FedPEAT Convergence of Federated Learning, Parameter-Efficient Fine Tuning, and Emulator Assisted Tuning for Artificial Intelligence Foundation Models with Mobile Edge Computing
Metadata
- Authors: [[Terence Jie Chua]], [[Wenhan Yu]], [[Jun Zhao]], [[Kwok-Yan Lam]]
- Date: [[2023-10-26]]
- Date Added: [[2023-11-16]]
- URL: http://arxiv.org/abs/2310.17491
- Topics: [[FL+LLM]]
- Tags: #Computer-Science—Machine-Learning, #Computer-Science—Networking-and-Internet-Architecture, #zotero, #literature-notes, #reference
- PDF Attachments
Abstract
The emergence of foundation models, including language and vision models, has reshaped AI’s landscape, offering capabilities across various applications. Deploying and fine-tuning these large models, like GPT-3 and BERT, presents challenges, especially in the current foundation model era. We introduce Emulator-Assisted Tuning (EAT) combined with Parameter-Efficient Fine-Tuning (PEFT) to form Parameter-Efficient Emulator-Assisted Tuning (PEAT). Further, we expand this into federated learning as Federated PEAT (FedPEAT). FedPEAT uses adapters, emulators, and PEFT for federated model tuning, enhancing model privacy and memory efficiency. Adapters adjust pre-trained models, while emulators give a compact representation of original models, addressing both privacy and efficiency. Adaptable to various neural networks, our approach also uses deep reinforcement learning for hyper-parameter optimization. We tested FedPEAT in a unique scenario with a server participating in collaborative federated tuning, showcasing its potential in tackling foundation model challenges.
Zotero links
Note
Abstract
存在问题:collaborative training, model ownership, and computational limitations.
本文:generalize the offsite tuning approach to Emulator-Assisted Tuning (EAT) and combine it with Parameter-Efficient FineTuning (PEFT) to create Parameter-Efficient Emulator-Assisted Tuning (PEAT), expanding its use into federated learning (FL) as Federated Parameter-Efficient Emulator-Assisted Tuning (FedPEAT).
FedPEAT:adapters, emulators, and PEFT techniques for FL fine-tuning.
Adapters: 针对特定任务定制预训练模型
Emulators: 提供原始模型的压缩参数
实验评估:服务器拥有数据并参与协作式联合基础模型微调过程,而不是纯粹充当聚合器
Introduction
Foundation models
These models, pretrained on massive amounts of data, have the ability to understand and generate images, texts, audio with remarkable accuracy.
LLM can be fine-tuned to excel in specific domains or tasks.
pre-training of foundation models focuses on self-supervised learning from large-scale unlabeled data, capturing general language understanding.
fine-tuning involves adapting these pre-trained models to specific tasks using task-specific labeled data, enabling specialized performance
Motivations
The lack of easy sharing mechanisms hampers the democratization of large language
models and their use in applications that require continuous updates and fine-tuning
1、 There is a need to develop mechanisms that allow model owners to collaborate with external parties securely.
2、Fine-tuning large language models is computationally intensive.
3、fine-tuning on local devices is often not feasible due to their limited computational capabilities
Proposed EAT structure
Emulator:variable number of neural network layers, variable number of nodes per layer, and even variable arrangements of transformer attention units
适应性确保了模型可以在从简单到复杂的各种任务中进行有效的微调
Expansion to PEAT architecture
Parameter-Efficient Fine Tuning (PEFT) such as Low-rank Adapters (LoRA) , prompt tuning , and adapters.
Combine EAT and Parameter-Efficient Fine-Tuning (PEFT) to present Parameter-Efficient Emulator-Assisted Tuning (PEAT).
FedPEAT framework
Extend the use of PEAT into the domain of federated learning (FL)
–> Federated Parameter-Efficient EmulatorAssisted Tuning (FedPEAT).
不需要模型所有者向客户端传输整个模型, 不需要客户端向模型所有者发送本地数据的
FedPEAT adaptive control mechanism
Orchestrator to control critical hyperparameters
1、emulator model compression ratios,
2、adapter parameter-efficient fine-tuning parameters
3、device selection for participation
Ensuring that the fine-tuning process remains both memory and computation efficient
Server-Device collaborative tuning
两种 collaborative federated learning 的场景:
1、all data resides on mobile edge devices (i.e., clients), with no central server involvement。
模型微调完全发生在 Clients, server 只是聚合 adapter module parameters
2、 data is distributed across both client devices and a central server.
