DP-Forward: Fine-tuning and Inference on Language Models with Differential Privacy in Forward Pass
Metadata
- Tags: #Differential-Privacy #Fine-tune #LLM
- Authors: [[Minxin Du]], [[Xiang Yue]], [[Sherman S. M. Chow]], [[Tianhao Wang]], [[Chenyu Huang]], [[Huan Sun]]
Abstract
Differentially private stochastic gradient descent (DP-SGD) adds noise to gradients in back-propagation, safeguarding training data from privacy leakage, particularly membership inference. It fails to cover (inference-time) threats like embedding inversion and sensitive attribute inference. It is also costly in storage and computation when used to fine-tune large pre-trained language models (LMs). We propose DP-Forward, which directly perturbs embedding matrices in the forward pass of LMs. It satisfies stringent local DP requirements for training and inference data. To instantiate it using the smallest matrix-valued noise, we devise an analytic matrix Gaussian mechanism (aMGM) by drawing possibly non-i.i.d. noise from a matrix Gaussian distribution. We then investigate perturbing outputs from different hidden (sub-)layers of LMs with aMGM noises. Its utility on three typical tasks almost hits the non-private baseline and outperforms DP-SGD by up to 7.7pp at a moderate privacy level. It saves 3× time and memory costs compared to DP-SGD with the latest high-speed library. It also reduces the average success rates of embedding inversion and sensitive attribute inference by up to 88pp and 41pp, respectively, whereas DP-SGD fails.
- 笔记
- Zotero links
Abstract
DP-SGD 在 BP 的时候给 gradients 添加噪声,抵抗 membership inference. 但是,无法抵抗 inference-time threats,比如 embedding inversion, sensitive attribute inference.
此外,对于微调大模型的时候,这种方法在 storage and computation 是开销较大的。
提出 DP-Forward,在 LMs 前向传播的时候,直接对 embedding matrices 扰动,对于训练和推理数据严格满足本地化差分隐私的需求。
通过从一个矩阵高斯分布提取 non-iid 的噪声,设计一种解析矩阵高斯机制 (aMGM),我们研究对 LMs 不同的隐藏(子)层使用 aMGM 噪声来扰动输出。
在三种典型的任务中,几乎达到了非隐私的基线水平,比 DP-SGD 在中等隐私水平情况下达到了 7.7pp 的提升。比DP-SGD节省了3倍时间和存储,同时降低了 embedding inversion 和敏感属性推理的成功率达到了 88pp 和 41 pp。
1 Introduction
Transformer 的深度学习架构现在在计算机视觉中越来越受欢迎,并已广泛应用于自然语言处理(NLP)中。基于 Transformer 的语言模型(LM),例如 BERT 和 GPT,在几乎所有 NLP 任务中都取得了最先进的性能。首先在大量的公共的有标签的语料库上完成预训练,然后更小的多样的任务上微调。微调大模型避免了从头开始训练和特定任务语料库可能出现的短缺,同时获得了多功能性。
用于微调的数据是比较敏感的,LMs可能在无意中记忆,可能导致 membership inference attacks(MIAs),用于识别一个样本是否在训练集中。
更糟糕的是,只能通过黑盒访问 GPT-2 ,可以提取逐字训练文本(例如 SSN)。还可以根据提取攻击从在临床语料库上训练的 BERT 中恢复个人健康信息(例如患者病情对)
差分隐私(DP)已成为保护个人隐私事实上的隐私标准,为了阻止 MIA 对个人训练数据的影响,可以使用 DP 随机梯度下降 (DP-SGD) 。
DP-SGD 可用来保护训练数据的隐私,对于 batch 中每个 sample 的 gradient 进行裁剪 clip,并对随机高斯噪声添加到聚合梯度中。但是,DP-SGD 通常需要一个可信方来管理用户的敏感数据。如果适用安全聚合来分布式完成,则会引入额外的开销和挑战。
