HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients
Metadata
- Tags: #Heterogeneity #Federated-Learning
- Authors: [[Enmao Diao]], [[Jie Ding]], [[Vahid Tarokh]]
Abstract
Federated Learning (FL) is a method of training machine learning models on private data distributed over a large number of possibly heterogeneous clients such as mobile phones and IoT devices. In this work, we propose a new federated learning framework named HeteroFL to address heterogeneous clients equipped with very different computation and communication capabilities. Our solution can enable the training of heterogeneous local models with varying computation complexities and still produce a single global inference model. For the first time, our method challenges the underlying assumption of existing work that local models have to share the same architecture as the global model. We demonstrate several strategies to enhance FL training and conduct extensive empirical evaluations, including five computation complexity levels of three model architecture on three datasets. We show that adaptively distributing subnetworks according to clients’ capabilities is both computation and communication efficient.
- 笔记
- Zotero links
- PDF Attachments
Note
HeteroFL to address heterogeneous clients equipped with very different computation and communication capabilities
之前的方法默认假设 server 和 clients 的模型架构是相同的,由于 indigent client / stragglers 的存在,这极大限制了 global model complexity
In practice, the computation and communication capabilities of each client may vary significantly and even dynamically
- local model 不再需要和 global model 共享相同的架构
- adaptively distributing subnetworks according to clients’ capabilities is both computation and communication efficient. 根据客户的能力自适应地分配子网络,计算和通信效率都很高。
Introduction
we consider local models to have similar architecture but can shrink their complexity within the same model class.
为了简化异构的过程:
local model parameters to be a subset of global model parameters
但是有新的问题:
how to find the optimal way to select subsets of global model parameters?
现有的方法:
modulate the size of deep neural networks by varying the width and depth of networks,we choose to vary the width of hidden channels.
本文提出:
global model $W_g\in R^{d_g\times k_g}$
$d_g$ is the output channel size of this layer
$k_g$ is the input channel size of this layer
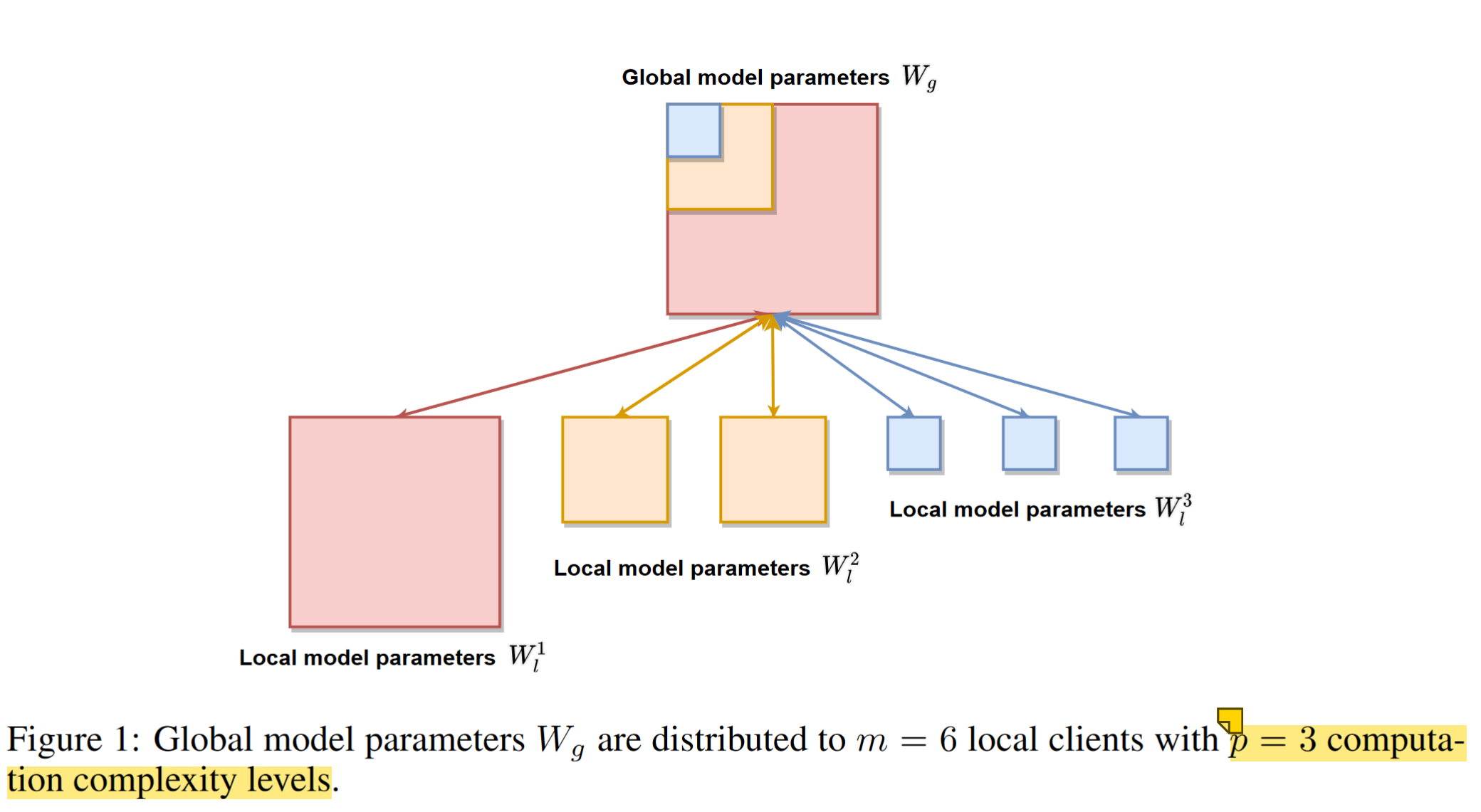
multiple computation complexity levels 多个复杂度等级
$W_l^p\subset W_l^{p-1}\cdots \subset W_l^1$
数字越大,表示模型越小
设 r 为隐藏通道收缩率 $d_l^p = r^{p-1}d_g$ $k_l^p = r^{p-1}k_g$
由此可得,local model parameters size $|W_l^p|= r^{2(p-1)|W_g|}$,模型的压缩率是 $R = \frac{|W_l^p|}{|W_g|} = r^{2(p-1)}$
根据本地客户端的 corresponding capabilities,自适应地分配全局模型参数子集。
假设每个复杂度水平对应的 clients 的数量是:${m_1,\cdots,m_p}$
global aggregation:
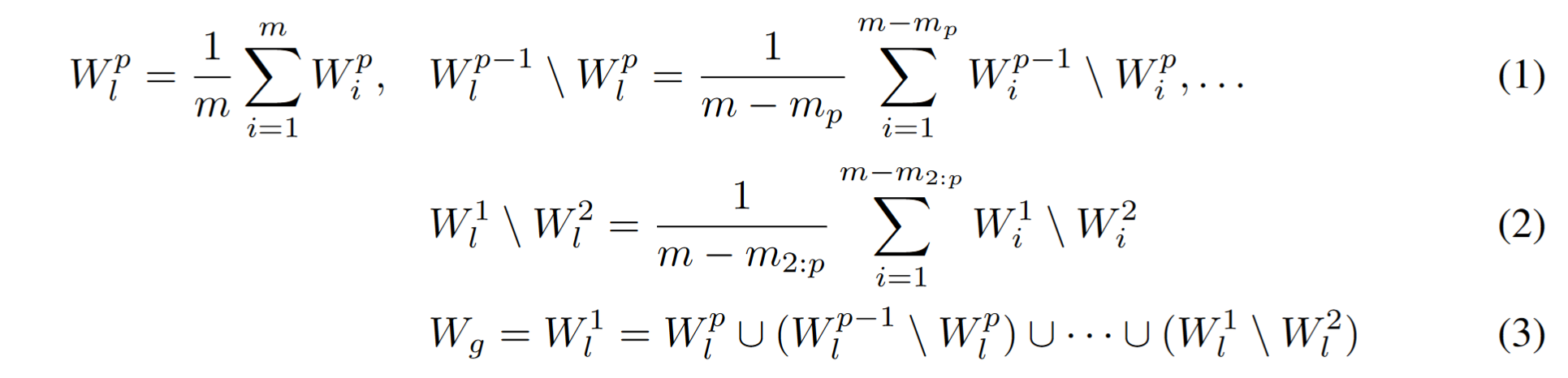
$W_l^{p-1} \setminus W_l^p$ 表示包括 $p-1$ 复杂度的,不包括 $p$ 复杂度的
$W_l^p$ 是最小的模型参数
the global model parameters W t g is constructed from the union of all disjoint sets of the partition
全局模型参数 $W_t^g$ 是由分区的所有互不相交的集合构成的
模型越小,与自己参与 FedAvg 的 local model 越多,
较大的局部模型参数执行较少的全局聚合,小型局部模型可以从全局聚合中获益更多。
Static Batch Normalization
sBN 不跟踪运行估计值,只是对批处理数据进行归一化处理。不跟踪本地运行统计数据,因为本地模型的大小也可能动态变化
训练过程结束后,服务器会依次查询本地客户端,并累积更新全局 BN 统计数据。
Scaler
现有的方法是 dropout
dropout is usually attached after the activation layer
本文直接从 global model 选择 local model parameters
在参数层之后、sBN 层和激活层之前添加了一个 Scaler 模块。
在训练阶段,表征的缩放比例为 $1/r^{p-1}$
global model 聚合之后,可以直接被用于推理,无需缩放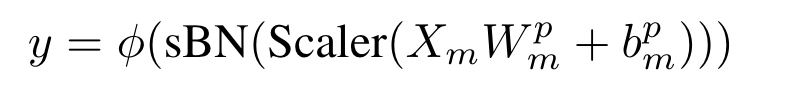
$\phi()$ 是非线性激活层,类似 ReLU
本地能力信息 $L_m$ 是对 computation and communication 能力的抽象。
本地的算力是发送给 server 的,服务器就能知道应分配给客户端的模型复杂度。
Experiments
five different computation complexity levels {a, b, c, d, e}, hidden channel shrinkage ratio r = 0.5.
实验中,使用的是离散复杂度收缩率 0.5, 0.25, 0.125, and 0.0625,例如 a 是全参数,b-e依次是0.5, 0.25, 0.125, and 0.0625的收缩率
每个 client 都有一个初始的计算复杂度水平
1、Fix 固定每个 client 的复杂度水平
2、Dynamic 随机改变客户端模型复杂度的分配
client selection: uniformly sample from all possible available levels for every active client at each communication round.

