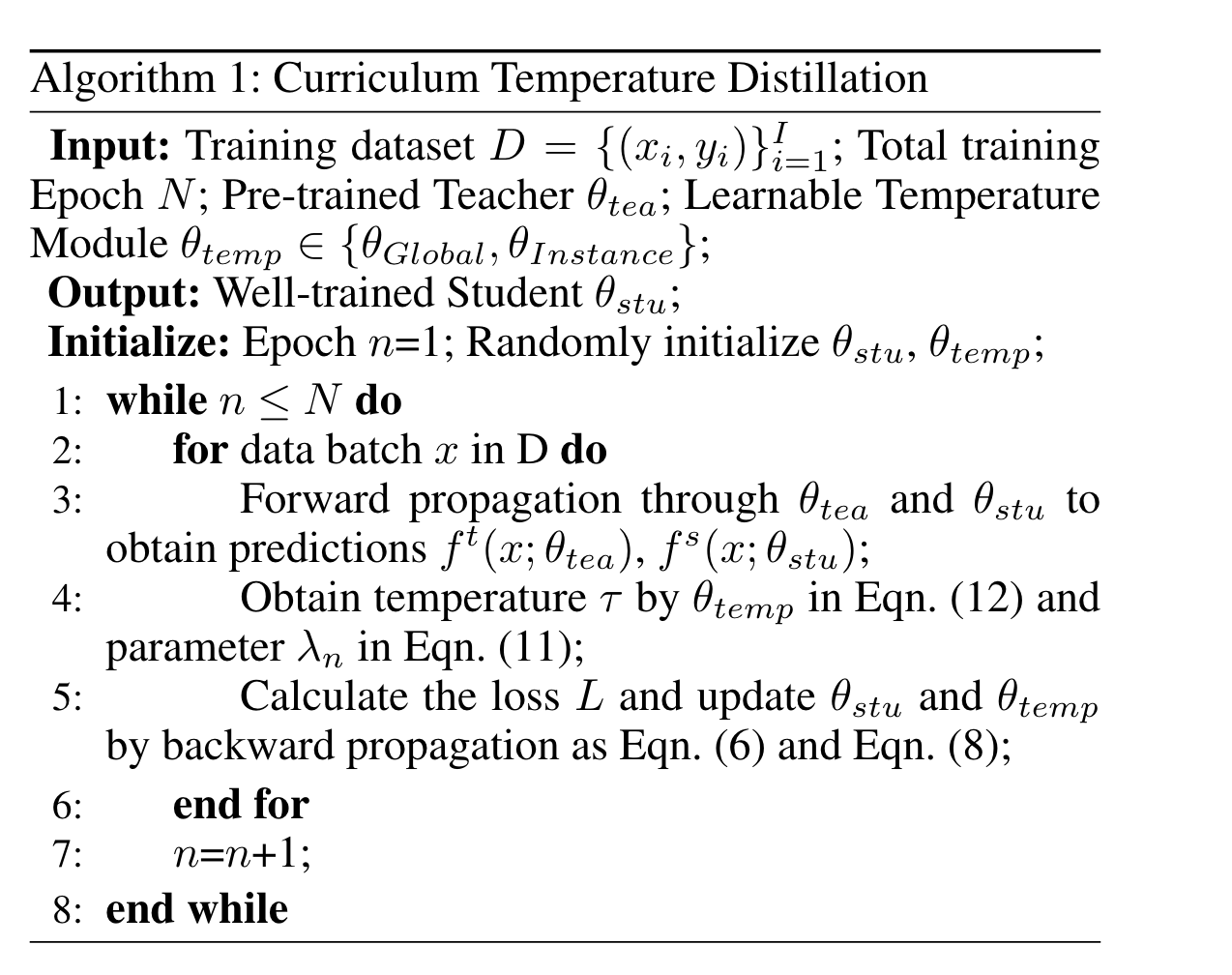
与 global T 相比,Instance-T 可以实现更好的蒸馏性能,但是因为引入了额外的 MLP,需要更多的计算成本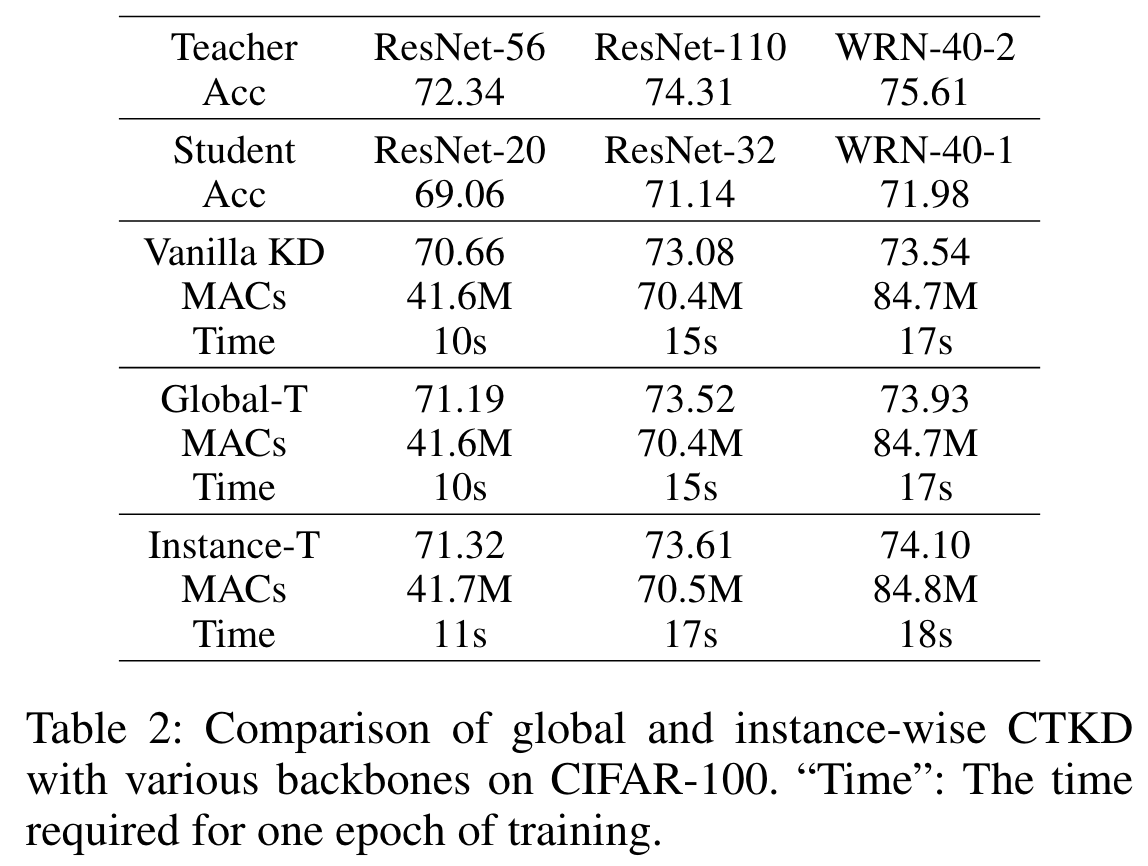
Experiments
CIFAR-100 分类,CTKD 在所有模型上都优于传统的KD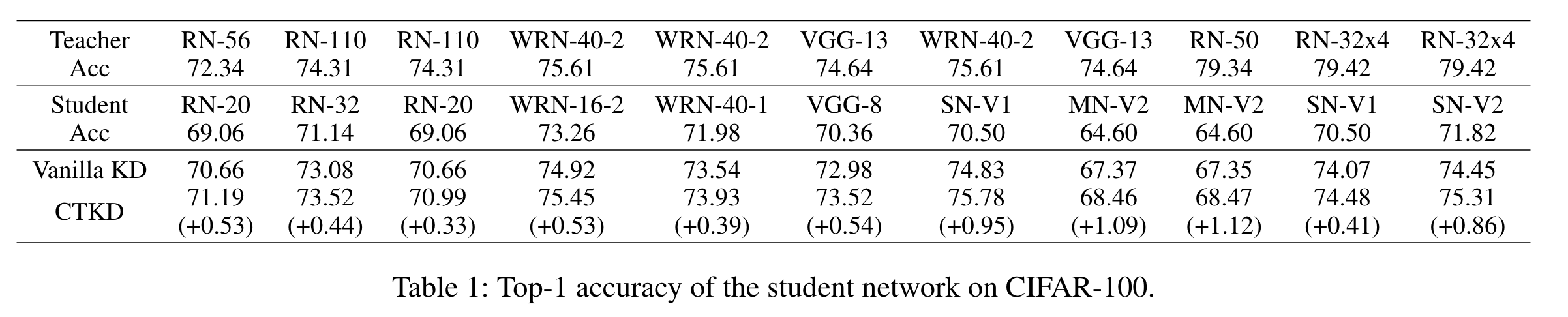
