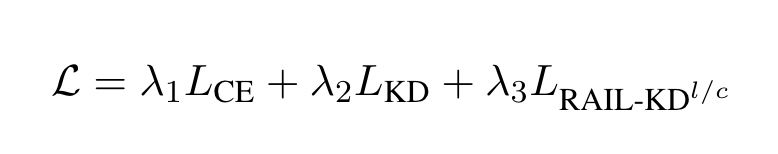RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
Metadata
- Authors: [[Md Akmal Haidar]], [[Nithin Anchuri]], [[Mehdi Rezagholizadeh]], [[Abbas Ghaddar]], [[Philippe Langlais]], [[Pascal Poupart]]
- Date: [[2021-10-01]]
- Date Added: [[2023-11-17]]
- URL: http://arxiv.org/abs/2109.10164
- Topics: [[KD]]
- Tags: #Computer-Science—Computation-and-Language, #zotero, #literature-notes, #reference
- PDF Attachments
Abstract
Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
Zotero links
Note
standard KD technique only targets the output of teacher and student models
However, intermediate layer distillation suffers from excessive computational burdens and layer mapping.
RAndom Intermediate Layer Knowledge Distillation (RAIL-KD), intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model.
In the original KD technique: the teacher output predictions are used as soft labels for supervising the training of the student.
intermediate layer distillation (ILD) enhances the knowledge transfer beyond logits matching.
