When Foundation Model Meets Federated Learning: Motivations, Challenges, and Future Directions
Metadata
- Tags: #Foundation-Model #Survey
- Authors: [[Weiming Zhuang]], [[Chen Chen]], [[Lingjuan Lyu]]
Abstract
The intersection of the Foundation Model (FM) and Federated Learning (FL) provides mutual benefits, presents a unique opportunity to unlock new possibilities in AI research, and address critical challenges in AI and real-world applications. FL expands the availability of data for FMs and enables computation sharing, distributing the training process and reducing the burden on FL participants. It promotes collaborative FM development, democratizing the process and fostering inclusivity and innovation. On the other hand, FM, with its enormous size, pre-trained knowledge, and exceptional performance, serves as a robust starting point for FL, facilitating faster convergence and better performance under non-iid data. Additionally, leveraging FM to generate synthetic data enriches data diversity, reduces overfitting, and preserves privacy. By examining the interplay between FL and FM, this paper aims to deepen the understanding of their synergistic relationship, highlighting the motivations, challenges, and future directions. Through an exploration of the challenges faced by FL and FM individually and their interconnections, we aim to inspire future research directions that can further enhance both fields, driving advancements and propelling the development of privacy-preserving and scalable AI systems.
- 笔记
- Zotero links
- PDF Attachments
FM, with its enormous size, pre-trained knowledge, and exceptional performance, serves as a robust starting point for FL, facilitating faster convergence and better performance under non-iid data.
FL支持:
- 随机几乎从0开始初始化的模型训练
- 联邦迁移学习微调已经初始化的模型
FL与FM是共生互助的关系:
FL为FM
提供分布式数据,扩展了FM的数据;
提供计算共享,将训练压力分配给FL参与者;
FM为FL
提供了一个好的起点,利用FM丰富的知识和性能
利用 FM 生成合成数据可以丰富数据多样性
Federated Learning for Foundation Models
Motivations of FL for FM
Shortage of Large-scale High-Quality Legalized Data
- FM很难得到充足的、高质量的 public data,使用生成的数据又会导致模型的崩塌以及遗忘
- public available data 使用这些数据集训练的模型可能面临法律和版权相关的挑战,从而使公共数据源的使用进一步复杂化,并妨碍 FM 的准确性和相关性
FL 不需要寻找大量的数据,可以允许 FM 利用广泛来源的丰富数据 diverse and representative data
High Computational Resource Demand
FL enables pool their computational power, 汇集算力
Continuous Data Growth
真实场景中数据是不断收集的和增多的,给 FM 的持续更新带来的挑战(尤其数据是分布式时)
Data Privacy and Control
leaving individuals uncertain about the usage of their private data for training purposes
Enhancing User Experience through Local Deployment of FMs
传统方法使用中心化的 FM,这会导致网络延迟 Latency
通过将FM 部署到 edge devices,消除或最小化网络通信,显著减小延迟,提供了更快的响应时间
Challenges of Empowering FM with FL
Large Model Incurs High Memory, Communication, and Computation
由于FM size大,导致了 high memory and communication and computation requirements.
- Difficulty in hosting FMs on FL clients.