研究表明,在中等隐私条件下,针对四项 NLP 任务微调 LM 的平均准确度为 65.7%(对比没有 DP 的情况下为 91.8%)。最后,推理时间嵌入不会受到训练期间添加的噪声的干扰,从而使推理查询容易受到各种恢复攻击,从敏感属性(例如作者身份)到原始文本。
1.1 Natural Privacy via Perturbing Embeddings
DP-Forward,扰动 forward-pass signals。用户在训练过程分享的时候,可以 locally inject noise into the embeddings of (labeled) sequences。而不是在 BP 的时候,在梯度上面加噪声。DP-Forward 可用于保护LDP,提供了更强的隐私保护能力。旨在提供可证明的本地 DP (LDP) 保证,从而抵御比 DP-SGD 更强大的对手
适用于 FL 设置,不去聚合用户的数据,而是共享重要的差异,通常是去噪声的 local model updates,LDP 具有 free post-processing 的作用,在这之后的计算,比如 gradient computation 不会导致额外的隐私问题。
如果用 DP-SGD 提供 LDP,需要添加几个数量级的噪声,可以保护隐私但是导致模型的不可用
DP-Forward通过给用户的测试序列 test-sequence embeddings 添加噪声,能够将其适用性扩展到推理,保证了训练过程的 LDP。能够高效的抵抗新兴的基于 embedding 的隐私泄露。
LDP(相对于 CDP)、更直接地保护原始数据(相对于梯度)免受新威胁
DP-Forward 的设计带来了 LDP (传统的是 CDP),相比于gradient,对 raw data 提供了更加直接的保护,需要对于训练或者推理过程的 embedding 添加 noises。
- Gaussian mechanism (GM) 高斯机制添加 i.i.d. noise,导出噪声作为实值和矩阵值函数。但是et,GM仅根据DP的充分条件来校准其噪声方差,其方差公式不适用于低隐私制度
- matrix-variate Gaussian (MVG)矩阵变量高斯,专为矩阵值数据而设计,它利用了可能的非独立同分布。来自矩阵高斯分布的噪声对更重要的行/列的干扰更少。但是这种方法需要的充分条件比较强。
基于 transformer 的 pipeline 包括: embedding layer, encodes, task layers.
为了确保 sequence-level LDP,我们需要估计任意两个序列前噪声函数的 L2-sensitivity。将函数输出标准化为 L2 范数,类似于梯度裁剪。
1.2 Contributions
关注于:LM在微调、推理过程中的 privacy concerns,以及 DP-SGD 固有的缺点
- DP-Forward fine-tuning 对于每个用户序列的 forward embedding 扰动,在扰动 aggregated gradients 方面提供了比 DP-SGD 更直接的保护。
- 为了实例化 DP-Forward,提出了 aMGM,适用于 matrix-valued function。
- 在3类经典的 NLP 任务中实验,探索超参数的影响。通过随机响应扰动标签,为序列标签对提供标准 LDP
- 都可以抵抗 sequence-level MIAs,但是只有 DP-Forward 可以抵抗 inference-time embedding。DP-SGD无法抵抗embedding inversion attacks
2 PRELIMINARIES AND NOTATIONS
2.1 Transformer Encoders in BERT
L 层的 BERT 模型,每个层又有两个子层,
- dot-product multi-head attention(MHA) with h heads
- a feed-forward network(FFN)
每个 sub layer 又有: - residual connection
- layer normalization
$X={i=1}^n$ 是 n 长 tokens 的序列。输入 embedding 层首先将每个 $x_i$ 映射到表征 $R^d$
使用 X 代表 hidden embedding matrix $R^{n\times d}$ ,对于在 MHA 多头注意力机制的 h,使用 $X$ 与 $W^Q,W^K,W^V\in R^{d\times d/h}$ 获取 query, key, value matrices $Q,K,V\in R^{n\times d/h}$ ,输出为: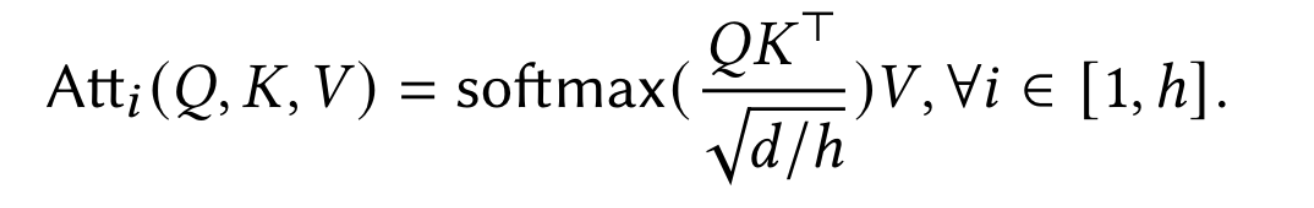
softmax() 的输入是 $n\times n$ 的矩阵,然后 MHA 将所有的 head outputs 拼接为一个矩阵 $R^{n\times d}$ ,然后右乘一个映射矩阵 $W^O\in R^{d\times d}$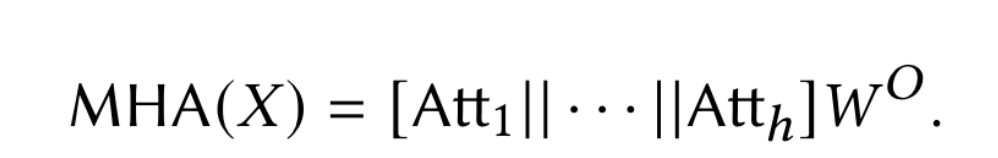
FFN 前向传播神经网络由两个线性映射与 ReLU激活函数组成,其中 $W_1, W_2,b_1,b_2$ 是可训练的矩阵或者向量参数。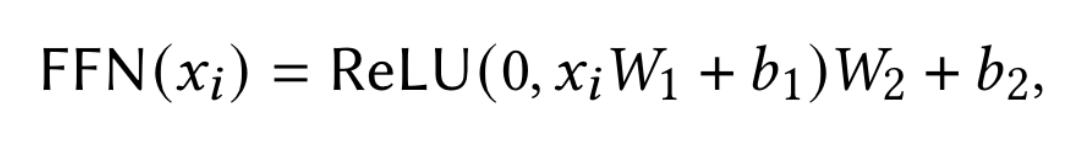
FFN 在 X 上的输出可以表示为: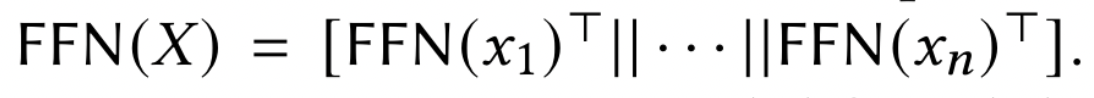
子层的残差连接可以表示为: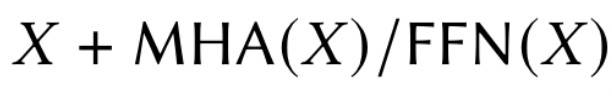
层归一化 $LN(x_i)$ 对所有的 $x_i$ 归一化,使用额外的缩放使得具有零均值和单位方差。
在最后一个 Encoder 的输出, hidden embedding matrix 被缩小为一个序列特征 $R^{1\times d}$ ,标准的缩小方法是 mean pooling. $\sum{i=1}^n x_i/n$