因此,总体损失仍呈下降趋势。如图 3 所示,CTKD 的蒸馏损失高于 vanilla 方法,证明了对抗性温度蒸馏的有效性。可以看出,CTKD 的蒸馏损失高于 vanilla KD,证明了对抗操作的效果。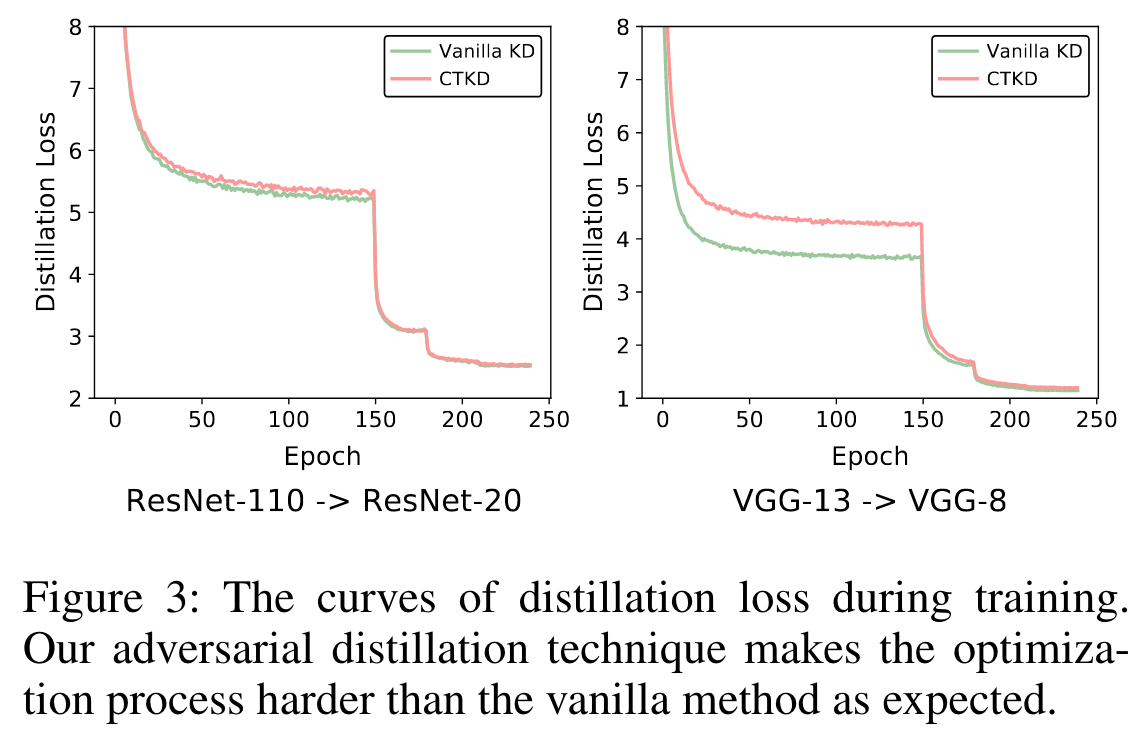
与 vanilla KD 相比,我们的方法的表征可分离度更高,这证明 CTKD 有利于深度特征的可分辨性。
