Offsite-Tuning: Transfer Learning without Full Model
#LLM #Fine-tune
Metadata
- Authors: [[Guangxuan Xiao]], [[Ji Lin]], [[Song Han]]
- Date: [[2023-02-09]]
- Date Added: [[2023-11-05]]
- URL: http://arxiv.org/abs/2302.04870
- Topics: [[FL+LLM]]
- Tags: #Computer-Science—Computation-and-Language, #Computer-Science—Computer-Vision-and-Pattern-Recognition, #Computer-Science—Machine-Learning, #zotero, #literature-notes, #reference
- PDF Attachments
Abstract
Transfer learning is important for foundation models to adapt to downstream tasks. However, many foundation models are proprietary, so users must share their data with model owners to fine-tune the models, which is costly and raise privacy concerns. Moreover, fine-tuning large foundation models is computation-intensive and impractical for most downstream users. In this paper, we propose Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt billion-parameter foundation models to downstream data without access to the full model. In offsite-tuning, the model owner sends a light-weight adapter and a lossy compressed emulator to the data owner, who then fine-tunes the adapter on the downstream data with the emulator’s assistance. The fine-tuned adapter is then returned to the model owner, who plugs it into the full model to create an adapted foundation model. Offsite-tuning preserves both parties’ privacy and is computationally more efficient than the existing fine-tuning methods that require access to the full model weights. We demonstrate the effectiveness of offsite-tuning on various large language and vision foundation models. Offsite-tuning can achieve comparable accuracy as full model fine-tuning while being privacy-preserving and efficient, achieving 6.5x speedup and 5.6x memory reduction. Code is available at https://github.com/mit-han-lab/offsite-tuning.
Zotero links
Note
Transfer learning for downstream tasks.
Fine-tuning drawbacks:
- models are proprietary (所有权)users must share their data with model owners to fine-tune the models (costly and raise privacy concerns), trained weights are usually proprietary and not made public