预训练的 BERT 模型基于两种监督任务,masked language model (MLM) 掩码语言模型, next sentence prediction 下一个序列预测。
本文采用的是 MLM,随机对一些 tokens 掩盖,目标是根据上下文信息来最小化交叉上损失,预测这些被掩盖的位置的 tokens。$\theta$ 是 BERT 模型的参数。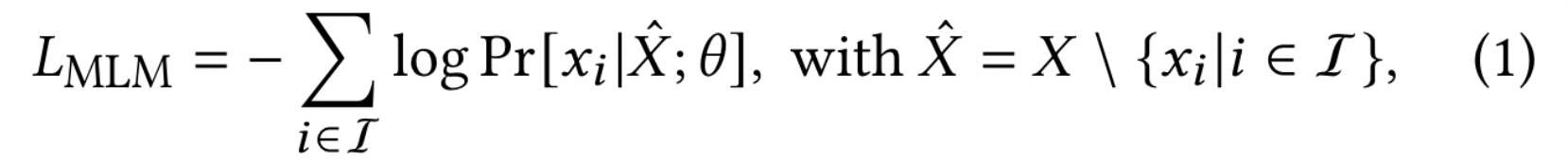
2.2 (Local) Differential Privacy
DP 是一个严格的、可量化的隐私概念。有两种流行的模式:集中模式和本地模式。在中心化 DP 中,可信数据管理者访问所有个体原始数据的集合 X,并通过带有一些随机噪声的随机机制 M 处理 X。
neighboring,涉及“替换”关系:$X’$ 可以通过替换单个个体的数据点(例如,序列标签对)从 $X$ 获得。
对比之下,LDP 移除了可信机构,允许参与者在本地使用扰动机制 $\mathcal{M}$ 对数据进行扰动。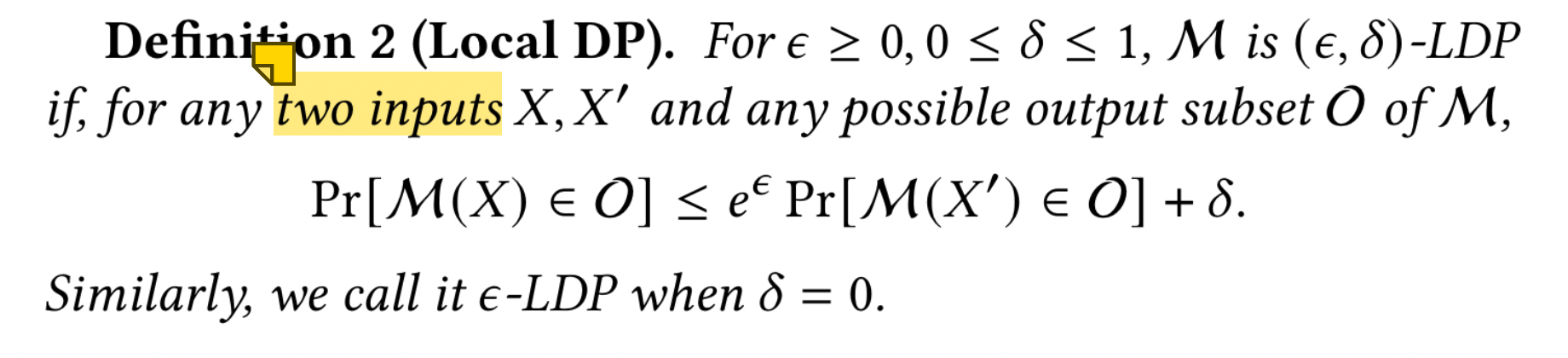
Privacy Loss Random Variable (PLRV)隐私丢失随机变量,通过观察输出 O 引起的隐私损失(或“实际 ε 值”)是两个概率的对数比: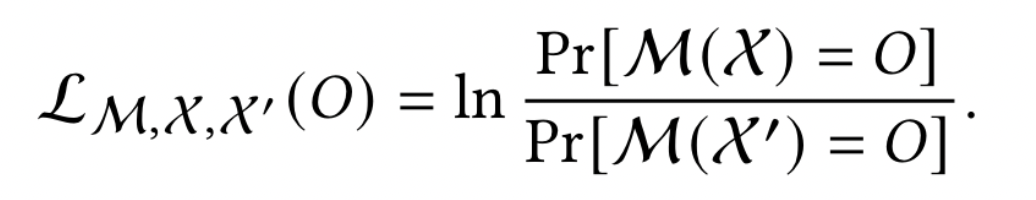
当 O 根据 M (X) 变化时,我们得到 PLRV $L_{M,X,X’}(O)$。使用 DP 的一个有用方法是分析 PLRV 的尾部边界
DP 具有两个特性:
- free post-processing
-表明在 $(\epsilon,\delta)$-DP 机制的输出上进行的计算不会造成额外的隐私损失。 - composability
-允许我们在简单的方式上构建更复杂的机制,在同一输入上顺序运行 (ε, δ)-DP 机制 k 次至少为 (kε, kδ)-DP
matrix-valued function 矩阵值函数 $f:\mathcal{X}\rightarrow R^{n\times d}$ 的输出扰动机制 ,在输入上计算 f,然后将从随机变量中提取的随机噪声添加到其输出。
对于 $(\epsilon,\delta)$-DP ,一个典型的实例 $M$ 是经典的 GM 高斯机制:对每个条目 i.i.d 添加噪声 Z ∈ $R^{n\times d}$,从单变量高斯分布 $\mathcal{N}(0,\sigma^2)$中得出

3 DP-FORWARD
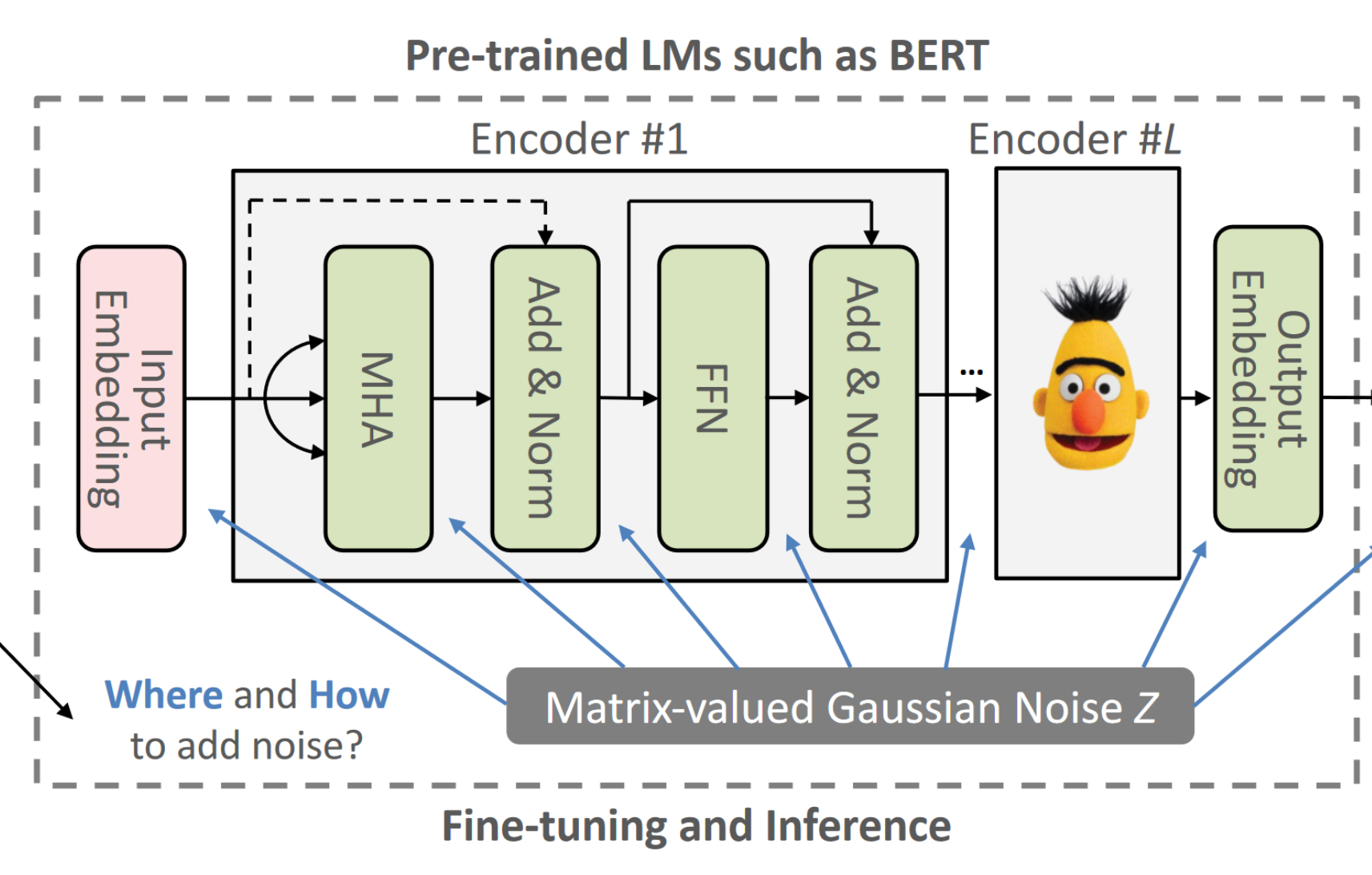
我们以基于 BERT 为例进行研究,因为它们在分类任务中表现出色。DP-Forward 可以轻松应用于其他(基于转换器的)NLP 或计算机视觉模型,这些模型在前向传递过程中涉及矩阵值计算。
假设每个用户持有一个序列标签对 (X, y) 或仅持有 X,用于在不受信任的服务提供商处微调或测试。共享经过编辑的 X(删除了公共 PII)或其功能(非人类可读的实值嵌入矩阵)存在漏洞。
对于 DP-Forward 训练,用户在本地扰动他们的嵌入矩阵,以在共享之前确保 LDP(的新概念),并且如果认为敏感,他们还应该扰乱相应的标签。我们在第 3.2 节中探索了将管道拆分为前噪声函数 f (·) 和后噪声处理 p (·) 的不同选项:用户可以访问 f (·) 来导出嵌入矩阵,并通过输出扰动机制 M 进行扰动(例如,GM);服务提供商在噪声(标记)嵌入上运行 p (·) 以进行微调(第 3.3 节)或预训练(第 3.6 节)。挑战在于分析不同管道部分的 $S_2(f)$
我们通过标准化 f (·) 来解决这个问题。与 DP-SGD 不同,DP-Forward 可以自然地用于保护推理序列。它利用免费的后处理(即,对噪声嵌入进行推理),通过额外的“即插即用”噪声层对管道进行最小的更改。
3.1 Notions of Sequence (Local) DP
嵌入$f(X)$对输入序列 X 的语义信息进行编码,每个序列都有 n 个tokens(第 2.1 节)。NLP 管道的微调(或后续推理)本质上是处理 $f(X)$。DP-Forward 微调通过 f (X ) 上的输出扰动机制 M 来保护每个 X,这与 DP-SGD 不同,DP-SGD 扰动 X 上的梯度 $f’(X,y)$ 和标签 y 的聚合。简而言之,我们的 (ε, δ)-LDP 对于 X 成立,而 DP-SGD 为 (X, y) 提供 CDP。
仅序列保护 Sequence-only protection 是有意义的,因为序列通常传达(隐式)敏感信息(例如作者身份),而标签(例如表示正/负的单个位)labels 可以是公开的。
在中心化的设置中,定义 DP(SeqDP)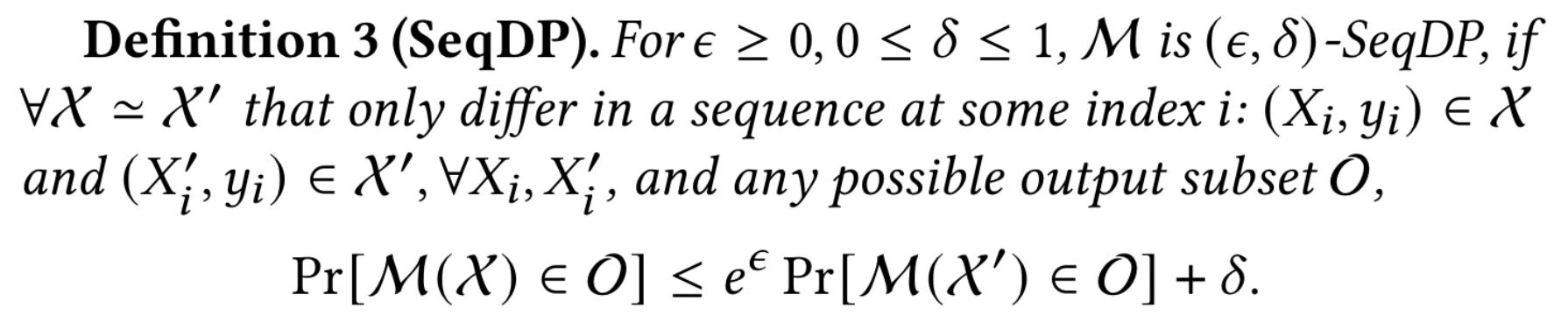
3.1.1 Label DP
最近提出的标签 DP 的概念最初是在 PAC 学习中研究的。它仅保护标签(而不是相应的输入/图像):(ε, δ)-DP 仅适用于标签。
我们的 SeqDP 比 label DP 更“安全”,或者至少“补充”了 label DP,后者有一个固有的缺陷:由于标签通常依赖于它们的序列(但反之亦然),因此很可能从原始序列中恢复真实标签,即使标签受到保护(通过任何 label-DP 机制)
后续研究表明,当模型泛化时,即使任意小(ε,δ),label DP 下的标签保护也是不可能的。此外,标签可能不存在(例如,推理或自监督学习),为此 SeqDP 升级到标准 (ε, δ)-DP,而标签 DP 根本不适用。
3.1.2 Sequence Local DP (SeqLDP)
我们进一步定义了 SeqLDP,它是序列 DP 的本地对应部分。请注意,上述与 SeqDP 相关的label DP 的讨论也适用于 SeqLDP。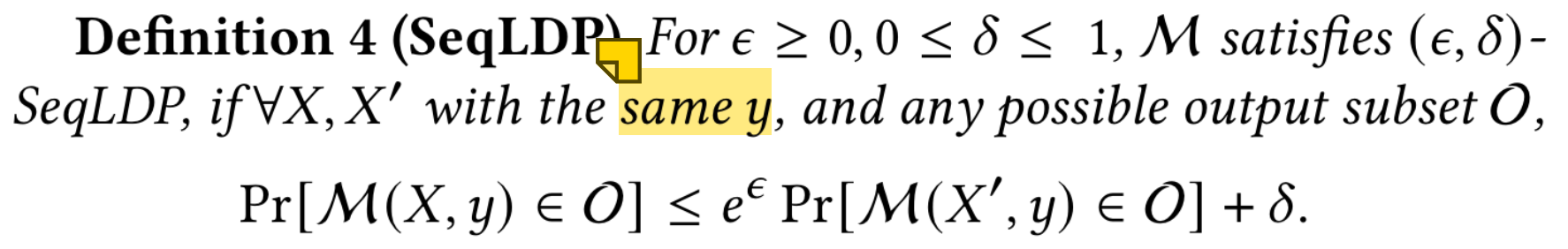
理论上,SeqLDP 仍然是一个强大的概念(就像标准 LDP 一样)。它旨在对序列进行信息论保护,并限制任何 X, X ‘(最多相差 n 个标记)的不可区分性,从而控制噪声嵌入的“有用性”。