与固定温度蒸馏法相比,我们的课程温度法通过有效的动态机制取得了更好的结果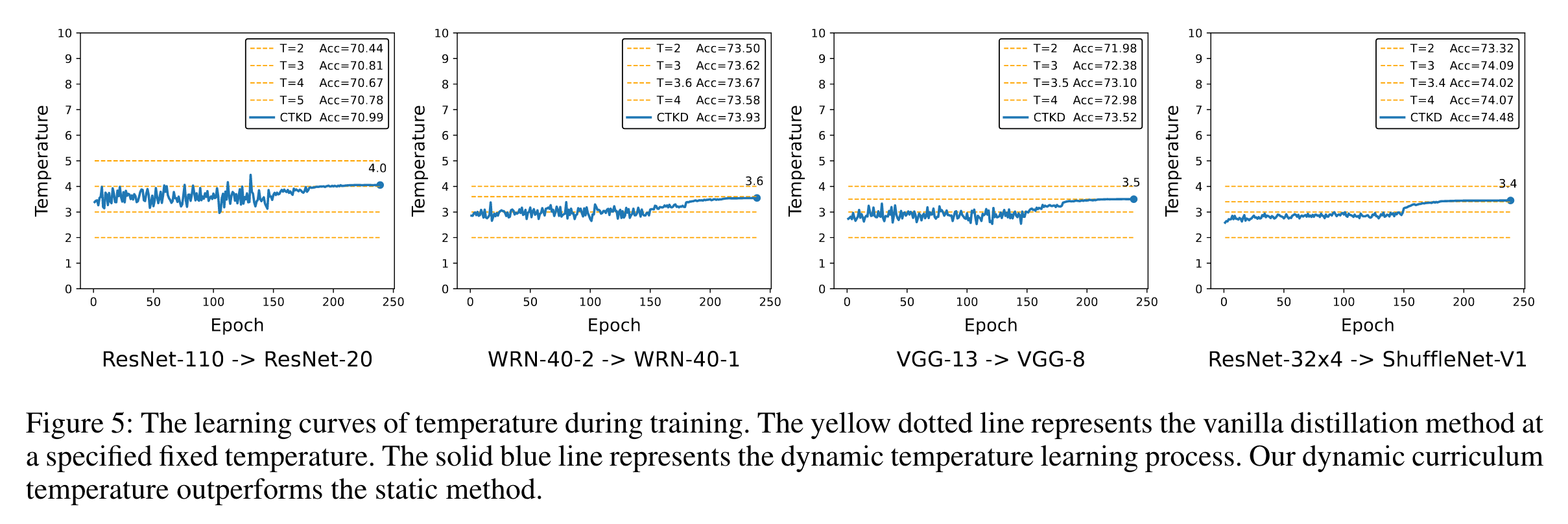
CTKD可以无缝衔接应用于别的最新的KD任务
更重要的是,CTKD 只包含一个轻量级可学习温度模块和一个非参数化 GRL ,因此不会增加计算成本。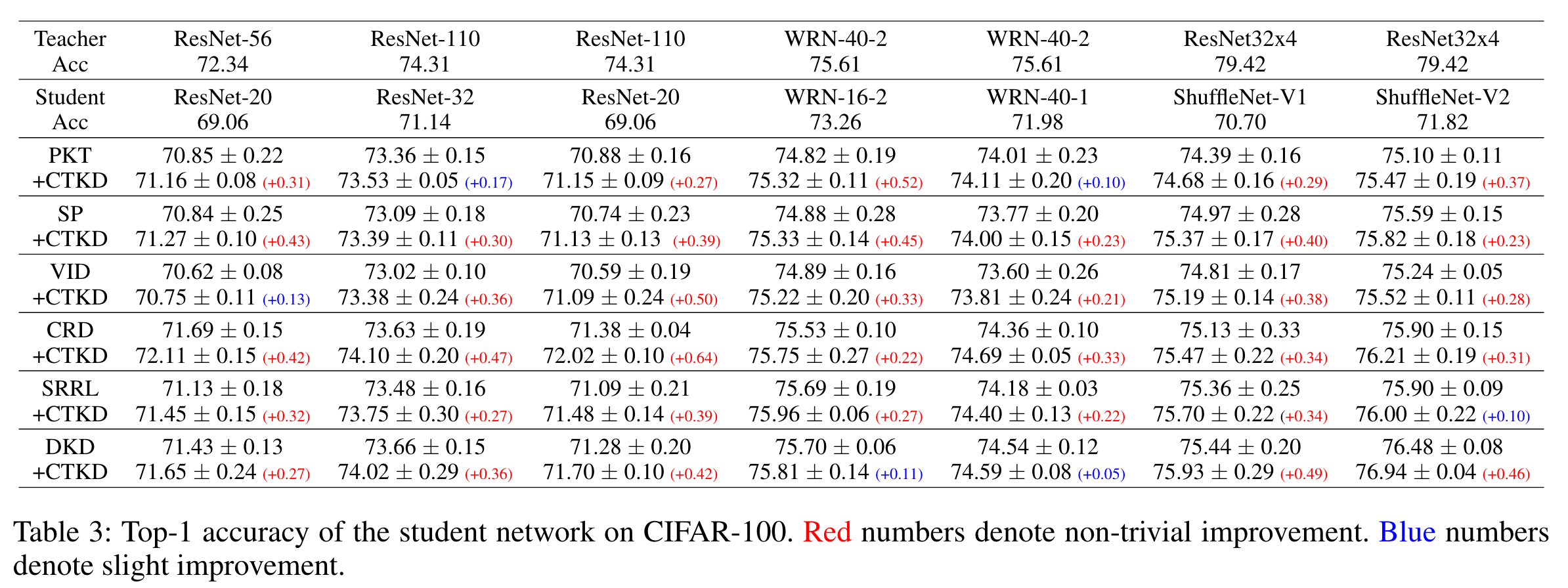
