Knowledge Distillation: A Survey
Metadata
- Item Type: [[Article]]
- Authors: [[Jianping Gou]], [[Baosheng Yu]], [[Stephen J. Maybank]], [[Dacheng Tao]]
- Date: [[06/2021]]
- Date Added: [[2023-12-01]]
- URL: https://link.springer.com/10.1007/s11263-021-01453-z
- DOI: 10.1007/s11263-021-01453-z
- Topics: [[KD]]
- Tags: #Knowledge-Distillation #Survey
- PDF Attachments
Abstract
In recent years, deep neural networks have been successful in both industry and academia, especially for computer vision tasks. The great success of deep learning is mainly due to its scalability to encode large-scale data and to maneuver billions of model parameters. However, it is a challenge to deploy these cumbersome deep models on devices with limited resources, e.g., mobile phones and embedded devices, not only because of the high computational complexity but also the large storage requirements. To this end, a variety of model compression and acceleration techniques have been developed. As a representative type of model compression and acceleration, knowledge distillation effectively learns a small student model from a large teacher model. It has received rapid increasing attention from the community. This paper provides a comprehensive survey of knowledge distillation from the perspectives of knowledge categories, training schemes, teacher–student architecture, distillation algorithms, performance comparison and applications. Furthermore, challenges in knowledge distillation are briefly reviewed and comments on future research are discussed and forwarded.
Zotero links
巨大的计算复杂性和海量存储需求使得将它们部署在实时应用中成为巨大的挑战,特别是在资源有限的设备上,例如视频监控和自动驾驶汽车。