3.1.3 Sequence-Level SeqLDP vs. Token-Level SeqLDP.
为 SeqLDP 获得有意义的 ε 范围是一项斗争。将高斯噪声添加到 (ε, δ)-SeqLDP 的 f (·) 输出需要限制 L2 灵敏度 $S_2(f)$, ∀X, X ′。我们的方法是标准化输出,类似于 DP-SGD 中的剪切梯度。当 f (·) 具有更多层(在 ε 的相同有意义范围内)时,它通常效果更好,因为 p (·) 受噪声输出“影响”的(可训练)参数/层较少。
不幸的是,当 f (·) 包含前几层时,例如,只有输入嵌入层可供用户使用(例如,为了节省用户端存储和计算开销),它会导致实用性较差。我们利用 Lipschitz 常数(的组成)进行行归一化,以保持这些情况的实用性。与一般标准化相反,它的目标是在令牌级别上较弱的 SeqLDP,“保护层次结构”中的更细粒度,保护任何相邻序列(相对于数据集)任何单个标记(相对于序列)都不同。
3.2 Our Approach for Sequence LDP
DP-Forward 将通用归一化方法应用于序列级 (Seq)LDP 的任意 f (·)
令 f (·) 为任意深度的前向传递,范围从第一个(输入嵌入)层本身到基于 BERT 的管道中除最后一个层之外的所有层。相应地,令 p (·) 为剩余层,范围从最后一个任务层本身到除第一个(输入嵌入)层之外的所有层。每个序列 X 都成为编码器层输出处的嵌入矩阵 f (X ) ∈ $R^{n\times d}$或任务层之前的 $R^{1×d}$。为了提供 (ε, δ)-SeqLDP,考虑到数据集只有一个标记序列,我们采用了一种合适的输出扰动机制 M,例如 GM。
M 可以作用于任何隐藏层的输出,因此估计 $S_2(f)$ 并不简单。具体来说,MHA 本身不是 Lipschitz 连续的,更不用说包含更多层了,这意味着即使输入变化很小,它的输出也可以任意改变 。为了解决这个问题,采用标准化或裁剪函数输出: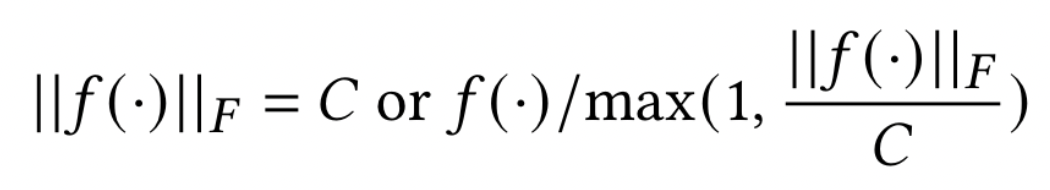
在实验中采用标准化。然后可以校准高斯噪声 Z 并导出后噪声层 p (·) 的 f (X ) + Z
注意,我们在向第一个 MHA 层的输出添加噪声时删除了残余连接,以避免 p (·) 重新访问 X以保持自由的后处理。这可能会导致不稳定(例如梯度消失),但可以通过预训练新的 BERT 来缓解这种情况,而无需这种残余连接,以与以后的微调/推理保持一致。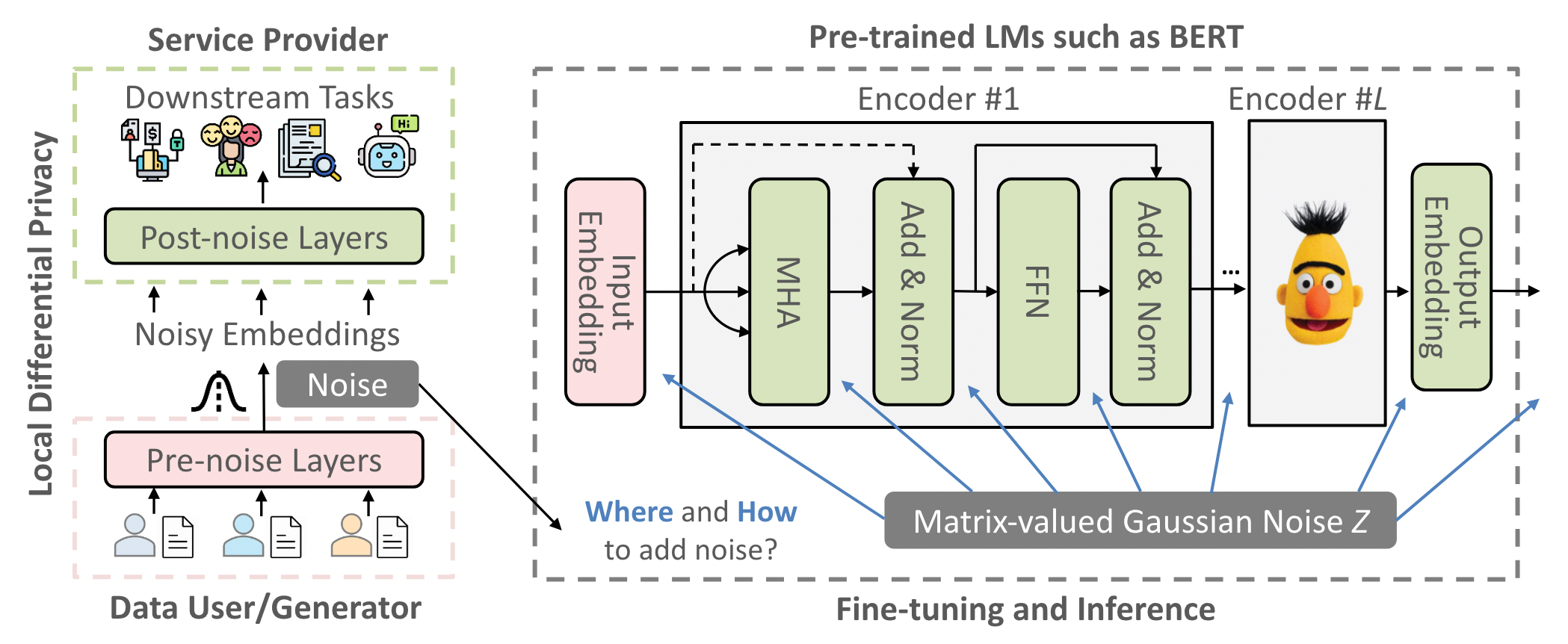
当 d 很大时(例如,BERT-Base 为 768),使用 GM 的 DP-Forward 会遭受“维数灾难”。为了减轻诅咒,我们可以附加两个线性映射,M1,M2 ∈ $R^{d ×d′}$,其中 d′ ≪ d,使得 f (·) 和 p (·) 分别具有 M1 和 M2。与其他使用梯度的权重一样,这两个映射都是随机初始化和更新的。在归一化之前,原始嵌入矩阵首先右乘 M1,得到 Rn×d’ 或 R1×d’ 。我们的隐私保证不会受到影响,因为 S2 (f ) 保持不变。然后我们使用 M2 恢复维度以与原始管道兼容;由于免费的后处理,M2 不会造成额外的隐私损失。然而,管道的改造还需要付出很大的努力;降维嵌入矩阵也可能会丢失有用的信息,从而降低任务效用。因此,我们将 M1 和 M2 设为可选。
3.3 DP-Forward Fine-tuning
假设我们使用原始的公共 BERT 进行微调。在第 i (i ≥ 1) 步骤的前向传递中,它向一批用户提供最新的 $f ^{(i−1)} (·)$,模仿常规小批量 SGD。 f (0) 来自原始检查点。用户是随机选择的(无替换),其数量是固定参数。批次中的用户单独计算其噪声嵌入 $f^{ (i−1)} (X ) + Z$ 以确保 SeqLDP(定理 1)。然后,他们将带有不受干扰的标签 y 发送给服务提供商,服务提供商在 ($f ^{(i−1)} (X ) + Z, y$) 上运行 $p^{ (i−1)} (·)$ 来计算批次损失; SeqLDP 下嵌入的任何后处理不会导致 X 上的额外隐私退化。 p (0) 这里包括其余的原始 BERT 部分和随机初始化的任务层。
在反向传播期间,服务提供者可以通过后噪声层的梯度(从损失和噪声嵌入导出)将 $p ^{(i−1)} (·)$ 更新为 $p ^{(i)} (·)$。为了避免访问用户的原始 X ,需要将前噪声层 $f ^{(i−1)} (·)$ 冻结为 f (0) 。参数冻结与最近的零样本或上下文学习范式兼容。当模型巨大且全面微调成本高昂时,它非常有用。然而,冻结的层数越多,实用性可能越差(即使在非私有设置中)