FM is resource-intensive to maintain and deploy. - Huge communication cost associated with sharing FM in FL
需要在 client 和 server 之间,通过有限的带宽,传输 extensive 模型参数或者model updates,这是 time-consuming and resource-intensive.- 频繁的通信又会导致 power consumption
- 大量的数据传输又会导致数据泄露的风险增大
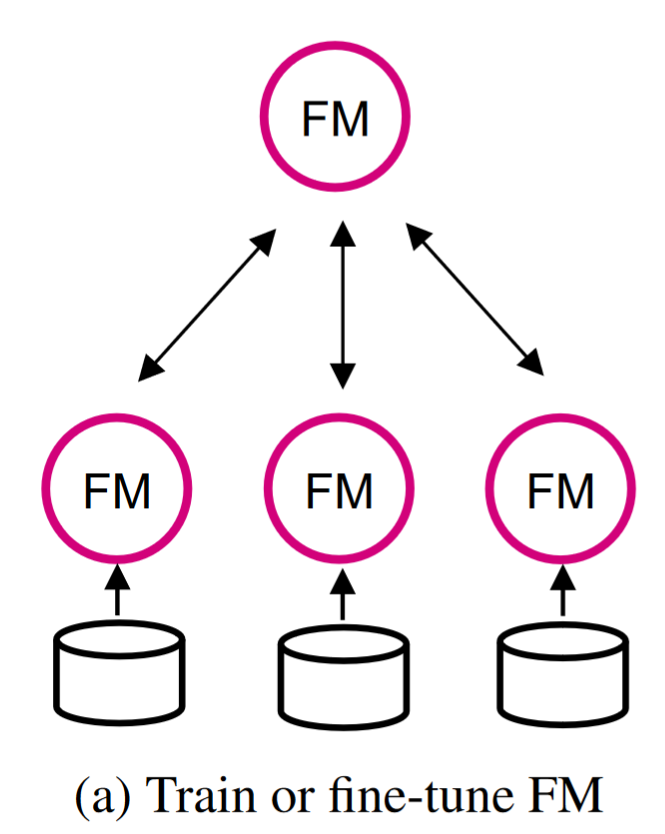
Challenges in Data Privacy and System Security
提取的敏感信息可能导致 Membership inference attacks and data recovery
varying amounts of data and computing power to actively participate
Complex Incentive Mechanisms for Collaboration
incentivize entities 激励机制,对于不同的 varying amounts of data and computing power to actively participate
定义模型的所有权并确保参与方公平的利润分配至关重要
Opportunities and Future Directions
Integrating FL into the Lifespan of FMs
allowing FL to contribute their local knowledge and insights to collectively enhance the performance and accuracy of the overall system
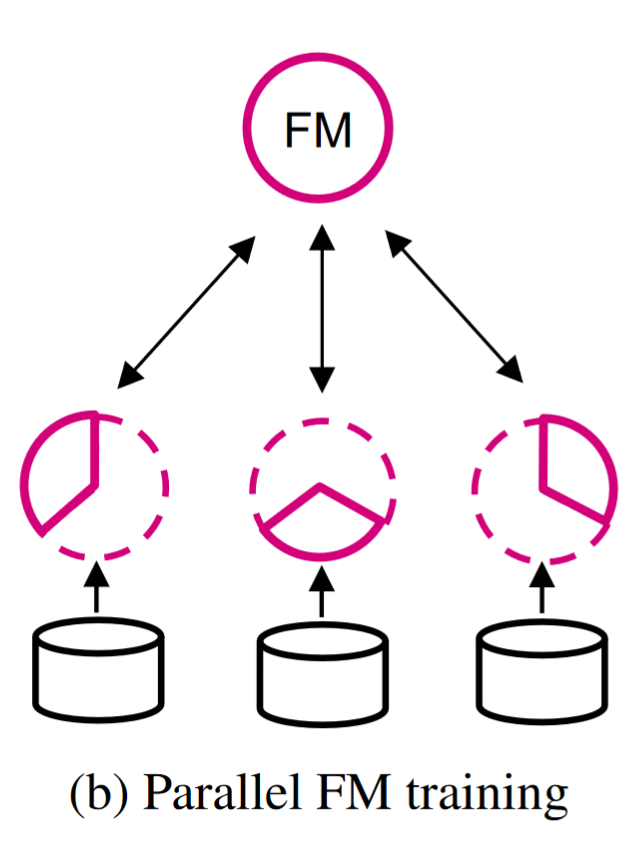
Memory, Communication, and Computation Reduction