微调发生在客户端设备和服务器上
服务器拥有数据并参与协作联邦基础模型微调过程,而不是纯粹充当聚合器
Contributions
- generalize the offsite tuning to Emulator-Assisted Tuning (EAT)
- combine EAT and Parameter-Efficient FineTuning (PEFT) to present Parameter-Efficient EmulatorAssisted Tuning (PEAT)
- expand the use of PEAT into the domain of federated learning (FL) (FedPEAT),
- adaptive control mechanism,dynamically selects emulator compression parameters and user-device participation
- considered user device memory constraints
- the server possesses data and partakes in the collaborative federated foundation model fine-tuning process
Emulator
To mimic the behavior of the original foundation model, 提供可与大型同类产品相媲美的性能,同时大幅降低计算和存储需求。
1、safeguards the proprietary nature of model ownership (privacy)
2、store and undertake model fine-tuning using a significantly smaller-sized emulator.(memory)
emulator: pruning, layer drop, knowledge distillation.
Adapter
Adapters 对现有模型进行模块化添加,to facilitate task-specific adaptations with minimal modifications to the original model
A smaller set of weights for downstream task fine-tuning.
1、The adapter is designed to be a plug
2、The smaller adapter size reduces adapter transmission costs.
FedPEAT
Emulators and Adapters
(函数 $f()$ 是模型的压缩算法,例如 layer dropping, model pruning)
Adapter: 一些可调层的参数,用于编码来自下游任务的信息来促进模型微调
Emulator:是原始模型的修改版,作为微调 adapters 的指导框架 (参数冻结,目的是仿真原始模型)
$w$ 表示 server 和 device 协同训练的参数
$w’_s$ 表示 server 冻结的参数
$w’_c$ 表示 client 冻结的参数
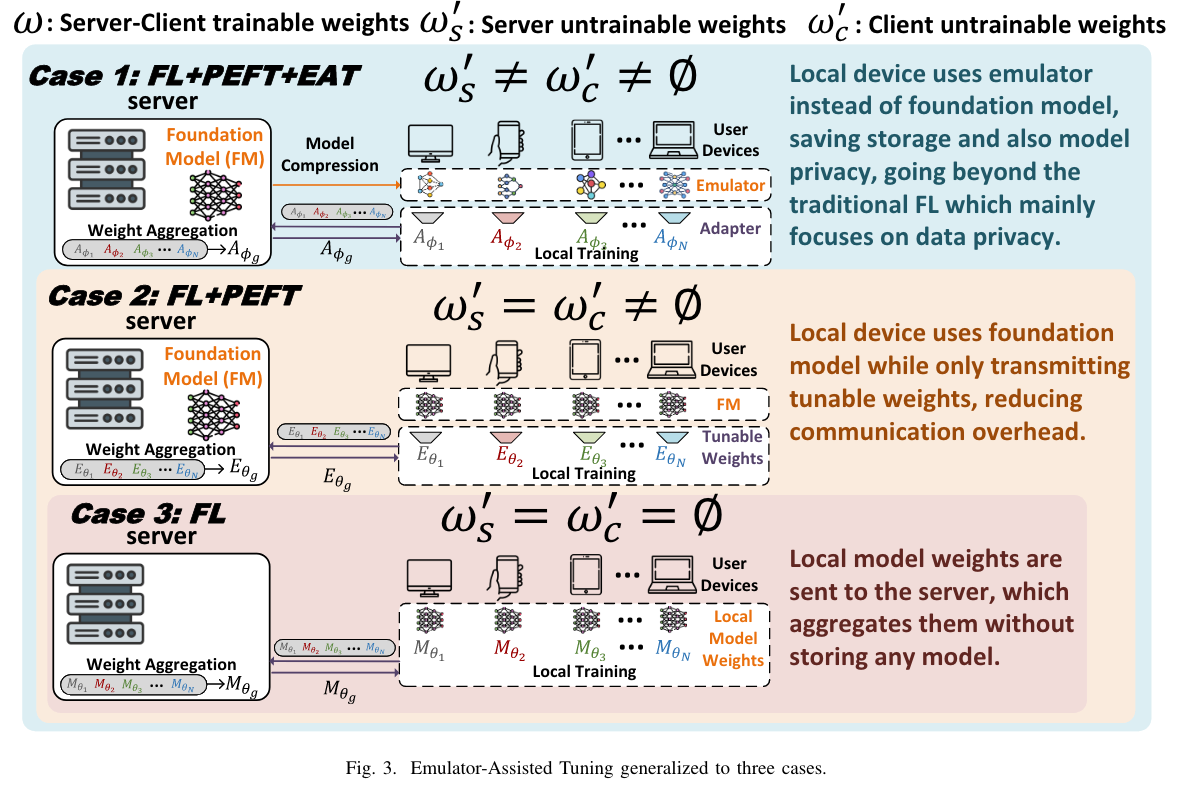
Case 1 $w’_s\neq w’c\neq \emptyset$
More generalized framework.