有两种安全更新 $f ^{(i−1)} (·)$的通用方法: i) 我们可以假设一个额外的可信方(如 DP-SGD 中),但它成为中心 DP。 ii) 用户可以首先在其 X 上本地导出 $f^{ (i−1)} (·)$$ 内部各层的梯度,然后在服务提供商处采用安全聚合。 进行全局更新。然而,它的成本很高。为了更好的实用性,我们在实验中更新 $f^{(i−1)} (·)$,要求我们考虑由于可组合性而导致的不同时期的隐私退化(如下详述)。专用方法(平衡效率、隐私和实用性)留作未来的工作。
Privacy Accounting
Epoch 是指私人训练语料库的整个传输。每个 X 在每个时期使用一次。时期数 k 是一个超参数,通常很小。在同一个 X 上重复应用 GM 需要估计由于可组合性而导致的整体隐私损失(除非冻结 f 以重新使用 f (X ) + Z )。 Gaussian DP 提出了一种基于中心极限定理的方法。然而,它会导致下限被严重低估。相反,我们求助于最近的数值,它通过将真实的总体 ε 近似到任意精度来优于 RDP 或 GDP。它通过截断和离散 PLRV 及其由 FFT 卷积的 PDF 来构成机制的隐私曲线 。
3.4 DP-Forward with Shuffling versus DP-SGD
离散标签扰动。对于大多数 NLP 任务,例如 GLUE 基准中的二元/多元分类,大小 |y|标签空间通常很小。针对离散数据的一个简单而有效的解决方案是几十年前提出的随机响应(RR)具体来说,RR 扰乱真实标签 y 的概率为$\hat y$ = y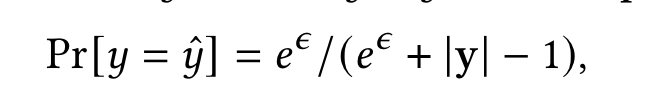
当|y|时较大时,我们可以使用之前的“修剪”y 使其更小 y′ 。先验可以是公开的(例如,类似于用户数据的辅助语料库),也可以通过多阶段训练从均匀分布中逐步细化。然后我们可以估计一个最佳|y′|通过最大化输出正确的概率,即 Pr[y = ˆ y]。通过(事先辅助的)RR ,我们可以实现完整的 LDP。
Experiment
5.4 DP-Forward versus DP-SGD
研究 DP-Forward 的 8 个实例:
- 对 input embedding layer 进行扰动
- 对 6 不同对 encoder 扰动
- BERT Output
在 3 类 tasks 的 3 类 privacy levels 评估准确率,同时添加了 DP-SGD 以及 non-private baseline
如Table 5所示,在每个任务中大概有一半或者更多的实例准确率比 DP-SGD 好。QQP 的最大准确度增益为 ∼7.7pp。
添加噪声的 output embedding 由于在 the last encoder output 通过 dimension reduction ,通常能够得到最优的准确率,甚至能够与 non-private baseline 相比
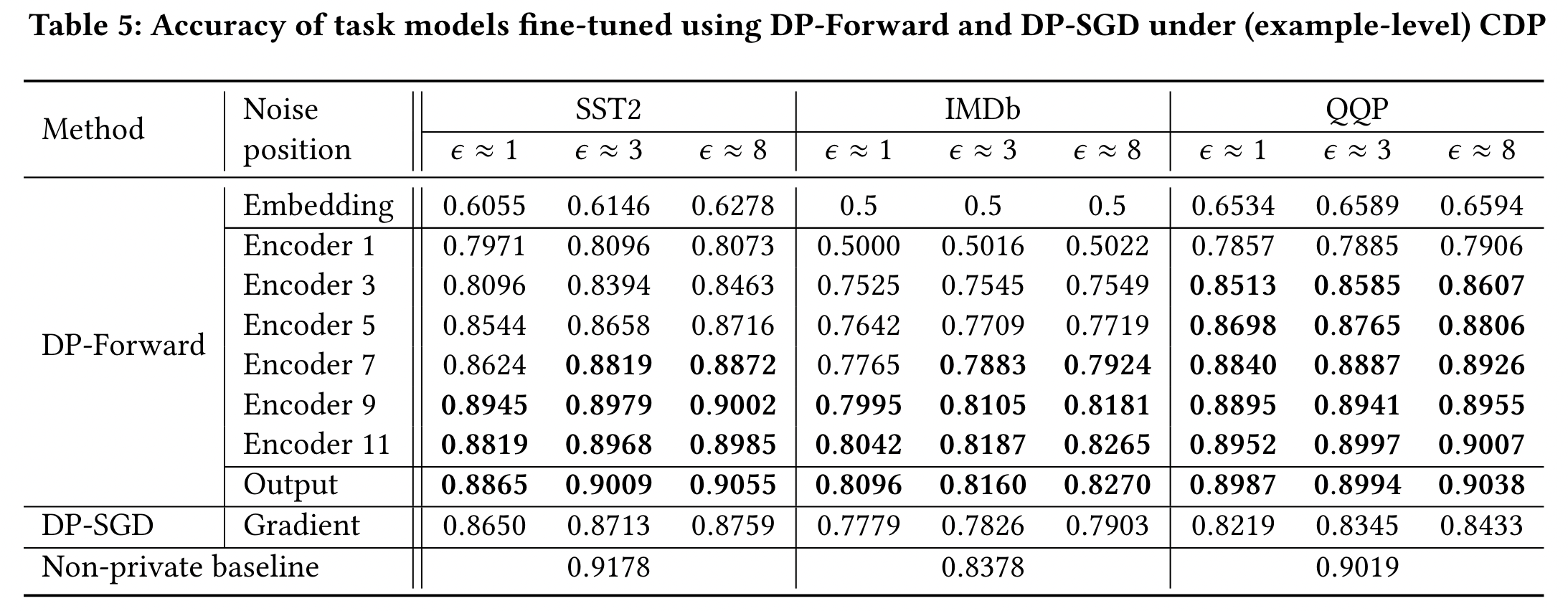
最近关于 DP-SGD 的变体通过对部分梯度进行扰动,使用了类似 low-rank adaption 的 trick。在 SST-2 和 QQP 数据集上分别能够达到 92.5%,85.7% 的准确率,只比 non-private 的 baselines 降低了2.3pp 和 6.2pp 。DP-Forward 在两类任务中导致准确率下降不到 1.7pp,($\epsilon=3$),尽管他们的方法使用了 RoBERTa-base,一个对于BERT方法使用了更多的训练数据集、更多的训练时间、更好的训练技巧(例如MLM 的动态掩码)更优的模型,我们提出的 DP-Forward 仍然优于以上改进。
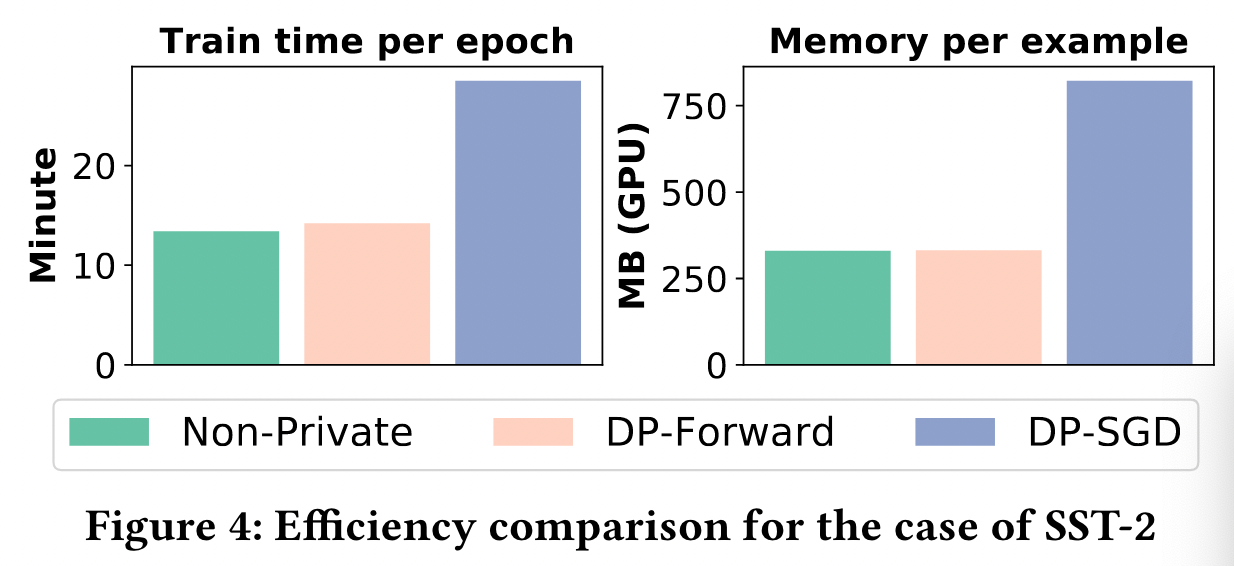
图4展示了在微调SST-2数据集上的效率对比。我们的方法的时间和存储开销与 non-private baseline 几乎相同,并且比 DP-SGD 小 3 倍,因为我们允许在正常微调过程中执行批处理,而不需要处理每个 sample 的 gradients。同时,我们的归一化和 noise sampling/addition 也更快,因为 embedding 的 size 小于 gradients 的大小。
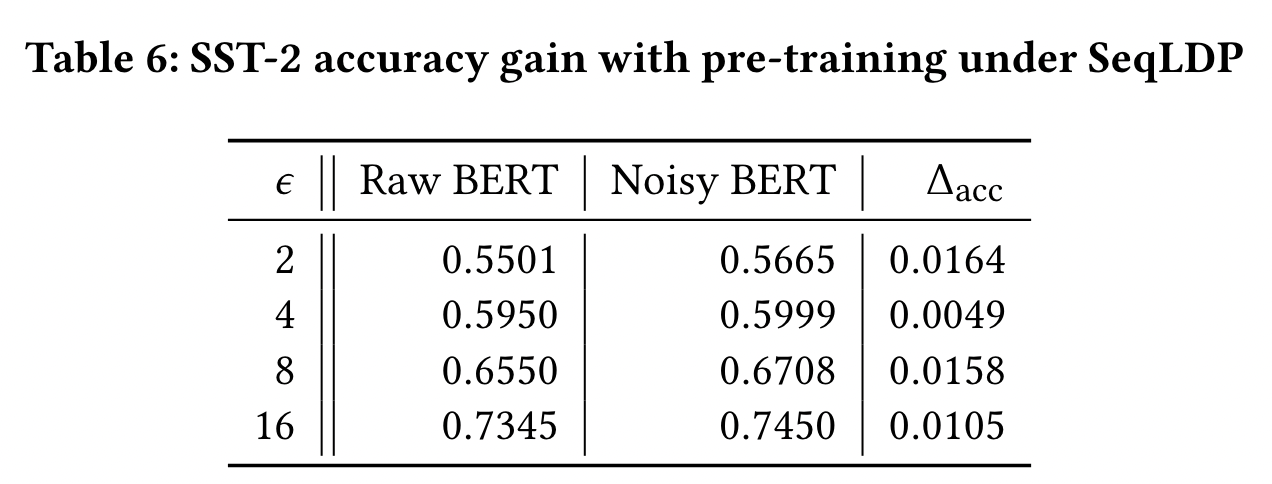
5.5 Noisy Pre-training
使用 DP-Forward 预训练 BERT,与噪声微调保持一致,确实有助于准确性