Model parallelism involves partitioning the model and distributing it across devices for parallel processing, while pipeline parallelism improves efficiency and scalability
参与者使用私有数据训练分区模型
Parameter-efficient training methods adapt FMs to specific domains or tasks
freeze the parameters of the FM and fine-tune only a small adapter
reduce the communication and computation demands.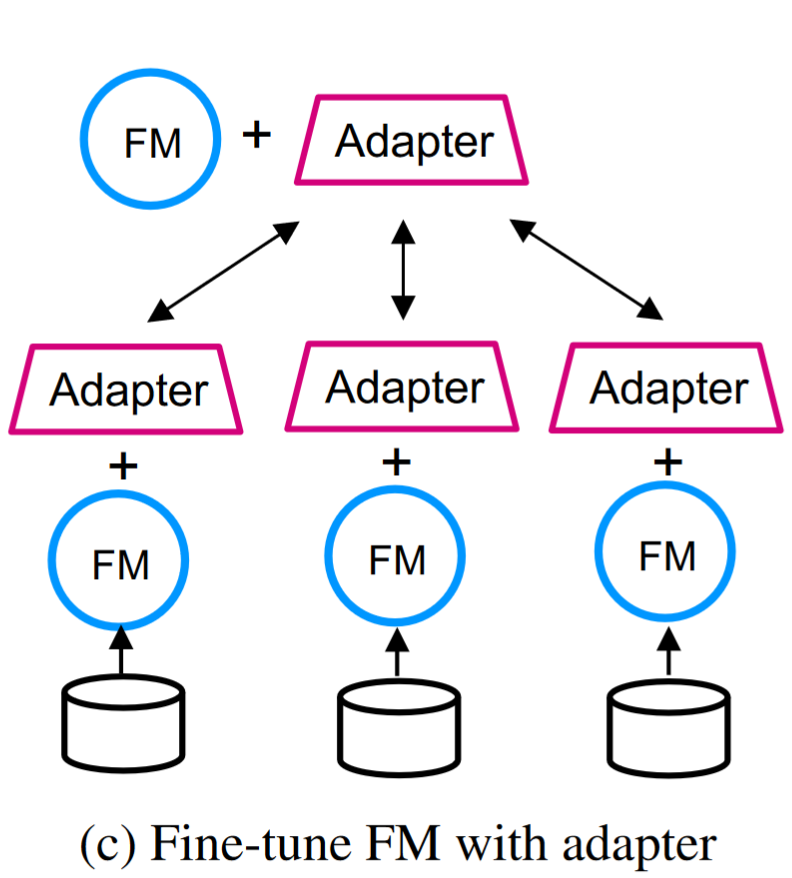
Prompt tuning
freezing the entire FM’s parameters and fine-tuning lightweight additional tokens.
leveraging FL to enhance the quality and effectiveness of prompts in FM training
但是这种方法需要 user devices 持有 large FM models, 或者face privacy concerns,因为需要通过 FM APIs 将敏感数据发送
Advanced model compression techniques
knowledge distillation, a smaller model is trained to replicate the behavior of a larger one
quantization, reduces the numerical precision of the model’s parameters
未来的工作应该在不影响模型精度的情况下,努力最大限度的压缩和量化

Foundation Models for Federated Learning

Motivation of FM for FL