ImageNet-2012 上排名前 1/5 的图像分类准确率。作为一种插件技术,我们还将 CTKD 应用于现有的四种最先进的蒸馏方法。结果表明,CTKD 仍能在大规模数据集上有效工作。

消融研究
在接下来的实验中,我们将评估超参数和组件在 CIFAR-100 上的有效性。我们将 ResNet-110 设置为教师,将 ResNet-32 设置为学生。
Curriculum parameters
表 6 列出了不同 λmin、λmax 和 Eloops 时学生的准确率。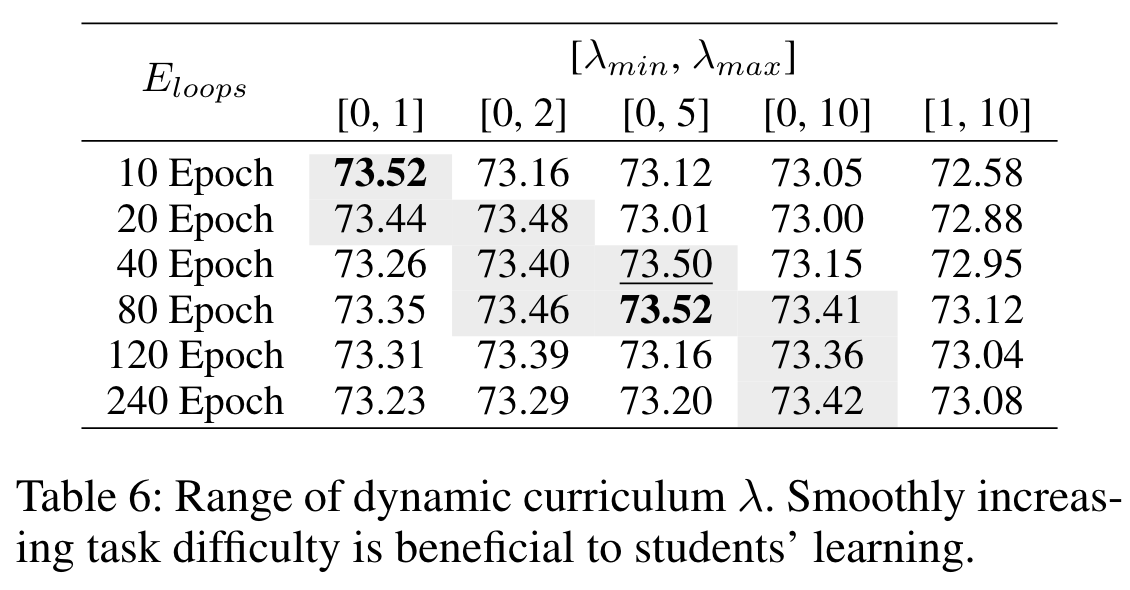
表 7 报告了不同固定 λ 下的蒸馏结果。直接从固定的高难度任务开始会大大降低学生的学习成绩,特别是当λ 大于 4 时。此外,如表 6 的第六列和第七列所示,在短时间内快速增加参数λ 也不利于学生的训练。
Curriculum strategy.
