FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning
Metadata
- Authors: [[Weirui Kuang]], [[Bingchen Qian]], [[Zitao Li]], [[Daoyuan Chen]], [[Dawei Gao]], [[Xuchen Pan]], [[Yuexiang Xie]], [[Yaliang Li]], [[Bolin Ding]], [[Jingren Zhou]]
- Date: [[2023-09-01]]
- Date Added: [[2023-11-03]]
- URL: http://arxiv.org/abs/2309.00363
- Topics: [[FL+LLM]]
- Tags: #Computer-Science—Machine-Learning, #/unread, #待读, #zotero, #literature-notes, #reference
- PDF Attachments
Abstract
LLMs have demonstrated great capabilities in various NLP tasks. Different entities can further improve the performance of those LLMs on their specific downstream tasks by fine-tuning LLMs. When several entities have similar interested tasks, but their data cannot be shared because of privacy concerns regulations, federated learning (FL) is a mainstream solution to leverage the data of different entities. However, fine-tuning LLMs in federated learning settings still lacks adequate support from existing FL frameworks because it has to deal with optimizing the consumption of significant communication and computational resources, data preparation for different tasks, and distinct information protection demands. This paper first discusses these challenges of federated fine-tuning LLMs, and introduces our package FS-LLM as a main contribution, which consists of the following components: (1) we build an end-to-end benchmarking pipeline, automizing the processes of dataset preprocessing, federated fine-tuning execution, and performance evaluation on federated LLM fine-tuning; (2) we provide comprehensive federated parameter-efficient fine-tuning algorithm implementations and versatile programming interfaces for future extension in FL scenarios with low communication and computation costs, even without accessing the full model; (3) we adopt several accelerating and resource-efficient operators for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study. We conduct