permit various user devices (UEs) to employ distinct emulators $E{\theta_i}$ –> untrainable weights $w_c’$
允许设备之间的 emulators 不同
1、 efficient decompression
2、 adaptiveness of the foundation model
Case 2 $w’_s= w’_c\neq \emptyset$
case1 的特殊情况
每个 device 的 emulator 与总体基础模型的静态参数一致
在 FL 中协同考虑使用 PEFT 技术
Case 3 $w’_s= w’_c = \emptyset$
case 1 的特殊情况
所有参与者都利用 global foundation model ω 的可调参数。
这种场景很类似于传统的联邦学习,即将单个模型的参数合并,形成整体的模型
Tuning Process
Prior to tuning
Server model $M_{\theta_g}$ decomposed into two parts:
- untrainable subset of weights: $E_{\theta}’$
- Adapter: $A_{\phi}$
so, the server model $E_{\theta}’\odot A_{\phi}$
Offsite tuning only considers a single device tuning and does not consider a multiple device collaborative training scenario.
本文可以为每个 client customized to create emulator $E_{\theta_i}$ (tailored 量身定制)
Tuning
初始化的时候,分配给每个 client 的 adapter $E_{\theta_i}^0$ 随机初始化的参数值
每个 device 执行 emulated-assisted fine-tuning with local dataset $D_i^t$ ,在 emulator 的帮助下,更新 $A_{\theta_i}^1$
每个 client 上传 adapter parameters 到 server 来执行 adapter parameter aggregation:
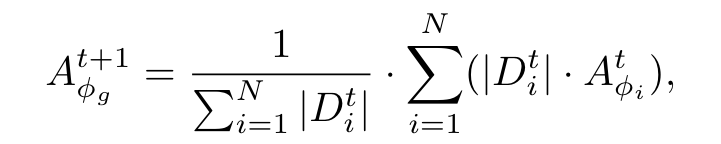
server 下发 global adapter $A_{\phi_g}^1$

FedPEAT Adaptive Control
device $i$ 传输 adapters 以及下载 emulators 的时间: $Q_i = \frac{F_i^t}{r_i^t}$ (传输量处以传输速度)
其中, $r_i^t$ 是 device $i$ 与 server 之间的传输速率,这取决于 server 对 device
$i$ 的传输功率 $p_{i,trans}^t$ , 信道增益 $g_i^t$ ,传播模型
本文为了简便,对于传输功率和信道增益都是赋了随机值,省略考虑了模型微调的时间
$F_i^t$ 是server 传输的总的 adapters 和 emulators 大小,以及在 step t, device $i$ 向server 传输的 adapter 的大小
Formulation: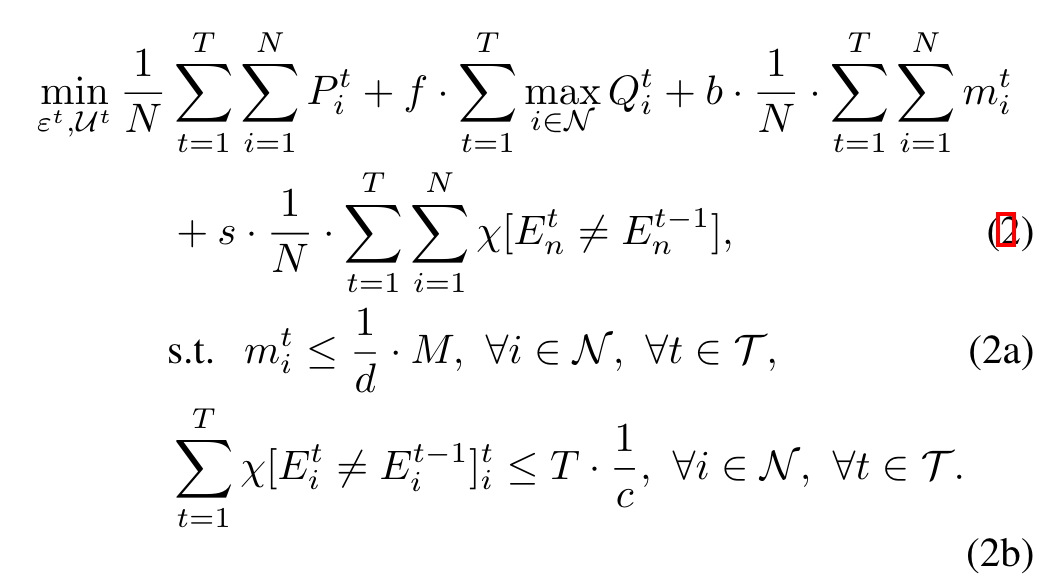
$P_i^t$ 代表距离收敛的困惑度
$Q_i^t$ 代表一轮中 adapter 和 emulator 的总时间
$X[E_i^t\neq E_i^{t-1}]$ 代表 emulator 交换的次数,要么为1,要么为0
$m_i^t$ 代表 device $i$ 模型的内存空间
对于 emulator compression 以及 device selection 引入 penalty
Motivation: 鼓励更快地收敛模型,同时确保最大限度地减少 UE 之间的总传输延迟和所有 UE 的内存消耗。
A.Deep reinforcement learning approach
- State:
内存使用、模型调整性能和设备参与至关重要
- 计算 device-server channel 的信道增益