我们使用 SST-2,对其输入的 embedding matrices 扰动,在 English WikiCorpus 数据集(2006 dump,600M words)上继续对 BERT pre-training 一个 epoch。
如表6,与直接在原始的 BERT 上进行微调相比,对于大多数的 $\epsilon$ 我们可以获得 1-2pp 准确率的提升
6 Defense against privacy threats
我们研究了MIAs 和 两种新的从 embeddings 导致 sequence leakage 的威胁
- embedding inversion
- attribute inference
6.1 Threat Models
对于 MIAs,我们按照之前的考虑只有黑盒访问能力的敌手:即可以查询目标 sequences 的 prediction results(例如每个类的概率),但是不能获取权重和网络架构(例如hidden embeddings)
尽管对于 embedding 的 inverting 或者 inferring 有不同的目标,我们考虑通用敌手的威胁,只能黑盒访问训练的部分 $f()$
可以获取目标 sequences 的 inference-time (clear/noisy) embeddings。可以获取 public prior knowledge,收集有限的辅助数据集 $X_{aux}$ ,与目标共享相似的属性。
DP-SGD 只为 training data 提供 CDP,不会保护 inference-time input。
DP-Forward 能够在 training-time and inference-time抵抗更强大的敌手
6.2 Membership Inference Attacks
Attack Objective
MIAs 是预测一个数据值是否在训练集中,通常是探索 training data 和 unseen data 之间的差异 (例如,poor model 由于过拟合,泛化能力差)
通常的成员推理是在 token/word级别的(考虑一个滑动窗口内的 tokends),DP-Forward 考虑更现实的整个句子的MIAs (例如,通过黑盒访问 GPT-2 逐字提取预训练序列)
之前的方法表明,使用预测置信度或者熵以及适当假设的基于门限的MIAs与基于 shadow training 的复杂度相当。
将基于置信度的 MIA 适应我们方法,最小化其预测损失来进行微调:将训练序列预测为其真实标签的置信度/概率应接近 1。当$\mathcal{F}$ 输出的预测标签 $l$ 的置信度大于预设阈值 $\tau$时,敌手可以推理出一个候选的序列 $X^*$ 作为一个成员
$1{\cdot}$ 是指示函数,所有可能的 label evaluation 中使用的 $\tau$ 都是一个固定的值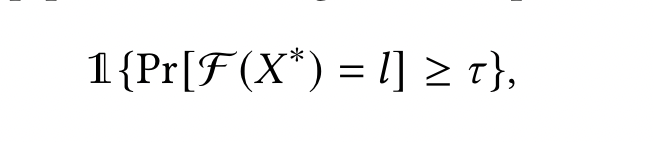
第二个 MIA 是基于一个训练序列向量的预测的输出值(例如概率向量),往往是一个 one-hot 向量,熵接近于 0。
对于所有可能的 label $l_i$ ,当预测的熵小于预设的门限 $\tau$,敌手可以推断 $X^*$ 是一个成员。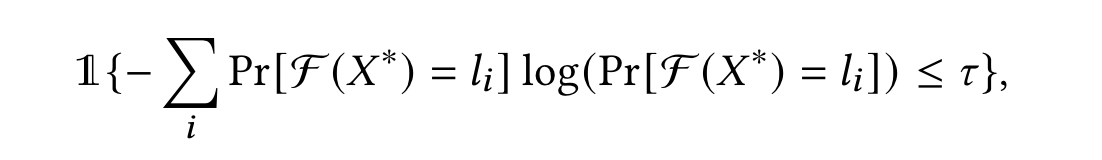
Numerical Results
所有的 test examples 和 a random subset of the training examples(与 test ones 数量相同)被均匀地划分为两个子集,一个用于寻找最优的 $\tau$,一个用于测试攻击的成功率。
我们随机drop/replace 测试集的 tokens,来扩大预测的差异性,使 MIAs 更容易。
我们在 SST-2 通过 non-private, DP-Forward, and DP-SGD 微调的微调,评估基于 MIAs 的置信度和熵。
对于DP-Forward,我们评估5类扰动:
- input embeddings
- three encoders’ outputs
- output embeddings
如表7, DP-Forward 和 DP-SGD可以有效缓解 MIAs,MIAs’ 成功率在 DP-Forward 的更深的层会减小到 0.5(类似于随机猜测),在相同的隐私水平下($\epsilon$),优于DP-SGD 6pp 以上。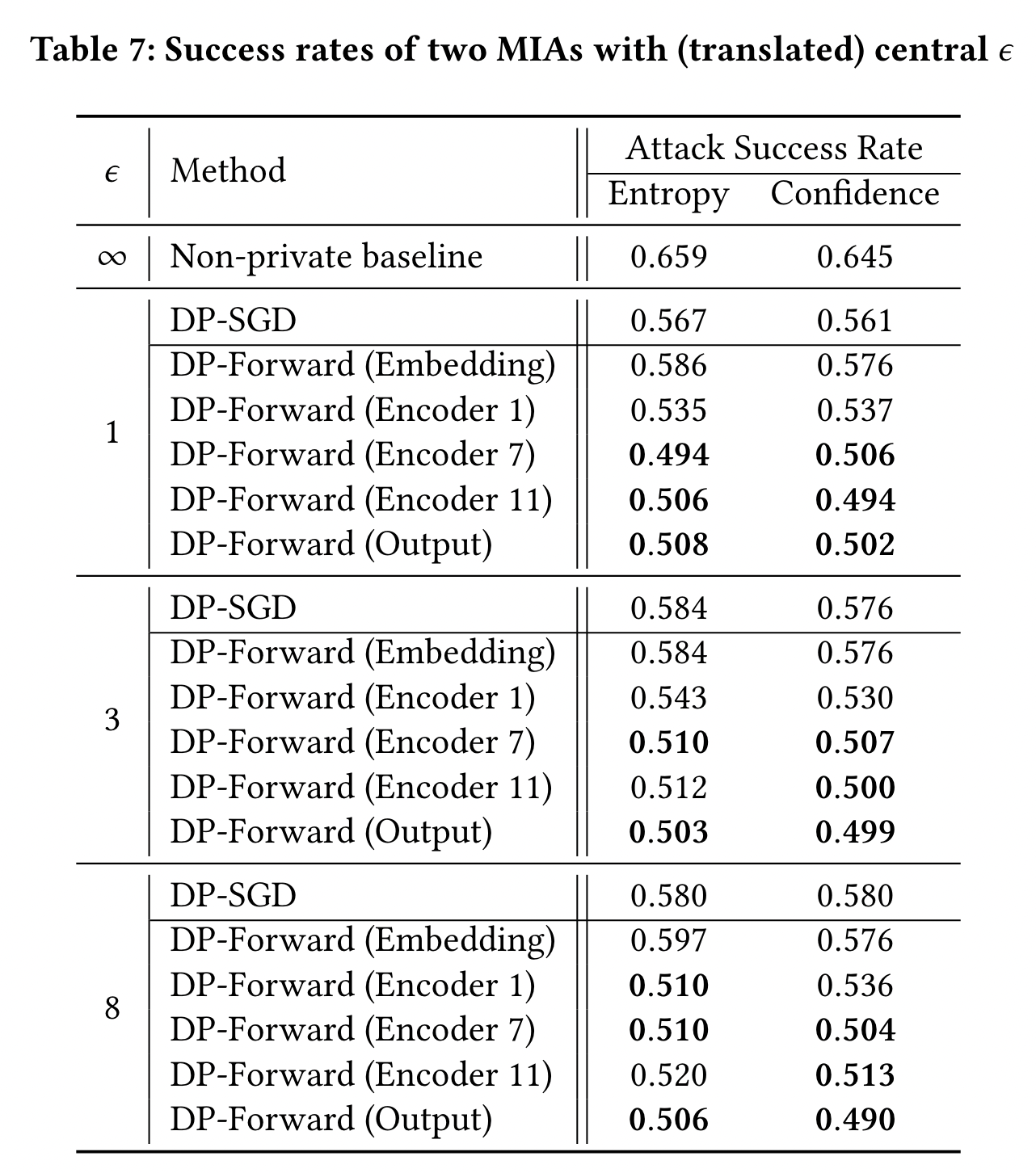
6.3 Embedding Inversion Attacks
Attack Objective