extensive experiments to validate the effectiveness of FS-LLM and benchmark advanced LLMs with state-of-the-art parameter-efficient fine-tuning algorithms in FL settings, which also yields valuable insights into federated fine-tuning LLMs for the research community. To facilitate further research and adoption, we release FS-LLM at https://github.com/alibaba/FederatedScope/tree/llm.
Zotero links
Highlights and Annotations
- [[FederatedScope-LLM A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning - Comment Source code httpsgithub.comalibabaFederatedScopetreellm]]
Note
不同的用户想要进一步 on their specific downstream tasks by fine-tuning 提高 LLMs 的性能
When several entities have similar interested tasks, but their local data cannot be shared directly because of privacy concerns regulations
package FederatedScope-LLM (FS-LLM)
adapt pre-trained LLMs to specific domains by tuning modules with limited trainable parameters (denoted as adapters)
联邦学习 -LLM 存在的问题:
- No existing FL package contains comprehensive and efficient implementations of LLM fine-tuning algorithms
- Fine-tuning LLMs in FL is still computationally expensive on the client side, even with the parameter-efficient fine-tuning (PEFT) algorithms
- pre-trained LLMs let clients conduct federated fine-tuning without accessing the full model (e.g., closed source LLMs)
- unclear whether the existing algorithms for solving advanced FL problems, such as personalized FL (pFL) and federated hyper-parameter optimization (FedHPO) are still effective with different federated fine-tuning algorithms for LLMs
- FS-LLM 将来自不同领域、异构的各种联合微调数据集和一套相应的评估任务打包
- FS-LLM comprehensive federated fine-tuning algorithms,低通信和计算开销,支持 clients 可以访问 LLM 以及 LLM closed source 的场景
- FS-LLM 为 LLM 配备优化的联合微调训练范式,以实现可定制的效率提升
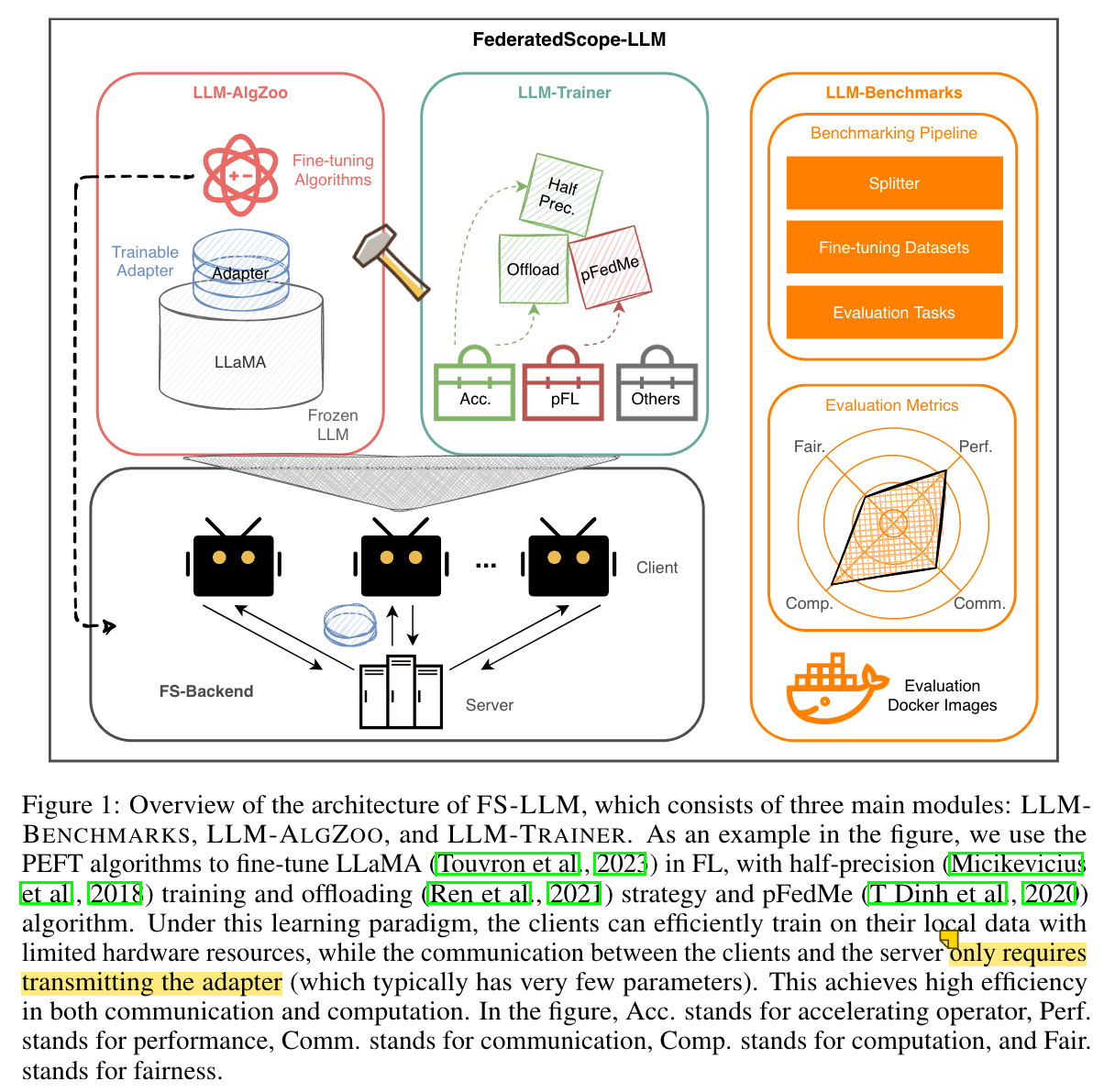
PEFT algorithms:
- LoRA
- prefix-tuning
- P-tuning
- prompt tuning
reduce memory consumption, training time, and communication cost for fine-tuning LLMs.