- Parameter pruning and sharing 删除无关紧要的参数
- Low-rank factorization 通过采用矩阵和张量分解来识别深度神经网络的冗余参数
- Transferred compact convolutional filters 通过传输或压缩卷积滤波器来删除不重要的参数
- Knowledge distillation (KD) 将较大深度神经网络中的知识提取到小型网络中
KD 将信息从大型模型或模型集合传输到训练小型模型,而不会显着降低准确性。
由于模型能力差距,较大的模型可能并不是更好的老师
普通的知识蒸馏使用大型深度模型的逻辑作为教师知识,中间层的激活、神经元或特征也可以作为指导学生模型学习的知识
- response-based knowledge
- feature-based knowledge
- relation-based knowledge
2.1 Response-Based Knowledge
指教师模型最后输出层的神经响应,让学生模型直接模仿教师模型的最终预测。
向量 $z$ 表示 logits ,作为深度模型最后一个全连接层的输出,基于响应的知识的蒸馏损失可以表示为:
$\mathcal{L}_R(\cdot)$ 是 logits 的发散 loss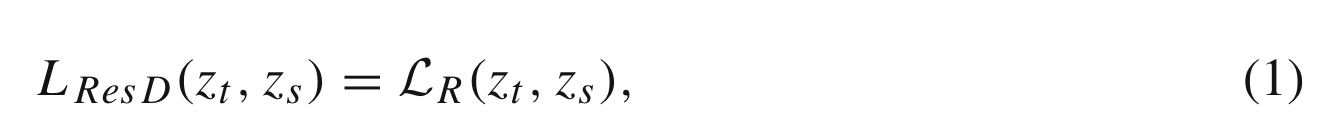
基于响应的 KD 模型如下: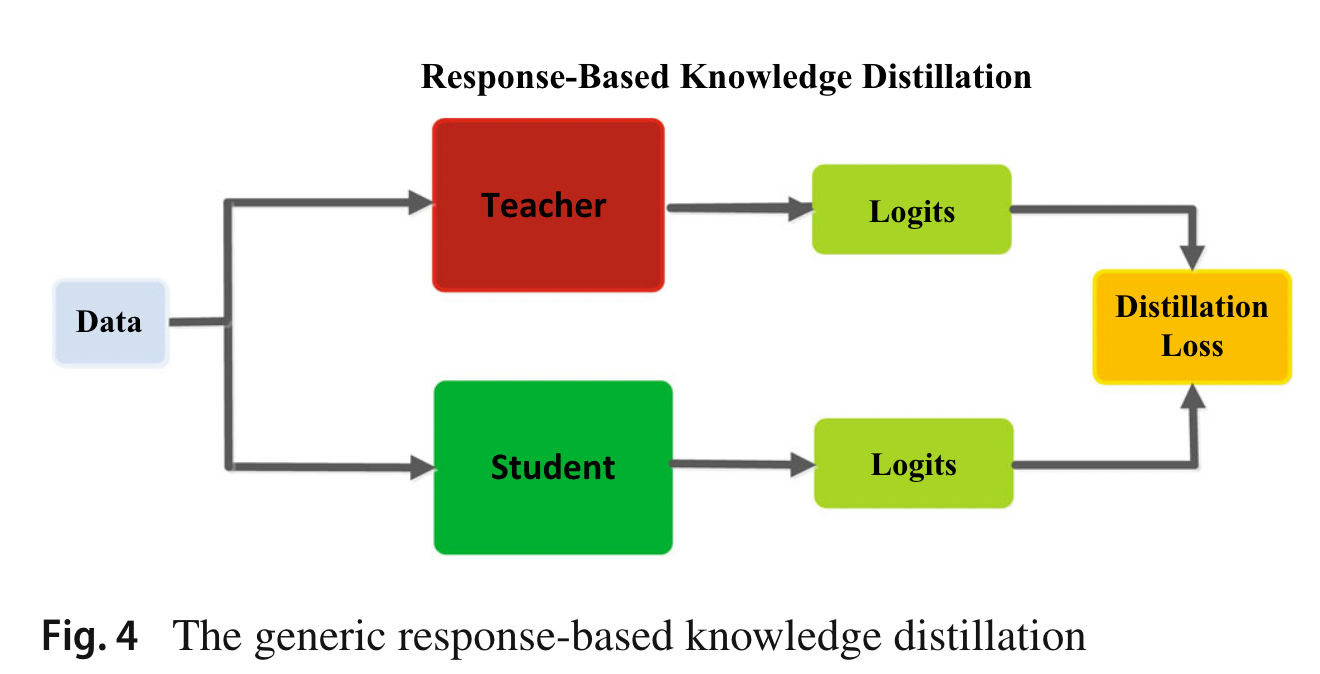
基于响应的知识被进一步探索,以将真实标签的信息作为条件目标,最流行的基于响应的图像分类知识被称为软目标。软目标是输入属于类别的概率,可以通过 softmax 函数估计为:
$z_i$ 是第 i 类的 logits,温度 T 用于控制 soft target 的重要性。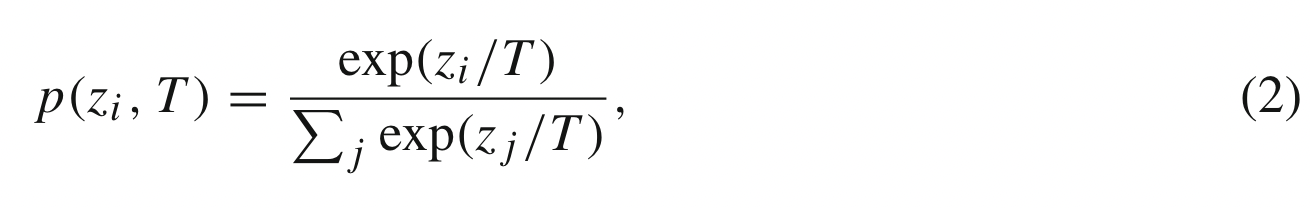
软 logits 的蒸馏损失可以重写为: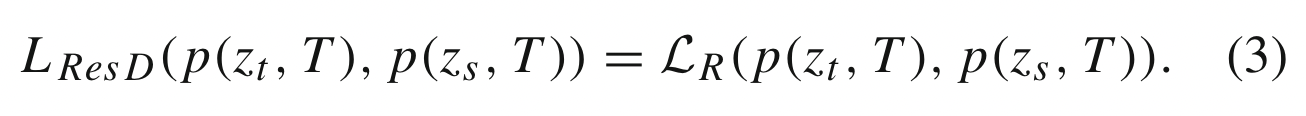
学生损失始终定义为学生模型的真实标签和软 logits 之间的交叉熵损失 $\mathcal{L}_{CE}(y,p(z_s,T=1))$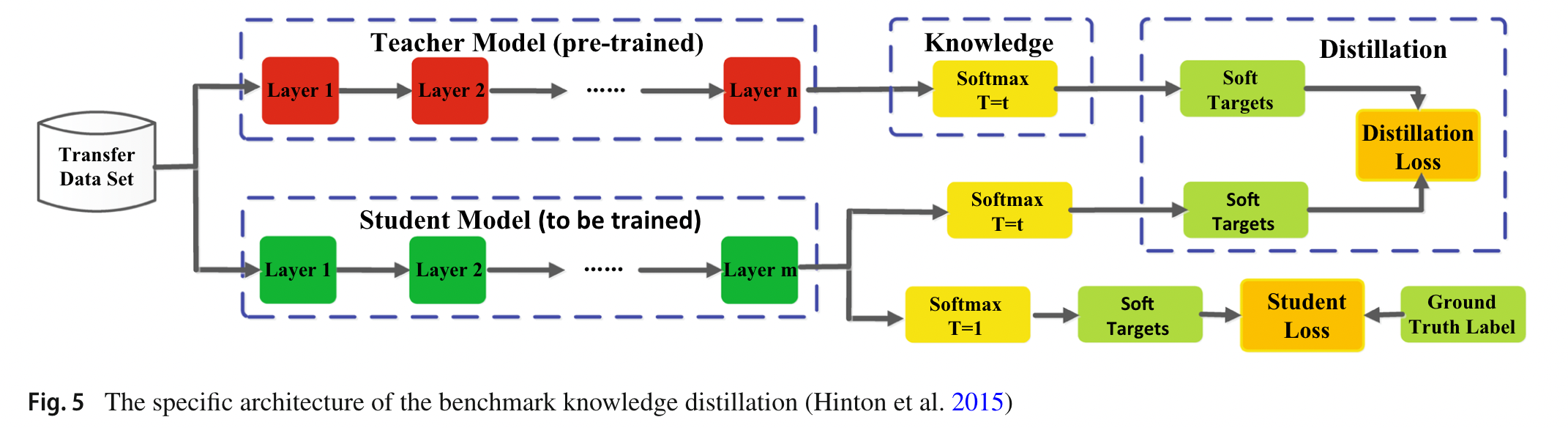
但是,基于响应的知识通常依赖于最后一层的输出,例如软目标,因此无法解决教师模型的中级监督问题,而这对于使用非常深的神经网络的表示学习非常重要!
此外,由于软逻辑实际上是类别概率分布,因此基于响应的知识蒸馏也仅限于监督学习。
2.2 Feature-Based Knowledge
学习多个层次的特征表示。这称为表示学习。最后一层的输出和中间层的输出,即 feature map 特征图,都可以作为知识来监督学生模型的训练。
中间层的基于特征的 KD 是基于响应的 KD 的良好扩展,特别是对于更薄和更深的网络的训练,主要思想是:匹配教师和学生的特征激活。
可以从 feature map 中导出 attention map 来表达知识,教师模型中间层的参数共享以及基于响应的知识也被用作教师知识。
有人提出,跨层知识蒸馏,通过注意力分配自适应地为每个学生层分配适当的教师层。
基于特征的知识转移的蒸馏损失表示为:
$f_t(x)$ 和 $f_s(x)$ 分别是 teacher 和 student 模型中间层输出的结果。
$\phi_t(f_t(x))$ 是因为二者不是相同的形状的映射函数
$L_F(\cdot)$ 是匹配教师和学生特征图的相似度函数。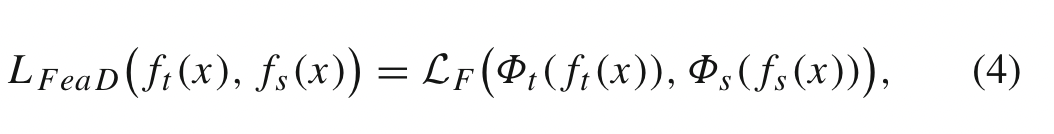