- fine-tuning large foundation models is computation-intensive and impractical for downstream user. The demanding hardware requirement has made it impossible for most end users to perform transfer learning.
Offsite-Tuning
- privacy-preserving
- efficient transfer learning
- without access to the full model weights
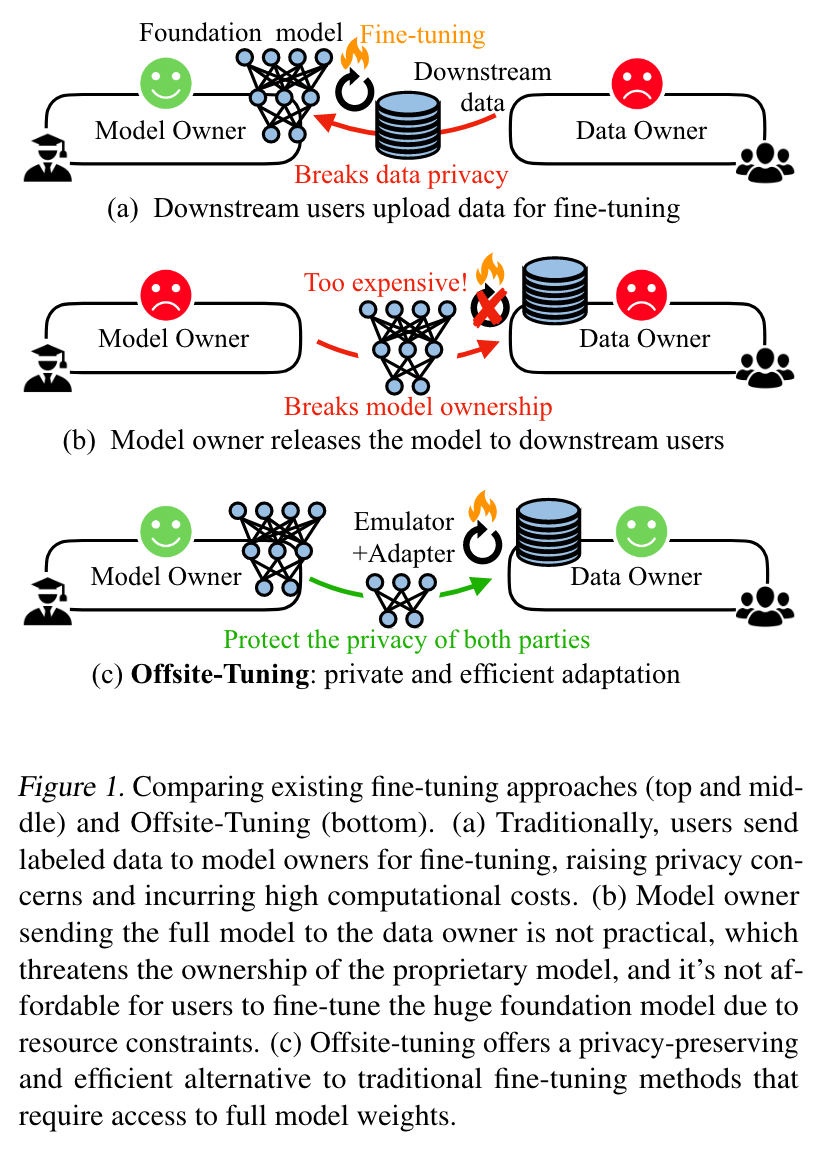
model owner:
- send a lightweight adapter
- send a lossy compressed emulator
data owner:
- fine-tunes the adapter on the downstream data with the emulator’s assistance.
- return the fine-tuned adapter to the model owner
model owner:
plugs it into the full model —> an adapted foundation model
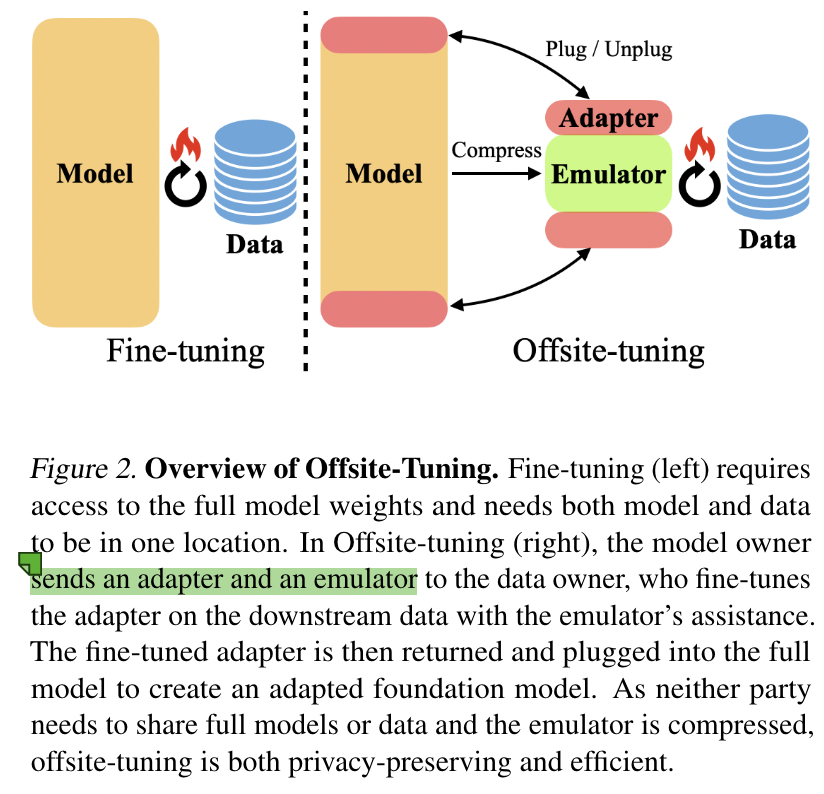
Adapter: encoding task-specific knowledge
Emulator: mimics the behavior of the rest of the full model and provides approximate gradients for fine-tuning the adapters
Parameter-Efficient Fine-tuning
updating or adding only a small number of parameters
Adapter-tuning
inserts small task-specific neural networks into transformer layers
Prefix-tuning
为输入序列预置特定任务的可调前缀向量
LoRA
将特定任务的权重更新分解为可训练的低秩向量
BitFit
更新模型的偏置向量是非常有用的,因为它们只需要为每个下游任务存储和加载少量参数,而基础模型的大部分参数可以共享。
drawbacks of PEFT:
requires the knowledge of the entire model weights, compromise either data or model owners’ privacy
resource-intensive
Federated Learning with LLM
- does not preserve the model privacy
- users can perform training on the whole model weights, which is hardly feasible for large foundation models. 用户可以对整个模型的权重进行训练,但这对大型基础模型来说几乎不可行。
Problem Definition
Foundation model: $M_{\Theta}$
Downstream datasets fine-tuning: $\Delta = argmin L(\Theta + \delta, D)$
—> $M_{\Theta} -> M_{\Theta+\Delta}$
Emulator $M^{}$ is (significantly) smaller and weaker than $M_{\Theta}$
Data owners optimize the emulator on the dataset, yielding $M^{}{\Theta*+\Delta*}$
Model owner plugs the trained weights $\Delta *$ to get $M{\Theta+\Delta*}$
Metrics
- Zero-shot performance
-> directly evaluated on downstream tasks without fine-tuning (i.e., the performance of $M_{\Theta}$). - Emulator performance