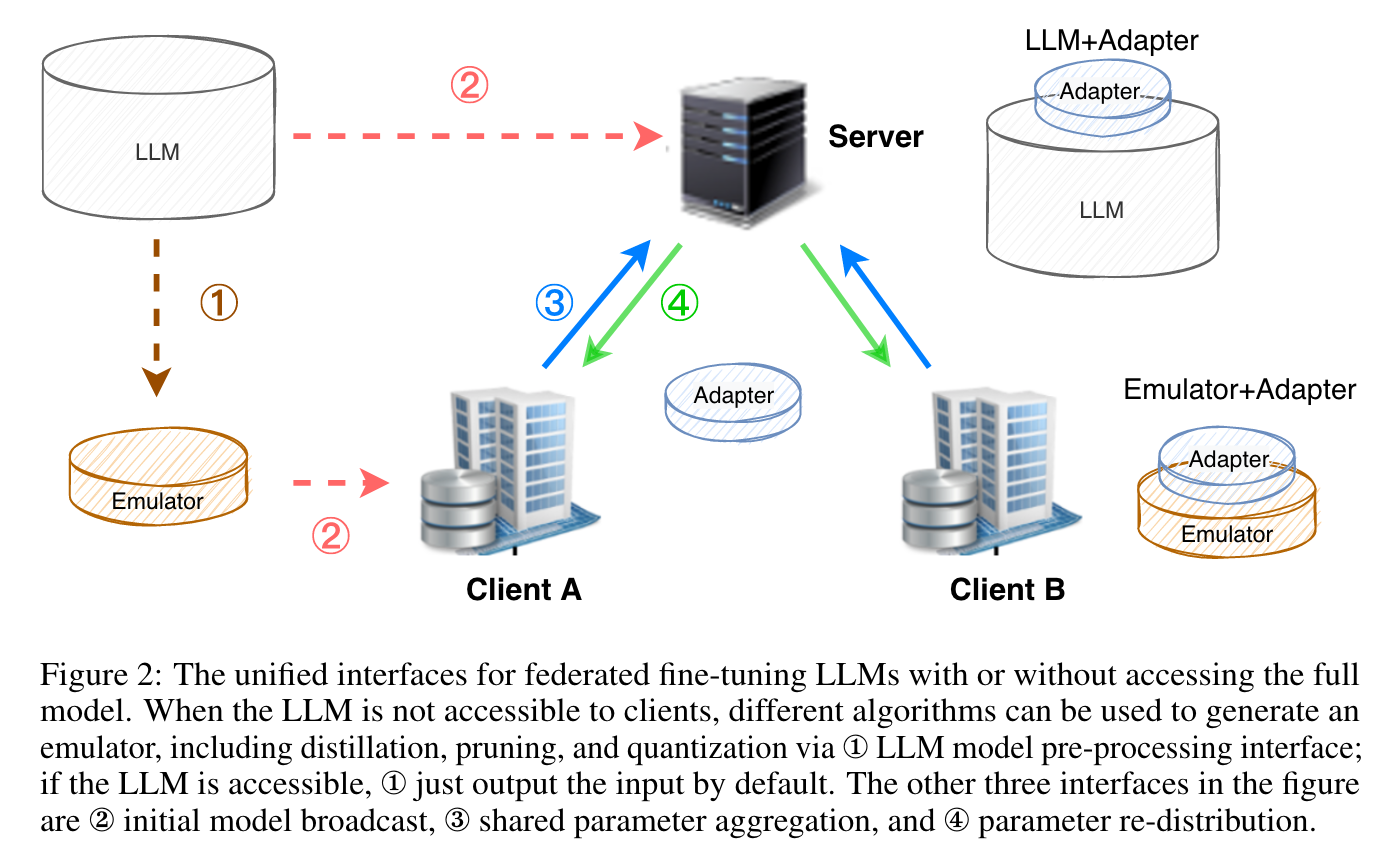
privacy-preserving fine-tuning algorithm, offsite-tuning, clients only tune small adapters based on a distilled model from a full LLM
However, fine-tune a small number of parameters of LLMs, they can still be computationally expensive for some clients.
FS-LLM adopts DeepSpeed’s ZeRO, Pytorch’s data parallelism, model quantization to accelerate the local fine-tuning process
For closed-source LLMs,the model providers can compress the LLM into an emulator by implementing a distillation function with the model pre-processing interface
For open-source LLMs, which are accessible, the pre-processing interface just returns the original LLM.