Data Privacy and Shortage Dilemma in FL
clients may have limited or imbalanced data, lead to suboptimal performance of the model as it might not capture the full diversity of the data distribution
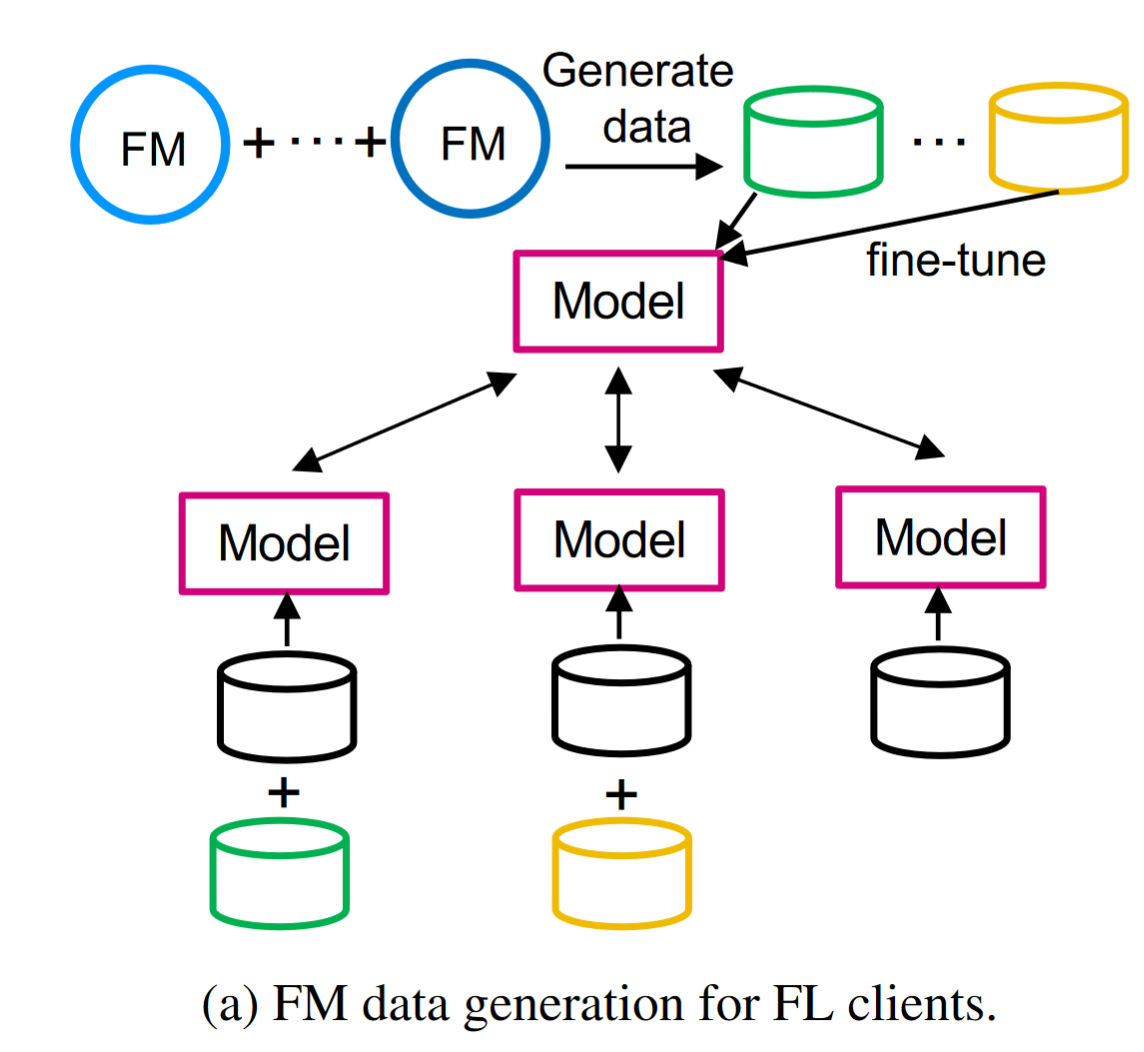
using FM to generate synthetic data, these data can be transmitted to clients for local training or used to fine-tune the global model.
By generating more data to enrich original training data or serve as public data, data scarcity problem can be largely alleviated.
合成的数据也能够引入多样性,缓解过拟合
Performance Dilemma in FL
FMs can serve as a good starting point for FL, clients can directly conduct fine-tuning on their local data without training from scratch,
avoiding huge communication cost
FMs can serve as a good teacher to help address the suboptimal performance issue in FL through knowledge distillation, utilizing the outputs of the FM (acting as the “teacher”) to guide the training of a simpler model within the FL system (the “student”).