->performance of the small substitute model when fine-tuned on the downstream datasets (i.e., the performance of $M^{}_{\Theta + \Delta *}$ ) - Plug-in performance
->performance of the pre-trained foundation model with plugged-in trained weights from the substitute model (i.e.,$M_{\Theta + \Delta *}$ ). - Full fine-tuning performance
->directly fine-tune the foundation model on downstream datasets (i.e., $M_{\Theta + \Delta }$) without considering privacy.
Offsite-Tuning
将 foundation model $M$ 划分为拼接的两部分 $M=[\mathcal{A},\epsilon]$
- a small, trainable adapter $\mathcal{A}$ for downstream adaptation
- remaining portion $\epsilon$ , is to be kept frozen
对 the frozen component 压缩,得到 emulator $\epsilon *$
提供给 downstream users the adapter and emulator $[\mathcal{A},\epsilon *]$
通过更新 $\mathcal{A}$ 来进行 fine-tune,得到 $\mathcal{A}’$ ,返回给 model owner
插入到原始的模型中,$M’ = [\mathcal{A}’,\epsilon]$
data owner 的 $[\mathcal{A},\epsilon *]$ 是有损压缩,性能较低,不会破坏 model owner 的模型完整性。
Adapter Selection
select a small subset of the foundation model as the adapter, which can be trained on various downstream datasets.
只有一个模型的子集被更新,适配器必须能通用于不同的下游任务。
include both shallow and deep layers in the adapter
$M = \mathcal{A_1}\cdot \epsilon \cdot \mathcal{A_2}$
比直接在最后几层作为 adapter 效果要好,$M = \epsilon \cdot \mathcal{A}$
Emulator Compression
Emulator: provide the rough gradient directions to update the adapters while remaining similar to the original frozen component,提供粗略的梯度方向,以更新适配器,同时保持与原始冻结组件的相似性
精度不能太高,可能会泄漏原始模型的信息
layer drop-based compression method
we uniformly drop a subset of layers from the frozen component, E, and use the remaining layers as the emulator, $\epsilon *$ 从冻结组件 $\epsilon$ 中均匀地移除一个子集层,并将剩余的层作为 emulator (取emulator 的最前面和最后面的部分效果好)
进一步 apply knowledge distillation to the layer-dropped emulator,distillation process is performed using mean squared error (MSE)
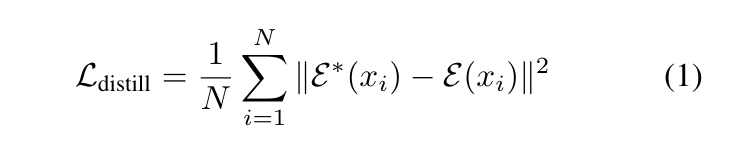
$x_i$ 是第 i 个输入样本经过前面的层 $\mathcal{A_1}$ 得到的 hidden representation
Limitation
- emulator remains huge for large models
- compute-intensive distillation techniques may be cost-prohibitive
- yet demonstrate that our method does not inadvertently result in model and data information leakage.