这些攻击旨在从 embedding 恢复 raw text 无标记的 tokens ${x_i}_{i\in[n]}\subset X$ , 表示直接共享未添加噪声的 text embedding 用于训练和推理会带来很大的风险,已经被用来重构一些身份代码或者基因片段。
首先,提出 token-wise 的 inversion attack,来 invert 输入 embedding layer $\phi(\cdot)$ 的 noisy token embeddings,将 $\mathcal{V}$ 中的每个 token 映射到 $\mathcal{R}^d$
$z_i$ 是noise $Z$ 的 $i^{th}$ 行,通过 $\mathcal{V}$ 上的最近领搜索,返回的是 $x_i^*$ ,$x_i^*$ 的 embedding 是最接近 $x_i$ 的 embedding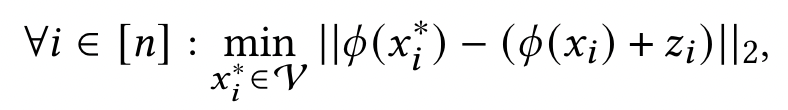
对于 deep layers 的 token hidden embedding,编码了整个序列更多抽象的信息,因此 token-wise inversion 难以发挥准确,即我们需要一个更加通用的攻击方法
首先对 noisy embedding 通过一个线性的平方模型 M 映射到一个 lower-layer ,然后选择 n tokens 作为 $X^*$ 来最小化 $X^*$ 较低层的表征与从模型 M 得到的 $L_2$ distance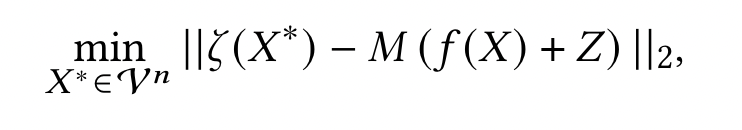
以上的最小化针对的空间是 $|\mathcal{V}|^n$ ,大于 token-wise 的空间
每个位置 $i\in [n]$ 通过连续向量 $R^{|\mathcal{V}|}$ 放缩,输入到 softmax 函数,来建模每个 token 的选择概率
通过将一个向量(每个 entry 是一个权重)和原始的 embedding matrix 相乘,得到 token embedding $x_i^*$
Numerical Results
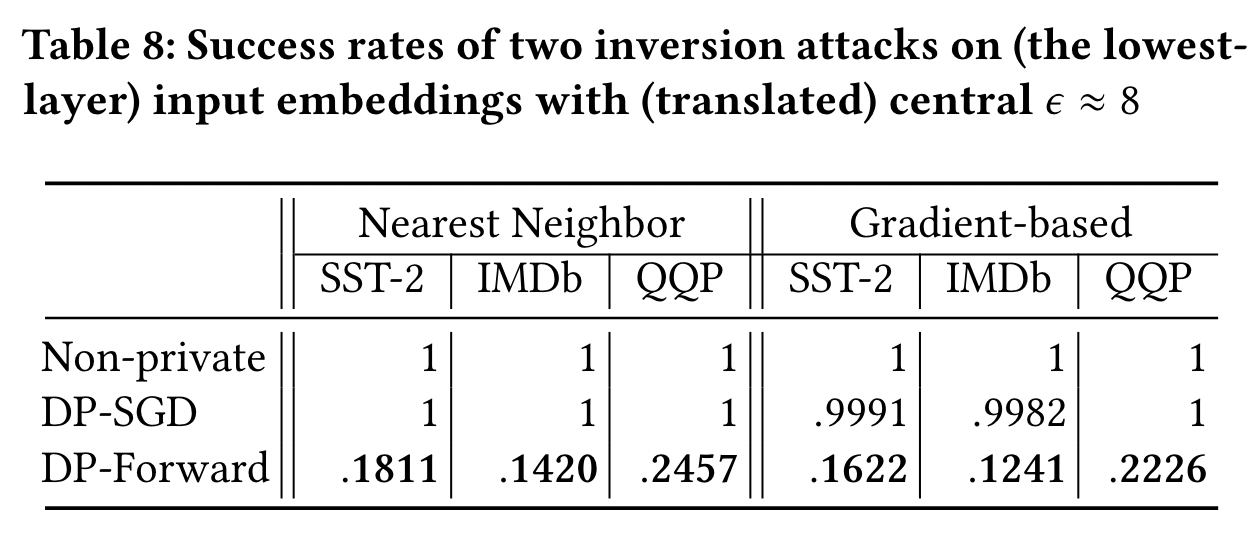
基于梯度的攻击可以在 lower-layer 实现对 clear embedding 较高成功率的攻击(recall)
DP-Forward 通过如下两种攻击方式:
- nearest-neighbor
- gradient-based
通过 public BERT embedding 的查找表这个先验知识,来反推 input embeddings
如表8,DP-Forward 可以将攻击的成功率减小到一个小于0.2的水平,DP-SGD 防御失败。DP-Forward 直接向 embedding 添加 noise,缓解 embedding inversion
DP-SGD 只对 gradients 扰动,对于测试序列的 inference-time embedding 没有提供保护
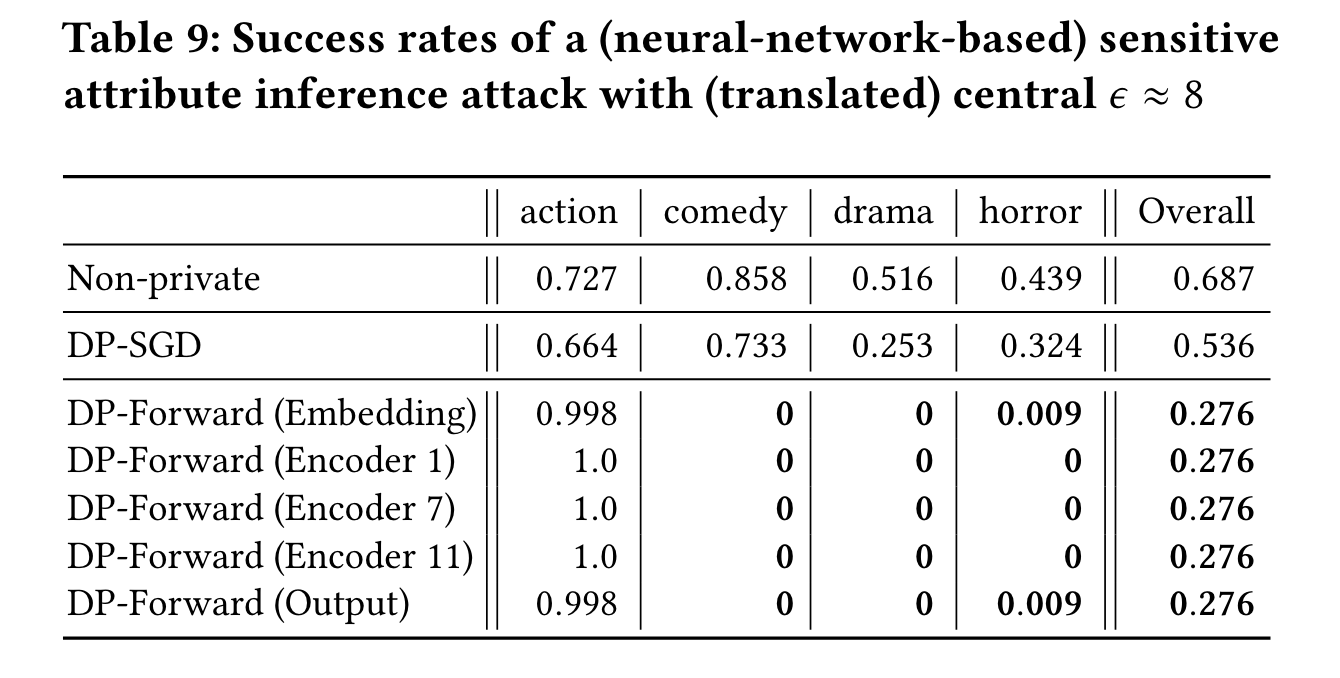
6.4 Sensitive Attribute Inference Attacks
Attack Objective
除了精确恢复 tokens,从 embedding 中推理目标序列的敏感属性。
假设 $X_{aux}$ 是有敏感属性的序列标签,敌手通过查询 $f(\cdot)$ 得到 noisy/clear embeddings.
$S$ 是所有可能的敏感属性的集合,例如作者身份。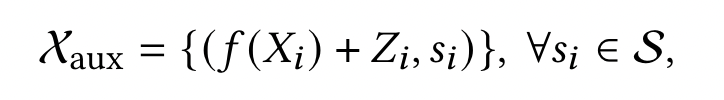
敌手通过 $X_{aux}$ 监督学习,训练一个分类器,使用分类器对于 noisy/clear embedding $f(X^*)+Z$ ,来预测$X^*$ 的 $s^*\in S$
Numerical Result
训练一个3 层神经网络,一个线性头作为分类器,来输出电影类型(例如,恐怖片),从一个影评中通过 output embedding推测敏感属性。
我们使用了 IMDB 的 20k 的样本(90%训练集,10%验证集)作为$X_{aux}$ ,SST-2提供3.3k样本的测试集作为分类器。
DP-Forward 的5类,抵抗 attribute inference 较好。
DP-SGD 仅比 non-private baseline 减小了一些成功率
因为 DP-SGD 的 noisy embedding 仍然会损失一些信息
7 Related Work
7.1 Privacy Threats on LMs and Embeddings
即使敌手是黑盒查询预言机的模型,LMs 在 hidden/output text embedding 隐私泄露也很严重