如图,虽然基于特征的知识迁移为学生模型的学习提供了有利的信息,但如何有效地选择教师模型中的提示层和学生模型中的引导层仍有待进一步研究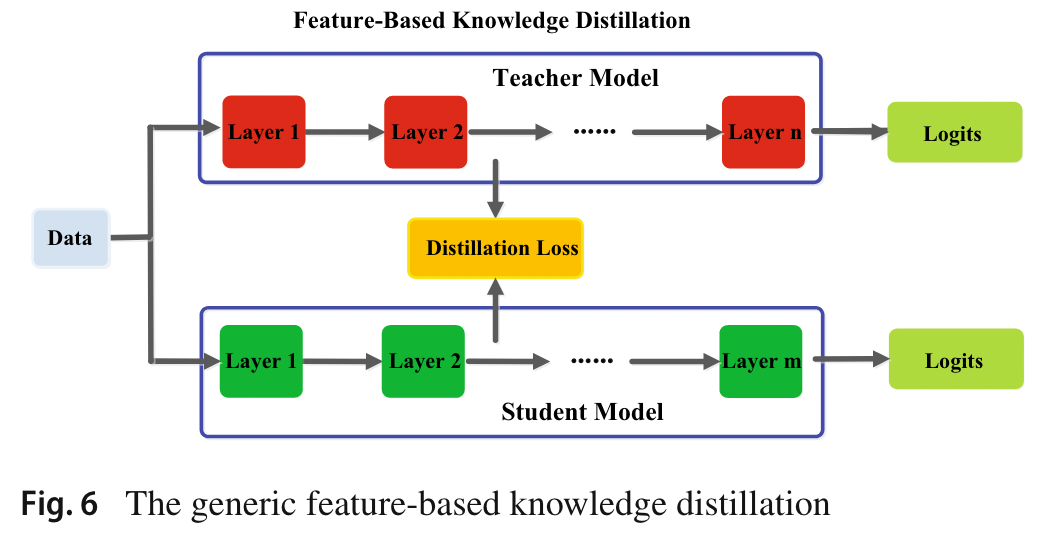
2.3 Relation-Based Knowledge
基于 Response 或者 Feature 的 KD 都是用了某些层的输出结果
Relation-based KD 探索不同层或者不同数据样本之间的关系
一般来说,基于特征图关系的基于关系的知识的蒸馏损失可以表示为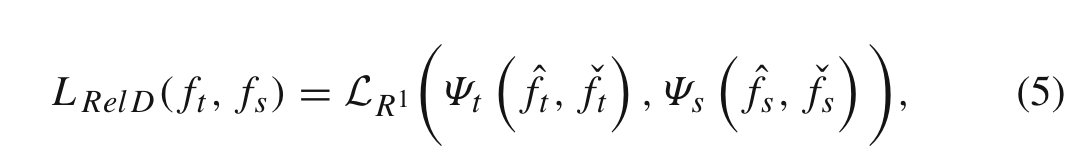
Ψt (.) 和 Ψs(.) 是来自教师和学生模型的特征图对的相似度函数。 LR1(.)表示教师和学生特征图之间的相关函数。
传统的知识转移方法通常涉及个人知识的蒸馏。教师的个人软目标直接提炼到学生身上。事实上,蒸馏出来的知识不仅包含特征信息,还包含数据样本之间的相互关系
3 Distillation Schemes
根据教师模型是否与学生模型同步更新,知识蒸馏的学习方案可以直接分为三大类:
- offline distillation
- online distillation
- self-distillation
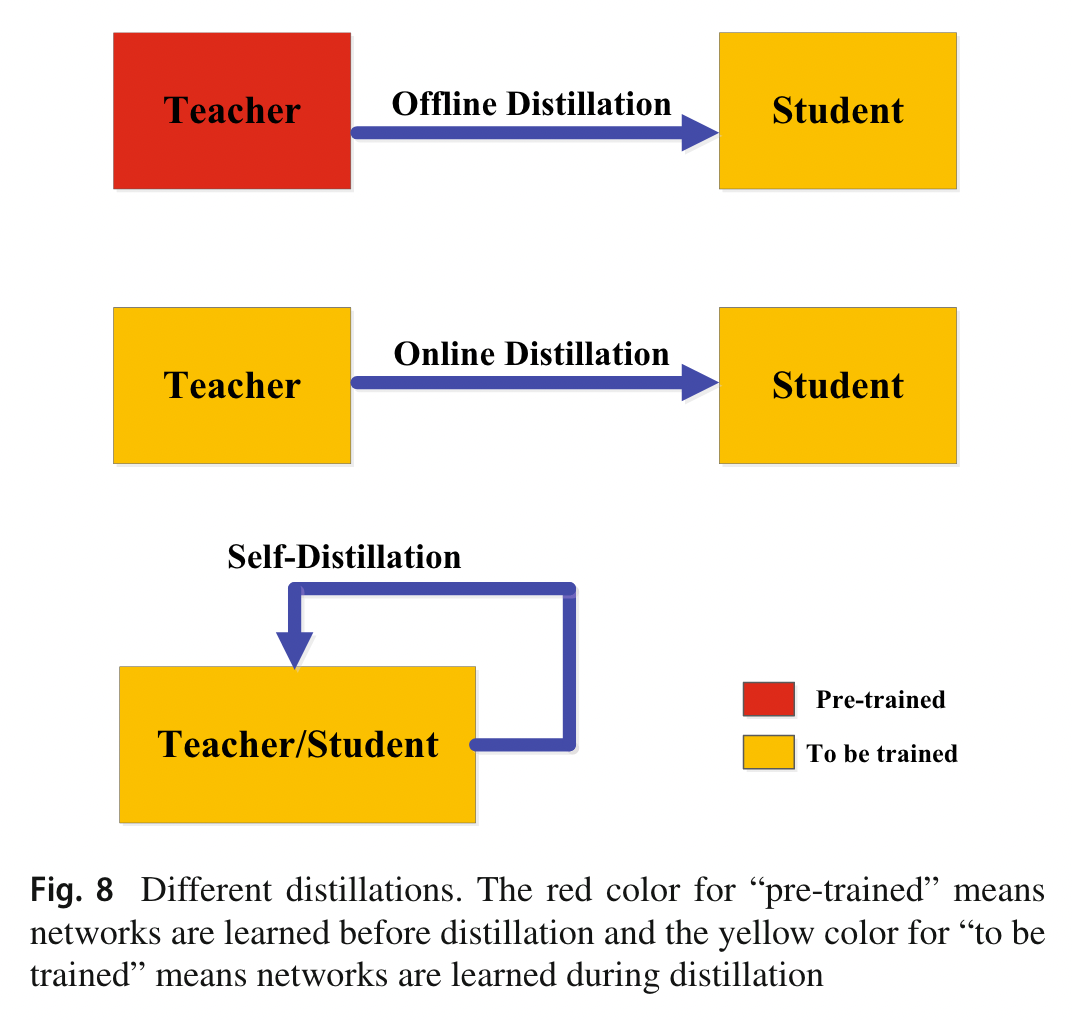
以前的知识蒸馏方法大多数都是离线工作的:
- 在蒸馏之前,大型教师模型首先在一组训练样本上进行训练
- 教师模型用于以逻辑或中间特征的形式提取知识,然后在蒸馏过程中用于指导学生模型的训练。
离线方法的主要优点是简单且易于实现。例如,教师模型可能包含一组使用不同软件包训练的模型,这些软件包可能位于不同的机器上。可以提取知识并将其存储在缓存中。