mapping intermediate layer representations of both models to a common space.
层选择是随机进行的,因此教师的所有中间层都有机会被选择进行蒸馏。
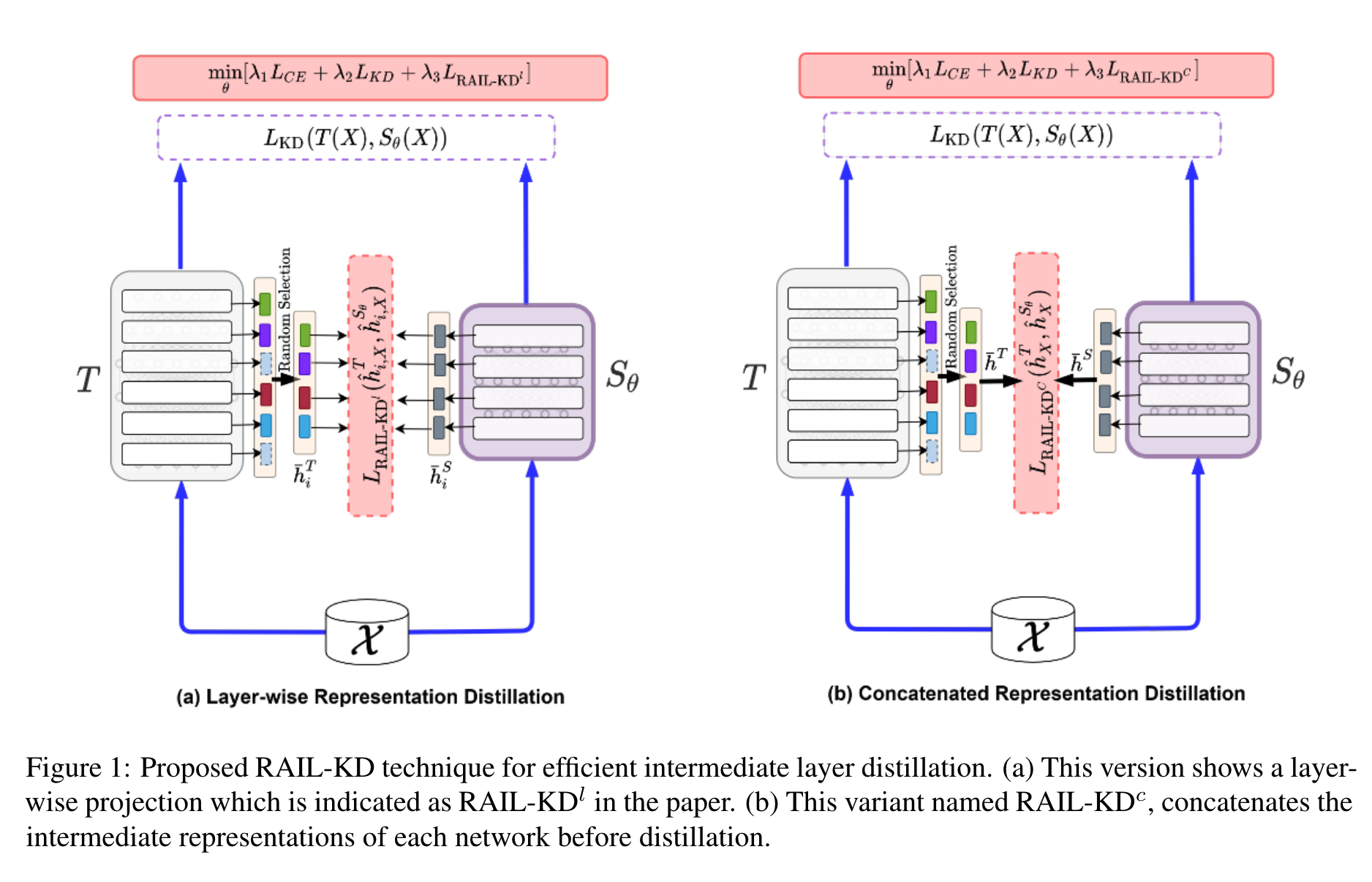
对比几种主流的 intermediate layer distillation: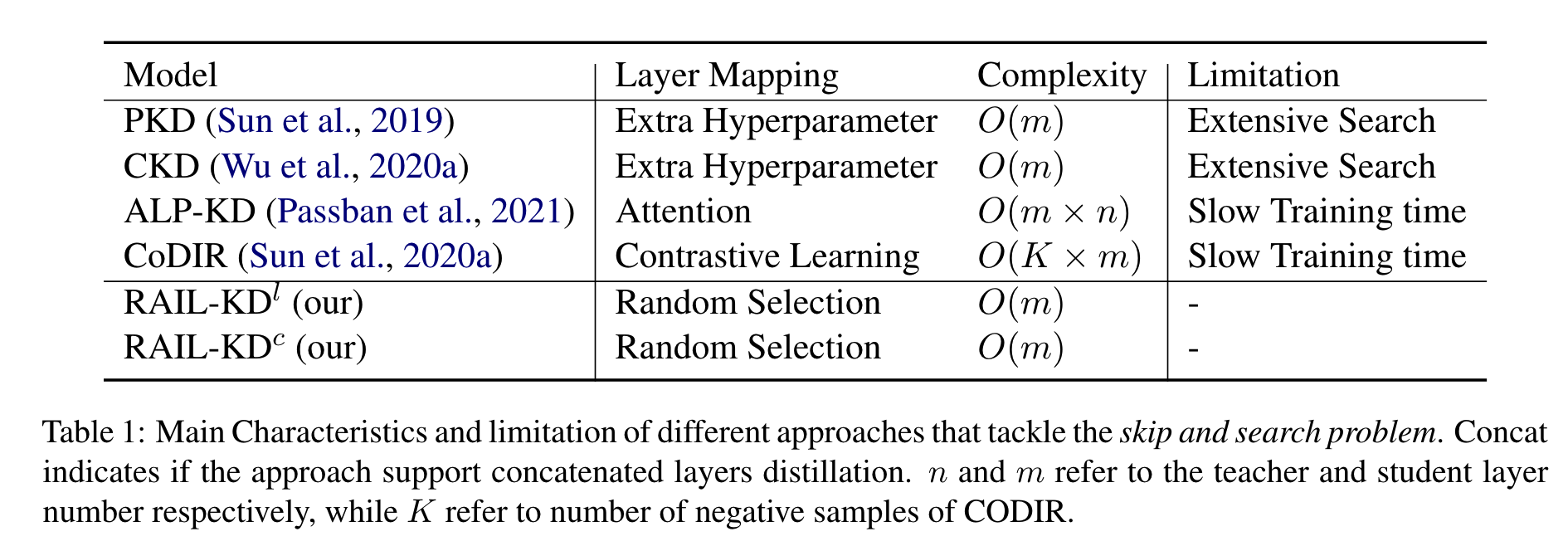
RAIL-KD
traditional intermediate layer distillation techniques:
keep the selected layers of the teacher for distillation fixed during training
RAIL-KD:
a few intermediate layers from the teacher model are selected randomly for distillation.
randomly select m out of n layers
$(X,y)$ 代表 sample,$X={x_0,…,x_{L-1}}$, L 是序列长度
输入X的对于 teacher 和 student 的 intermediate representation:
$H_X^T = {H_{1,X}^T,…,H_{m,X}^T}$
$H_X^{S_{\theta}} = {H_{1,X}^{S_{\theta}},…,H_{m,X}^{S_{\theta}}}$
其中,$H_{i,X}^T = \cup_{k=0}^{L-1} {H_{i,x_k}^T}\in R^{L\times d_1}$. $H_{i,X}^{S_{\theta}} = \cup_{k=0}^{L-1} {H_{i,x_k}^{S_{\theta}}}\in R^{L\times d_1}$
Layer-wise RAIL-KD

Concatenated RAIL-KD

Training Loss
$L_{CE}$ is the original cross-entropy loss
$L_{KD}$ distill the knowledge from the output logits of the teacher model T to the output logits of the student model $S_{\theta}$
$\lambda_1 + \lambda_2 + \lambda_3 = 1$