- embedding inversion (甚至可以部分恢复 raw texts)
- membership inference
- inferring sensitive attributes(例如从 embedding 推理作者信息)
其他的研究考虑 LMs 对于 training data 的记忆(成员推理攻击)
如果一个字符串在最多 k 个例子中出现过,那么它就是可提取或可记忆的,甚至对于只出现过一次的 name,也能恢复出来。k越低,说明隐私泄漏越严重。结合 DP 来解决记忆问题是一个很有前景的解决方案。
7.2 Input (Text/Feature) Perturbation for LDP
通过LDP合成词频(特征)向量,与序列 embedding 相比应用有限。提供 sequence-level 的保护:Laplace 或者指数机制对 LM 提取的 sentence embedding 进行扰动,可以均匀地保护整个句子。对于不同的 hidden embedding 的扰动,而不是 token 或者 sentence 探索较少
7.3 DP-SGD (Variants) in Training LMs
由于 dimensionality 诅咒,DP-SGD在预训练或者微调大模型时候,导致了显著的效率和准确率的下降。
Yu 等人提出重参数化梯度扰动。首先,重参数化或者分解每个 high-rank 高阶权重矩阵为两个低阶(梯度载波)矩阵,通过扰动低阶梯度来减轻维度诅咒。加噪声后的低阶梯度最终被映射更新原始的高阶权重。
在每次更新时,对每个权重应用这种重参数化的方法是仍然开销较大的,并且可能导致不稳定性(噪声在映射的过程中会被放大)
之后的工作建立在参数高效的微调上, 例如 LoRA,Adapter,Compacter。通过非常少量的附加插件的参数进行扰动。
但是有工作表明,这种方式的微调不一定比完整的微调效果好,他们提出 ghost clipping,一种节省内存的技术(与降维方法正交),在完全微调中使用DP-SGD,不需要实例化每个实例的梯度。尽管这些方法可以在效率和准确率上有所提升,但是这仍然只是通过扰动较小的梯度来保护训练数据。
7.4 DP Mechanisms for Matrix Functions
Gaussian 或者 Laplace 机制都是适用于标量或者向量函数,对输出矢量化,并添加独立同分布的噪声,可以将其推广为矩阵值函数。但矩阵函数的结构信息没有被利用。
MVG 机制,绘制定向或者non iid的来自矩阵高斯分布的噪声。它将更少的噪声注入更多“信息丰富”的输出方向以获得更好的效用,仅对两个协方差矩阵的奇异值之和(确定噪声幅度)进行约束。
仍有致力于有限的矩阵值函数的机制。矩阵机制考虑由查询矩阵的 W 和输入向量 x 的Wx来表示。仍然采用加法 Laplace 或者 Gaussian 噪声,但通过额外的变化来解决噪声 $Wx$ 的最小方差估计。
另一项最近的研究重点关注仅具有二进制(矩阵)输出的矩阵值查询。然后,它设计了一种异或 (xor) 机制,对输出与归因于矩阵值伯努利分布的噪声进行异或。
8. Conclusion
预训练的 LMs 成为 NLP 任务的关键,但是微调语料库或者推理时间的输入面临各样的隐私攻击。
DP-SGD 通过给梯度添加噪声的方式,为训练数据提供有限的保护。训练数据或者推理数据的原始 tokens 或者敏感属性可能会在前向传播的 embeddings 中被泄露。Vanilla DP-SGD 还带来的较高的 GPU内存和计算负担,无法批处理。
DP-Forward 在前向传播过程中,直接对原始训练或者推理的数据的 embeddings 矩阵添加噪声,核心是解析矩阵高斯机制analytic matrix Gaussian mechanism,以专用方式从矩阵高斯分布中提取最佳矩阵值噪声。
在多个层的不同位置对 embeddings 扰动的优点:
- DP-Forward 用户只需下载导出 noisy embeddings 的部分,比获取 noisy gradients 在存储和时间上高效。
- 在清除输入文本标记和句子嵌入方面,提供一整套前向传播的信号选项
除了两种DP机制在理论上面的贡献以及与baseline实验的对比,在3类NLP任务上,研究了关于可重复验证的 DP-Forward 超参数的配置
我们的方法提供了一种更好的隐私意识的深度神经网络训练,对传统的关注于梯度的方法提出了挑战。作为本地 DP 微调和推理的新范式,我们的工作为新的机器学习隐私研究的无数可能性铺平了道路,例如,推广到基于 Transformer 的计算机视觉任务。