采用单向知识转移和两阶段培训程序。然而,无法避免复杂的大容量教师模型和巨大的训练时间,而离线蒸馏中学生模型的训练通常在教师模型的指导下是高效的。而且,大老师和小学生之间的能力差距始终存在,学生往往很大程度上依赖老师。
3.2 Online Distillation
进一步提高学生模型的性能,特别是在没有大容量高性能教师模型的情况下。在在线蒸馏中,教师模型和学生模型同时更新
并行共蒸馏可以训练具有相同架构的多个模型,并且任何一个模型都是通过转移其他模型的知识来训练的。
3.3 Self-Distillation
self-distillation: 网络深层部分的知识被提炼到浅层部分。
self-attention distillation method:该网络利用其自身层的注意力图作为其较低层的蒸馏目标。
Snapshot distillation:网络早期时期(教师)的知识被转移到后期时期(学生),以支持同一网络内的监督训练过程。
self knowledge 由预测概率组成,而不是传统的软概率。预测概率反映特征嵌入空间中数据的相似性。
class-wise self knowledge distillation : 逐类自知识蒸馏,以匹配具有相同模型的同一源内的类内样本和增强样本之间的训练模型的输出分布
Offline distillation 线下蒸馏意味着知识渊博的老师向学生传授知识
Online distillation 在线蒸馏是师生共同学习
Self-distillation 学生自学知识
4 Teacher–Student Architecture
目前的研究教师和学生的模型设置在蒸馏过程中几乎是预先固定的,尺寸和结构不变,因此很容易导致 capacity gap。
复杂的 DNN 主要来源于:width and depth
KD 是将知识从更深更广的神经网络转移到更浅更薄的神经网络
student network来自:
- a simplified version of a teacher network with fewer layers and fewer channels in each layer
- a quantized version of a teacher network in which the structure of the network is preserved
- a small network with efficient basic operations
- a small network with optimized global network structure
- the same network as teacher
现有的方法: - 引入了教师助理来缩小教师模型和学生模型之间的训练差距。
- 通过残差学习进一步缩小差距,即使用辅助结构来学习残差误差
- 最小化学生模型和教师模型结构的差异。
- 将多层学到的知识转移到单层
受神经架构搜索(NAS)成功的启发,通过搜索基于高效元操作或块的全局结构,小型神经网络的性能得到了进一步提高。在给定教师网络的情况下搜索最佳学生网络。
为了有效地进行知识转移并探索多个教师的力量,已经提出了几种替代方法,通过向给定教师添加不同类型的噪声来模拟多个教师
由于不同教师的知识不同,多教师知识蒸馏可以提供丰富的知识并定制通用的学生模型。然而,如何有效整合来自多个教师的不同类型的知识还有待进一步研究。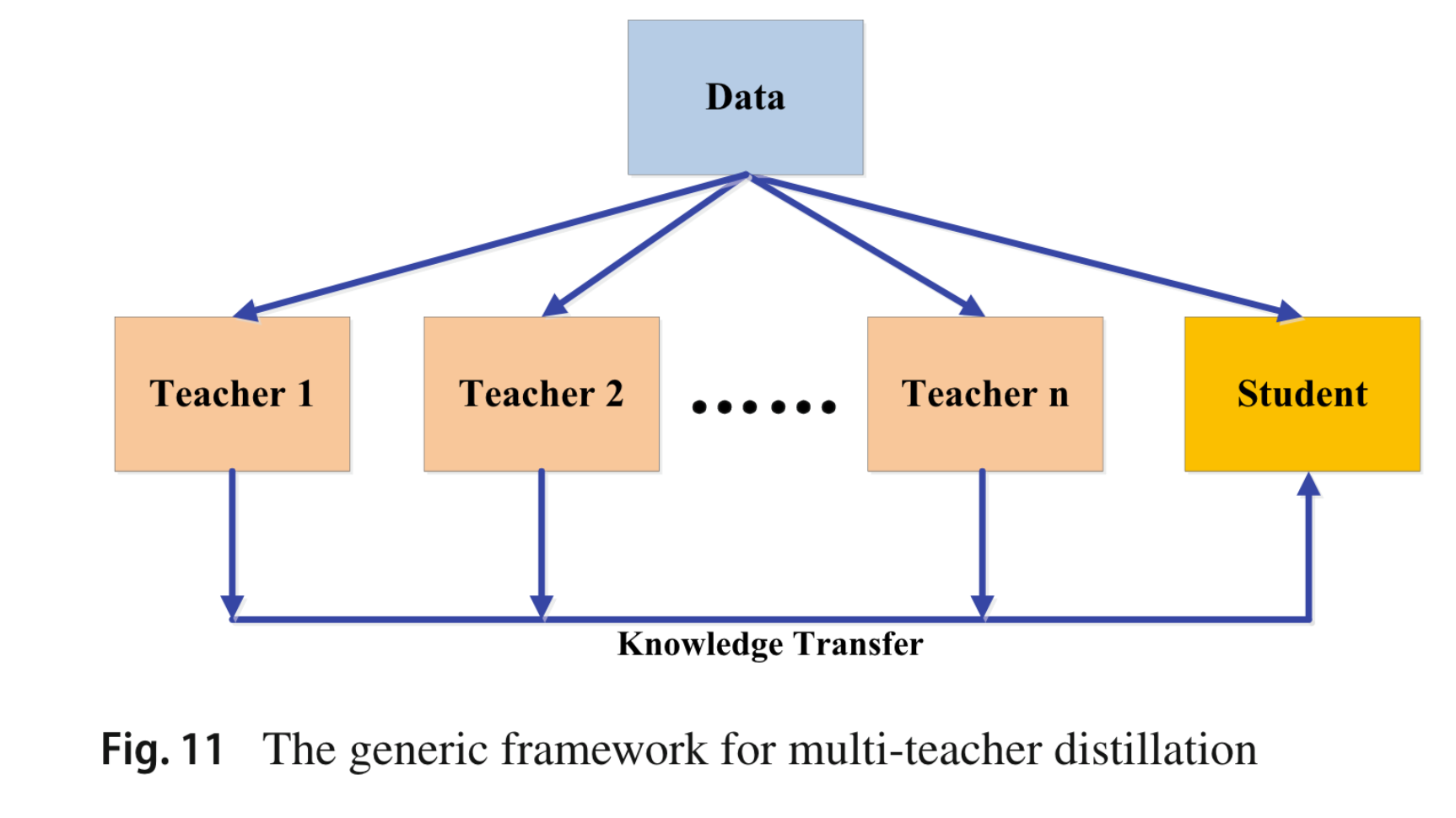
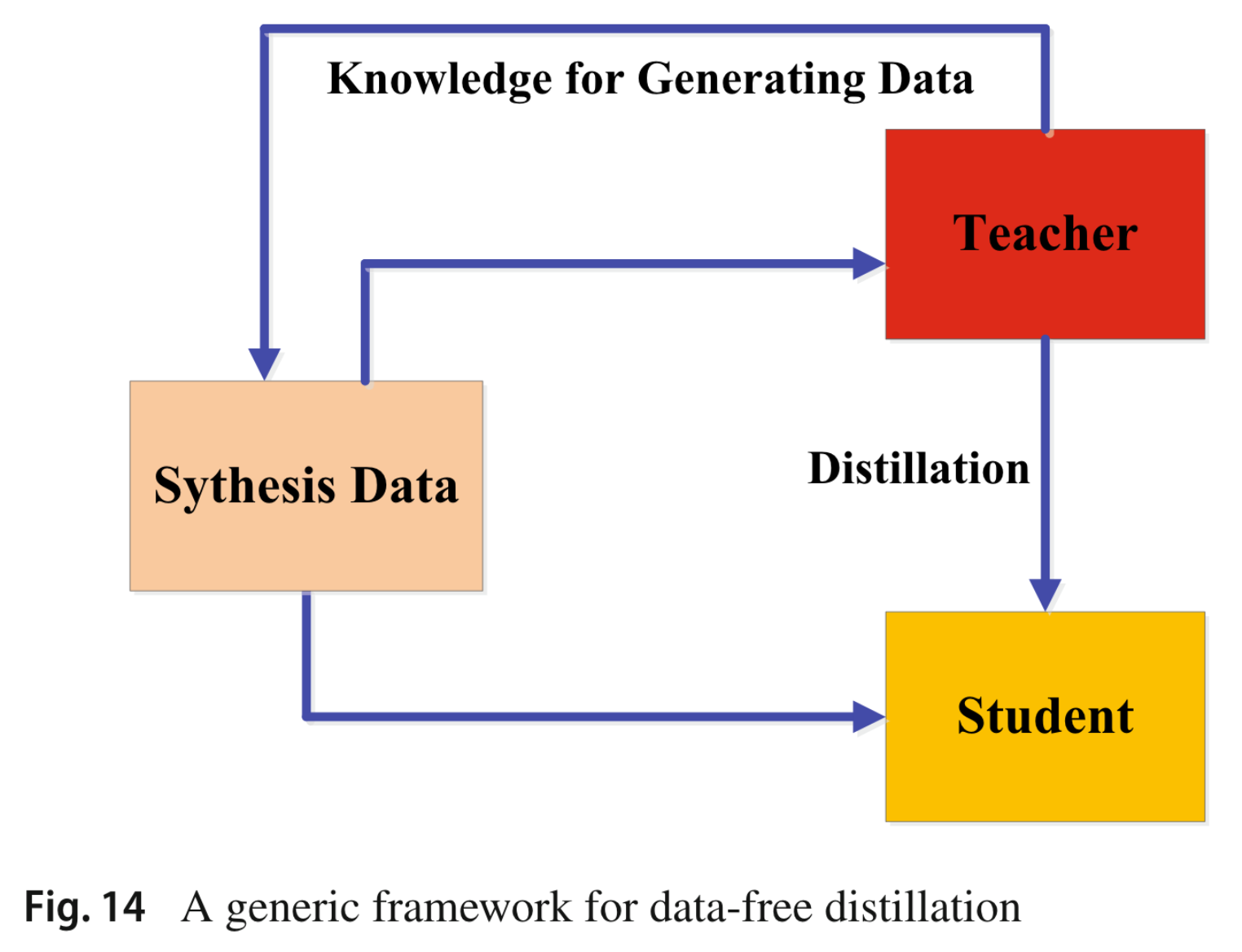
无数据蒸馏中的综合数据通常是根据预先训练的教师模型的特征表示生成的,如图14所示。尽管无数据蒸馏在数据不可用的情况下显示出了巨大的潜力,它仍然是一个非常具有挑战性的任务,即如何生成高质量的多样化训练数据以提高模型的泛化性。