Low-Parameter Federated Learning with Large Language Models
Metadata
- Tags: #LLM #Federated-Learning
- Authors: [[Jingang Jiang]], [[Xiangyang Liu]], [[Chenyou Fan]]
Abstract
We study few-shot Natural Language Understanding (NLU) tasks with Large Language Models (LLMs) in federated learning (FL) scenarios. It is a challenging task due to limited labeled data and communication capacities in FL, especially with mobile devices. Recent studies show LLMs can be prompted to perform few-shot NLU tasks like sentiment analysis and arithmetic reasoning. However, the huge sizes of LLMs result in high computation and communication costs, making classical FL schemes impractical. To address these challenges, we propose Low-Parameter Federated Learning (LP-FL). LP-FL combines few-shot prompt learning from LLMs with efficient communication and federating techniques. Our approach enables federated clients to assign soft labels to unlabeled data using gradually learned knowledge from the global model. Through iterative soft-label assigning, we continually expand the labeled set during the FL process. Additionally, to reduce computation and communication costs, LP-FL utilizes the Low-Rank Adaptation (LoRA) technique for compact learnable parameter construction, efficient local model fine-tuning, and affordable global model federation. LP-FL consistently outperforms Full-Parameter Federated Learning (FP-FL) in sentiment analysis tasks across various FL settings. Its resistance to overfitting allows LP-FL to equal or surpass centralized training in few-shot scenarios.
- 笔记
- Zotero links
Note
Challenges of LLM in FL:
- limited labeled data
- communication capacities
Low-Parameter Federated Learning (LP-FL):
combines few-shot prompt learning from LLMs with efficient communication and federating techniques
- clients 从 global model 的 knowledge 将 soft labels 应用到 unlabeled data,以此来扩展 labeled set
- Low-Rank Adaptation (LoRA) technique, efficient local model fine-tuning
追求一种有效的微调方法,以最小的参数微调达到理想的结果
Use cases: data is often unlabeled, distributed learning with few-shot labeled data, achieve effective fine-tuning of a global model.
Contributions:
- consider an under-studied task of fine-tuning LLMs with distributed devices with limited communications and local computational powers.
- fine-tune the LLMs by adding task descriptions to the input examples for text sentiment classification. semi-supervised method to augment the dataset.