- 记录 UE i 进行 emulator exchange 的次数
2)Action:
agent action space - choice of emulator compression parameter $\varepsilon_i^t$ for each device (压缩参数)$\varepsilon^t = {\varepsilon_1^t,\varepsilon_2^t,\cdots,\varepsilon_i^t}$
- UE selection vector $U^t = {UE^t_i, UE^t_2, …, UE_N^t}$ for each device
3)Reward:
assign our reinforcement learning agent the reward as follows in each iteration
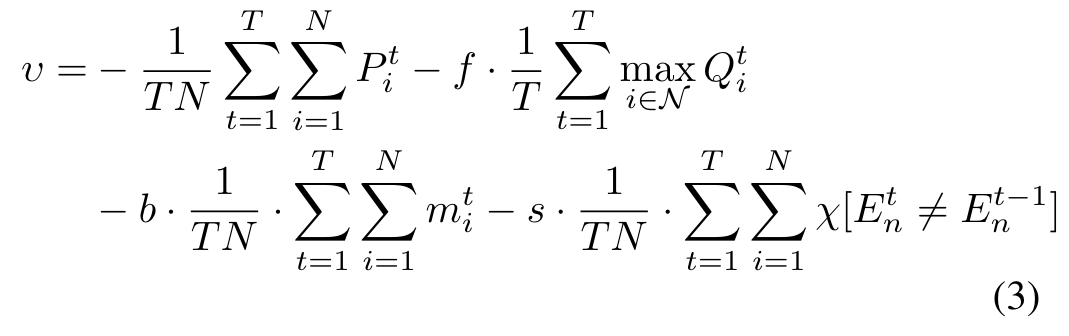
Penalties
当出现如下情况时,实施惩罚:
- the memory size of emulator $E_i^t$ and adapter $A_i^t$ exceeds an allowable fraction of the local device i’s memory capacity
- the emulator exchange count exceeds a given fraction of the total iteration
4)Reinforcement Learning Algorithm
adopted the Proximal Policy Optimization (PPO) algorithm
在强化学习等序列问题领域,即使是对参数的微小调整也会对性能产生深远影响
- It incorporates a Kullback–Leibler (KL) divergence penalty to regulate policy adjustments
- PPO makes use of an importance sampling technique
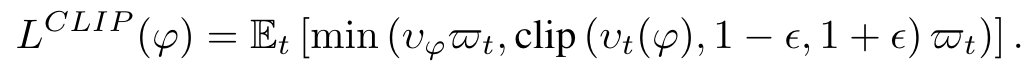
$\phi$ 代表 policy
$E_t$ 代表经验期望
$v_t$ 代表当前与之前 policy 的比率
$\over w_t$ 代表时间 t 的估计优势
$\epsilon$ 代表 clip 值
这种剪裁机制可作为一种保障措施,防止出现重大偏差,并确保政策保持在可信任的范围内
NUMERICAL EXPERIMENTS
对比实验:
1)FedPEAT without adaptive control
2)Federated full model fine-tuning (Fed-FT)
使用 GPT2-XL large language model as the foundation model.
1475 million parameters and 6.5 GB memory
Emulator compression: layer-drop
perplexity-layer drop retention numerical solution (困惑层降解)
由于 adapter 层的大小远小于 emulator ,我们认为它们的大小可以忽略不计。
如果传输的成本超过了困惑度或内存消耗的改善,则交换和传输新的模拟器权重
Conclusion
Federated Parameter-Efficient Emulator-Assisted Tuning (FedPEAT).
Adaptive control, a novel fusion of adapters and emulators
Adapters, equipped with trainable neural network parameters, tailor models for specific tasks, while emulators provide compressed, fixed-parameter representations
通过深度学习强化学习优化基本超参数的自适应控制机制,mitigates model privacy concerns and improves memory and computational efficiency.