如下图,Each client then utilizes the pre-trained student model to enhance its local training. By transferring knowledge from the FM to the smaller model, the performance and generalization abilities of the student model can be improved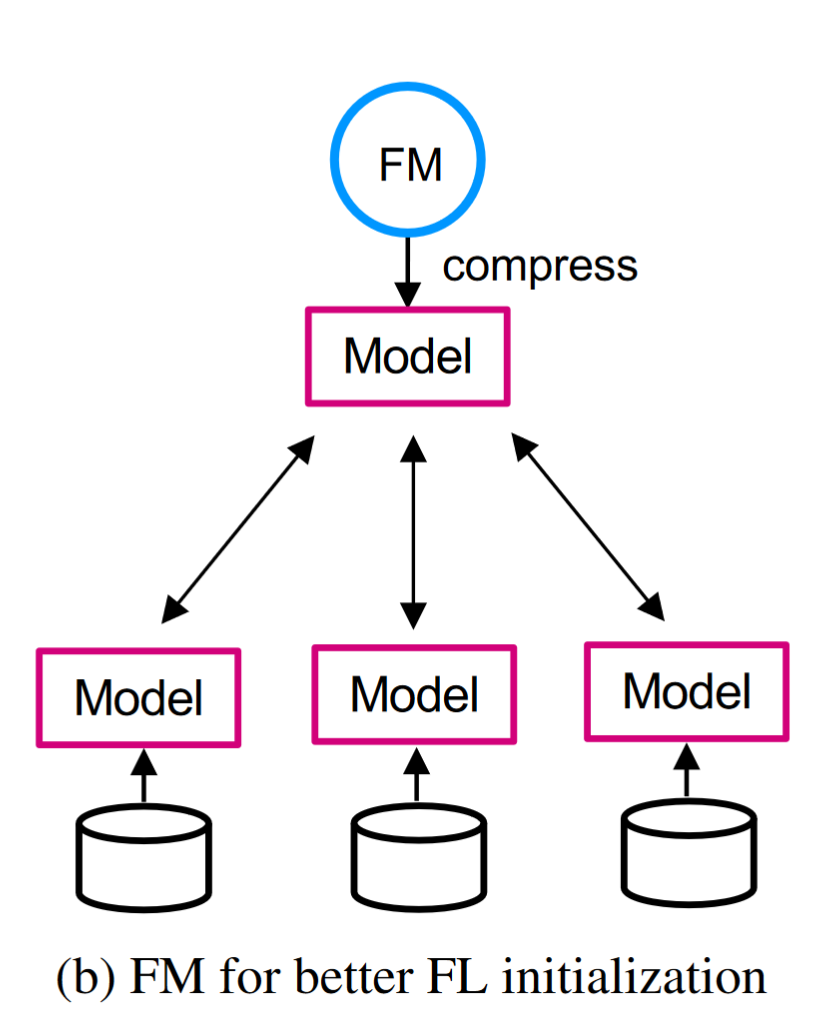
Challenges in Foundation Models for Federated Learning
- Law Compliance and Responsible Technology Usage of FMs for FL
- Problematic Synthetic Data Generated by FMs
- Unique Challenges in the Integration of FMs into FL
- Label Scarcity in FL
- Continuously changing environment in FL
- Domain gap in FL
- Data and system heterogeneity in FL
- Staleness in FL
- Static vs dynamic FMs
Personalization of FM for FL
探索适应FL环境下多样化应用场景的个性化FMs是一个很有前景的未来方向
在异构联邦 heterogeneous FL 中更适用,客户在内存和计算能力方面表现出相当大的差异
- Tailoring FMs to heterogeneous clients in FL
allow FMs to better cater to the unique data characteristics and computational constraints of each client in the FL network.
设计算法,dynamically adjust the model’s complexity based on the computational resources available at each client.
selectively transferring knowledge from the FM to the local models, focusing on the most relevant aspects for each client’s specific task.
- FM as a problem solver for data imbalance and domain shift in FL.
extract meaningful representations even from limited samples - Personalized FMs for personalized data synthesis
More Advanced Knowledge Distillation Techniques of FMs for FL
FMs在增强FL模型方面的潜力是巨大的
Specific knowledge distillation from FM to FL
传统的蒸馏方法通常假设访问大型的、集中的数据集
develop more sophisticated distillation techniques. These techniques could potentially target specific layers or components of the FMLow-cost knowledge distillation
蒸馏技术能够在不引起高计算成本的情况下提取有用的信息Fair and privacy-preserving knowledge transfer from FM to FL
the benefits of FL and FM integration are distributed equitably across all participating clients, and that the privacy of each client’s data is respected throughout the distillation processBlack-box knowledge distillation from FMs to FL
从一个预先训练好的FM (称为教师模型)中迁移知识到许多FL客户端(称为学生模型),而无需直接访问教师模型的内部参数或体系结构细节。
将教师模型的输出作为伪标注,用于FL设置中的训练数据, 学生模型学习模仿教师模型的行为和知识
但是,involves a public data in the same domain for alignment