- fine-tuning a small subset of the local model parameters then federate averaging over all clients.
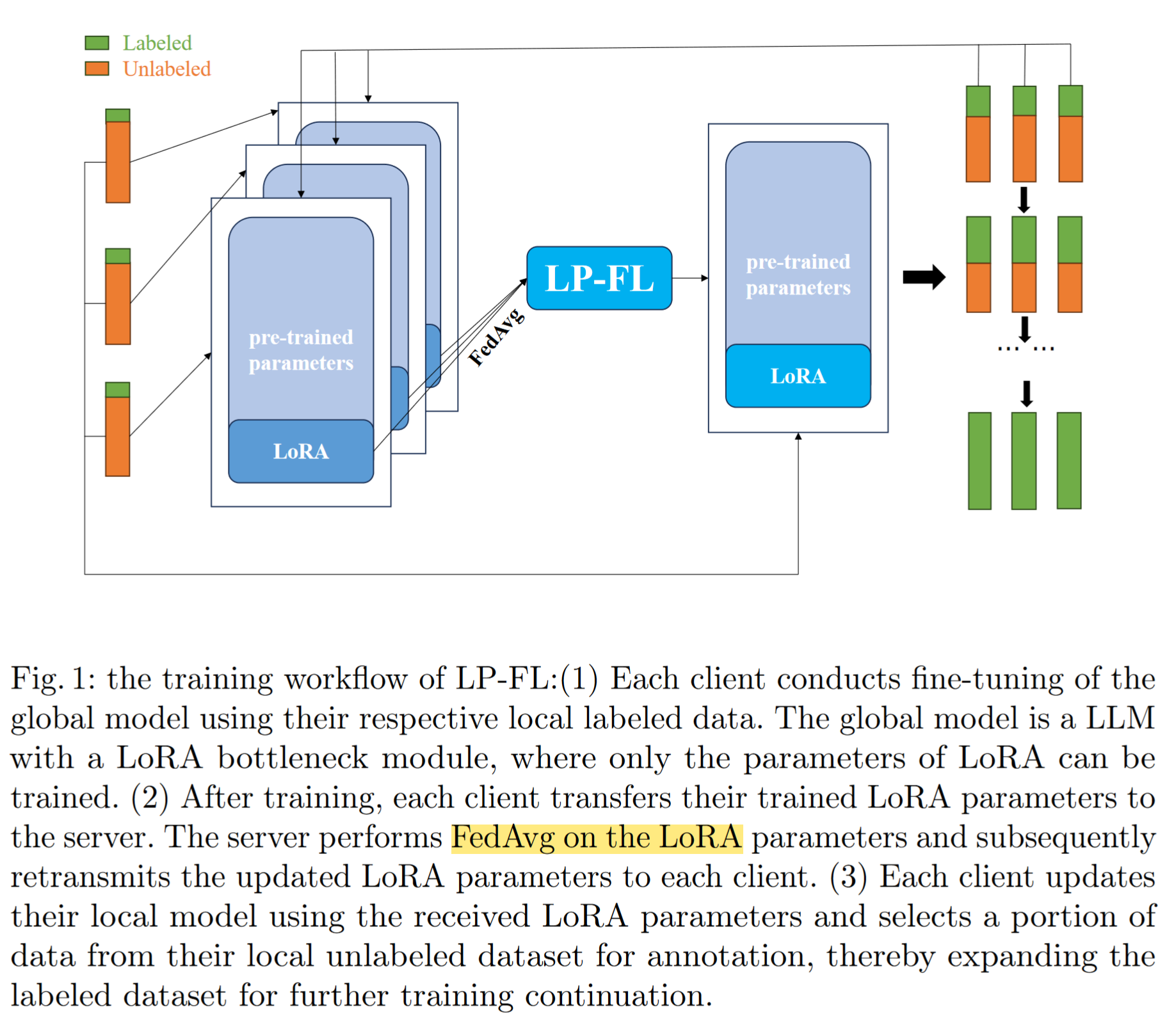
Workflow
- 使用 small labeled data fine-tuning the global model. (Train LoRA in clients side)
- server performs FedAvg on the LoRA parameters and retransmits the updated LoRA to clients.
- client updates their local model using the received LoRA, and select a portion of the unlabeled data for annotation (逐渐使用 unlabeled data 扩展 labeled set)
M 是 LLM
V 是词汇量的规模
$T_k$ is the labeled set, $U_k$ is the unlabeled set
sequence $x=(s_1,\cdots,s_n)$ ,$s_j\in V$
使用 P (x) 将带有mask token 的任务描述短语添加到 input sequence x
利用 LLM $M$ 预测 P(x) 中 mask token 位置的每个 $v\in V$ 的概率
给定序列 x,计算带有 label $l\in L$ 的score
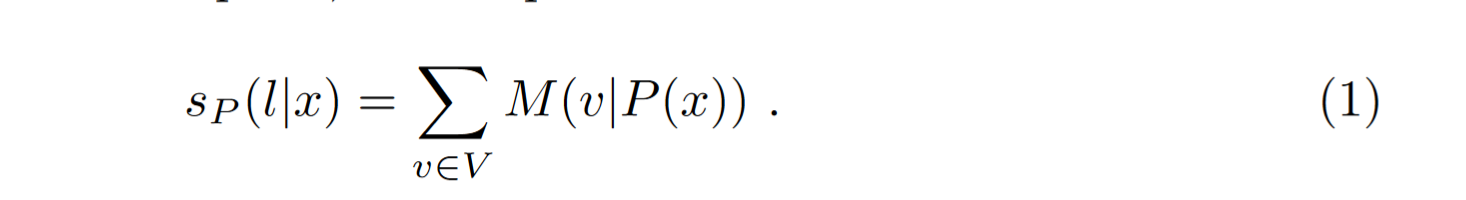
通过 softmax 函数获取标签上的概率分布,比较真实单词的预测概率,并使用标准交叉熵损失来衡量预测
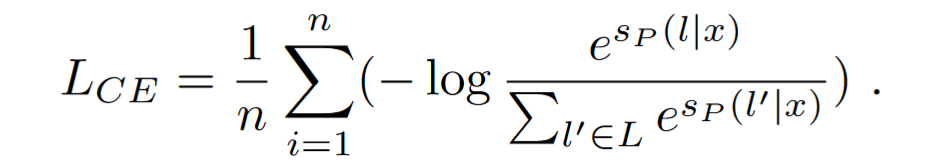
To address the communication burden arising from the substantial parameter size of the LLM, we utilize the Parameter-Efficient Fine-Tuning technique known as Low-Rank Adaptation (LoRA)
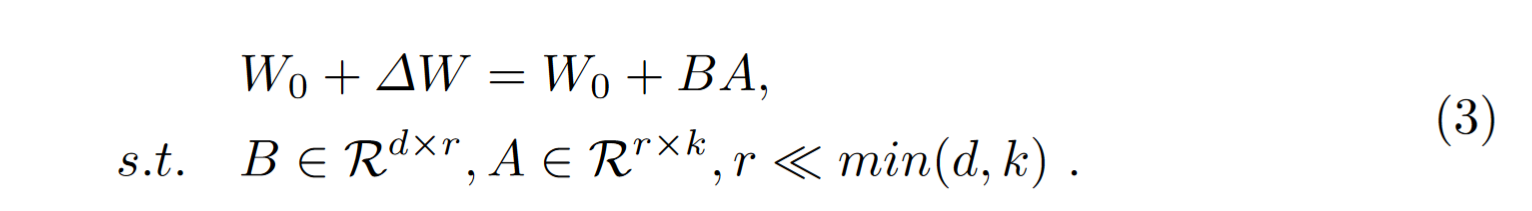
对 clients 训练得到的 LoRA,执行 FedAvg 更新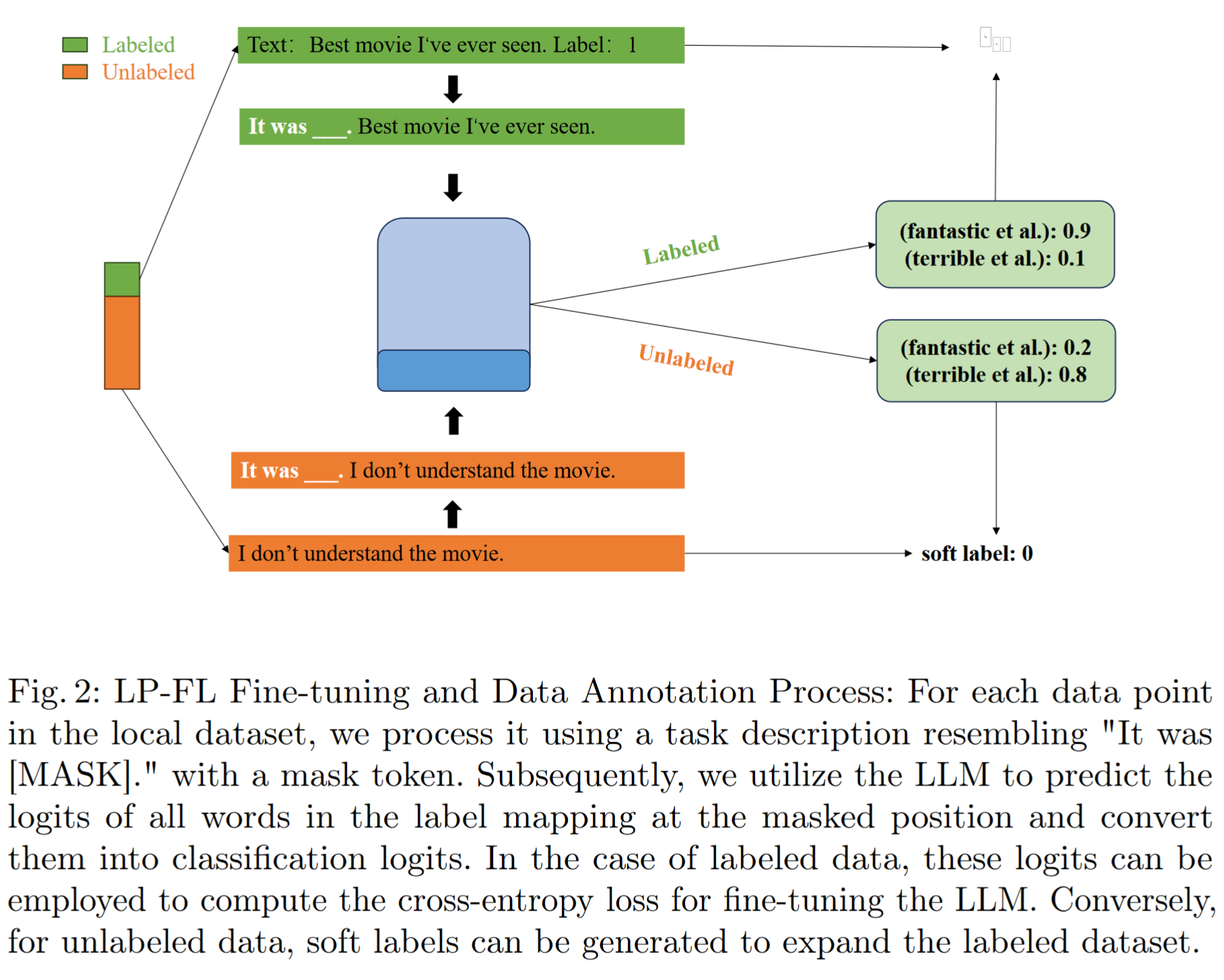
Framework