在表 8 中,我们比较了不同课程设置策略的性能。”$None_{τ=1}$, 10 Epoch “表示在训练的前 10 个 Epoch 中,我们只使用香草蒸馏法,并设置温度 τ = 1。10 个epochs后,我们开始使用 CTKD 训练学生,λ 被固定为 1。”$Lin_{[0,1]}$, 10 Epoch “表示我们使用 CTKD 以线性递增策略训练学生。参数 λ 在 10 次训练中从 0 逐步增加到 1。直到训练结束,λ 值一直保持为 1。从表中可以看出,余弦课程策略效果最好。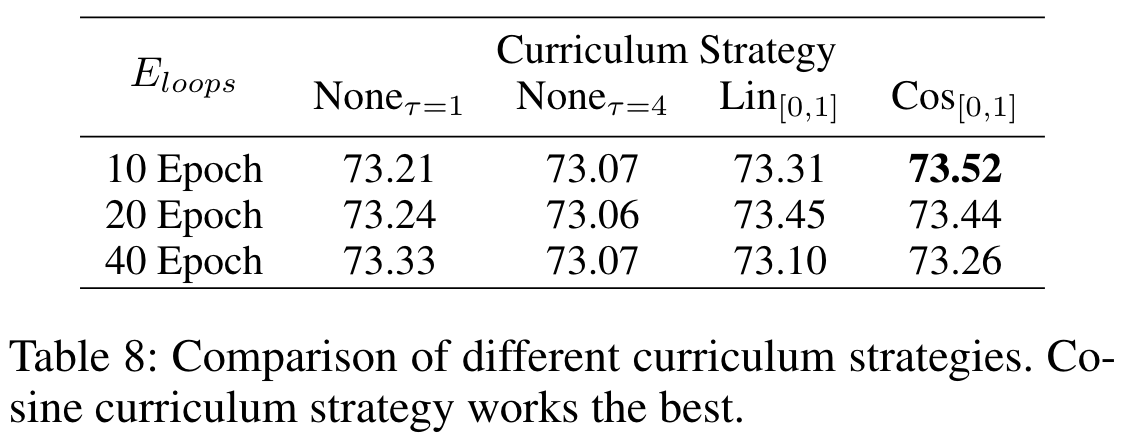
Adversarial temperature and curriculum distillation
我们对这两个要素的有效性进行了评估,如表 9 所示。第二行表示我们只采用对抗式温度技术,并使用固定的学习难度(即固定 λ 为 1)来训练学生。结果表明,以对抗方式学习温度参数也能提高蒸馏性能。第三行显示了合作与单个元素相比,两个元素的组合能取得更好的效果。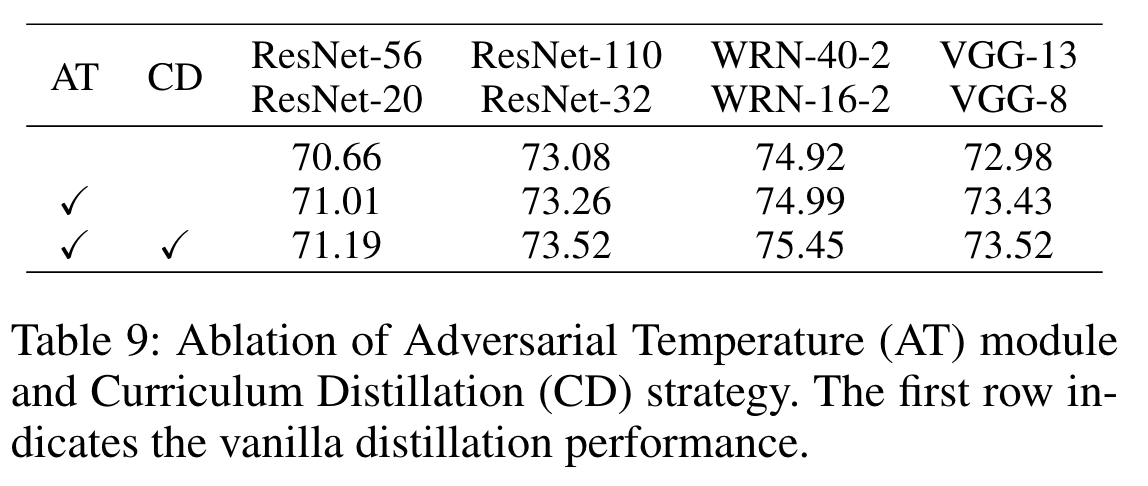
Conclusion
在本文中,我们提出了一种基于课程的蒸馏方法,称为 “知识蒸馏的课程温度”,它通过一个动态的、可学习的温度来组织由易到难的蒸馏任务。温度是在学生的训练过程中以反向梯度学习的,目的是以对抗的方式最大化教师和学生之间的蒸馏损失(即增加学习难度)。作为一种易于使用的插件技术,CTKD 可以无缝集成到现有的最先进的知识蒸馏框架中,并以可忽略不计的额外计算成本带来全面的改进。

