#LLM #Survey
Metadata
- Authors: [[Tao Fan]], [[Yan Kang]], [[Guoqiang Ma]], [[Weijing Chen]], [[Wenbin Wei]], [[Lixin Fan]], [[Qiang Yang]]
Abstract
Large Language Models (LLMs), such as ChatGPT, LLaMA, GLM, and PaLM, have exhibited remarkable performances across various tasks in recent years. However, LLMs face two main challenges in real-world applications. One challenge is that training LLMs consumes vast computing resources, preventing LLMs from being adopted by small and medium-sized enterprises with limited computing resources. Another is that training LLM requires a large amount of high-quality data, which are often scattered among enterprises. To address these challenges, we propose FATE-LLM, an industrial-grade federated learning framework for large language models. FATE-LLM (1) facilitates federated learning for large language models (coined FedLLM); (2) promotes efficient training of FedLLM using parameter-efficient fine-tuning methods; (3) protects the intellectual property of LLMs; (4) preserves data privacy during training and inference through privacy-preserving mechanisms. We release the code of FATE-LLM at https://github.com/FederatedAI/FATE-LLM to facilitate the research of FedLLM and enable a broad range of industrial applications.
- 笔记
- Zotero links
- PDF Attachments
Note
Challenges
- training LLMs consumes vast computing resources
- requires a large amount of high-quality data
Large Language Models
ChatGPT is fine-tuned from the generative pretrained trasformer GPT-3.5, applies reinforcement learning from human feedback(RLHF)
LLMs:
encoder-decoder or encoder-only large language models
Bert is the representative of encoder-only large language models.
decoder-only large language models
GPTs is the representative of decoder-only large language models.
LLaMA
OPT
PaLM
BLOOM
FATE-LLM System Design
parameter-efficiency fine-tuning (PEFT)
- Adapter Tuning
- Prompt Tuning
- Knowledge Distillation(KD)
- Quantization
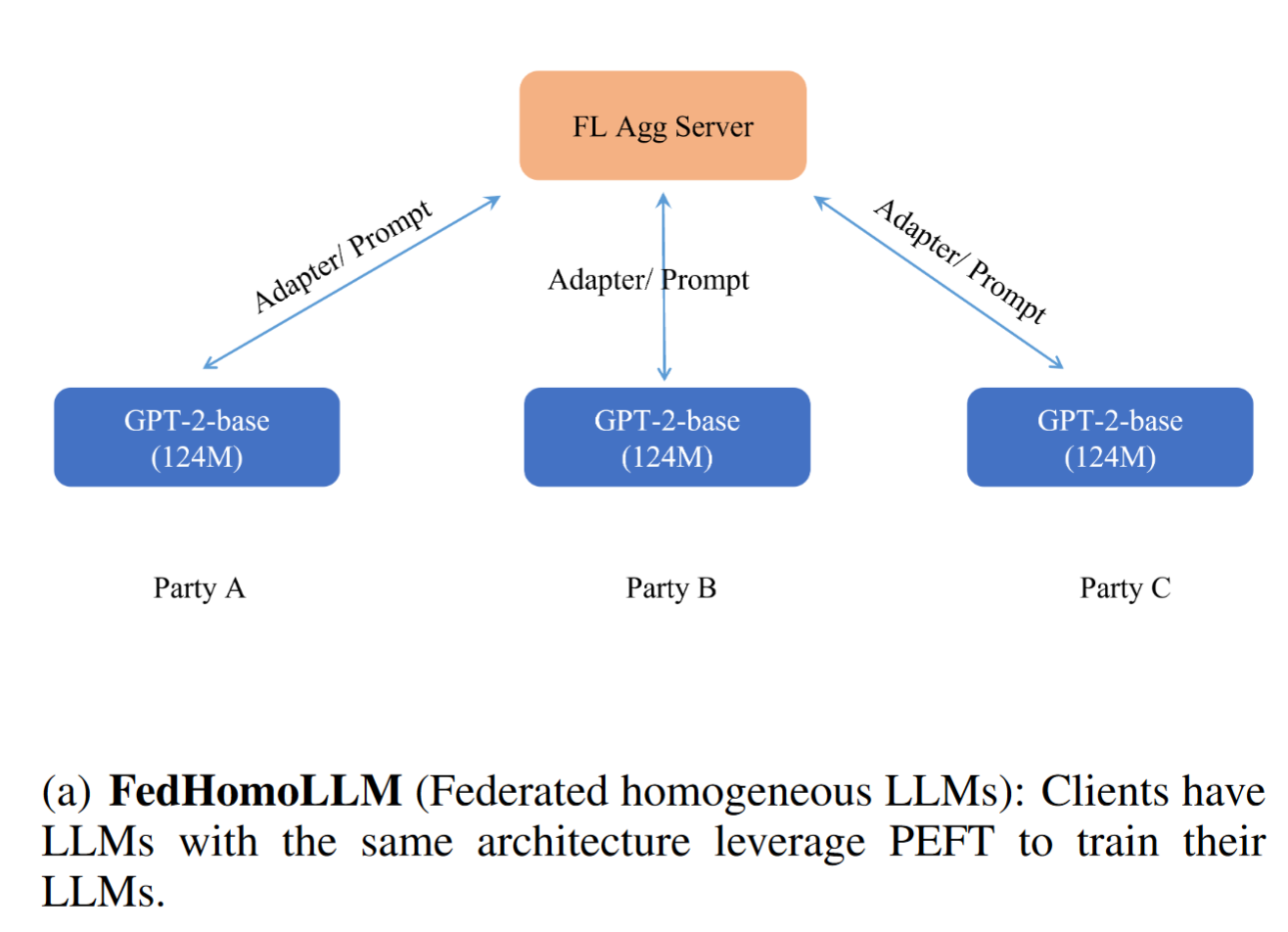
FedHomoLLM
PEFT techniques to train clients’ LLMs with the same architecture and size
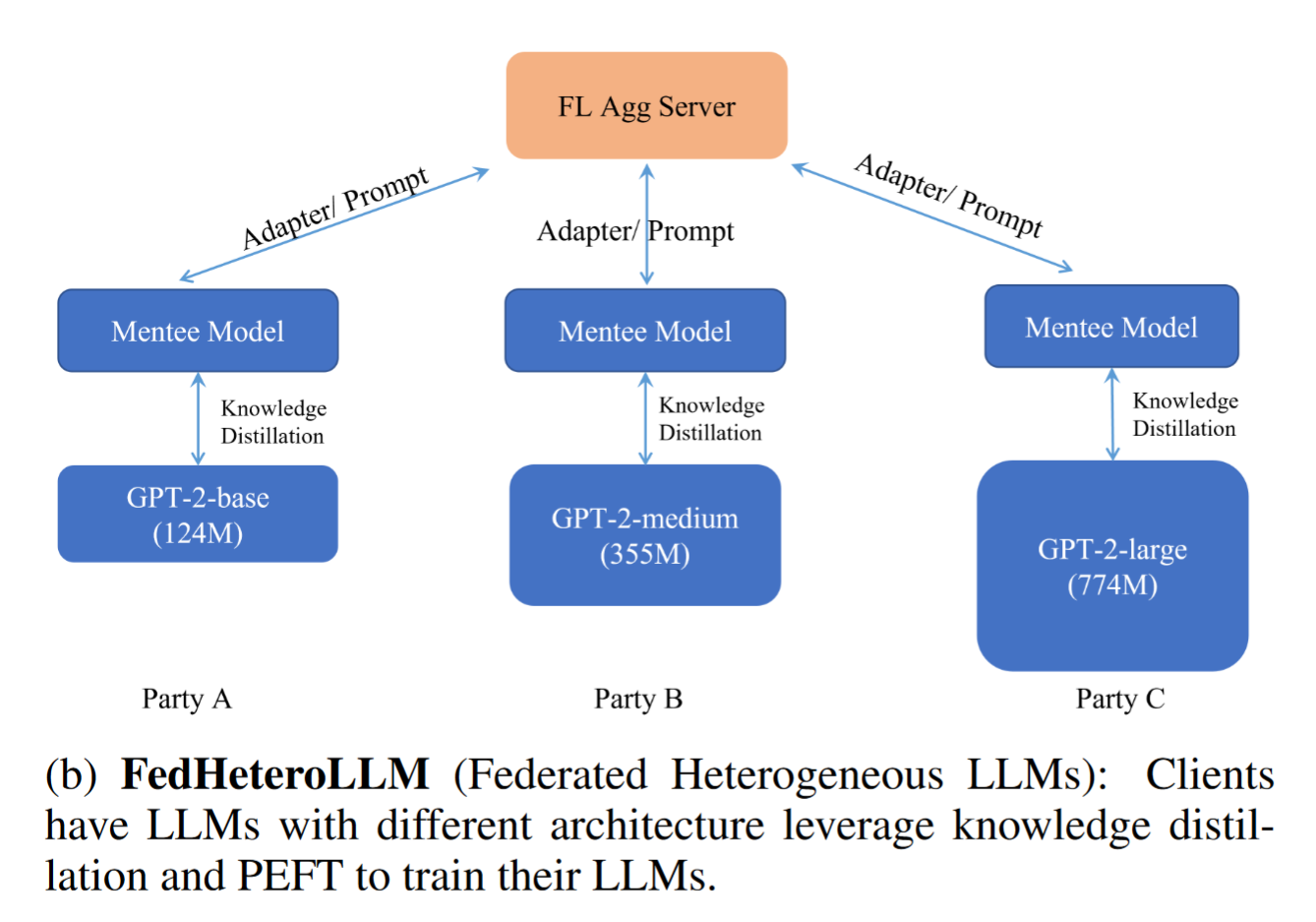
FedHeteroLLM
knowledge distillation (KD) and PEFT techniques to deal with the FL scenario where FL clients own LLMs of different sizes
each client in FedHeteroLLM leverages KD to learn a mentee model from its local pre-trained LLM.
all clients send adaptor or prompt parameters to the server for secure aggregation
the server dispatches the aggregated model to all clients for the next round of training
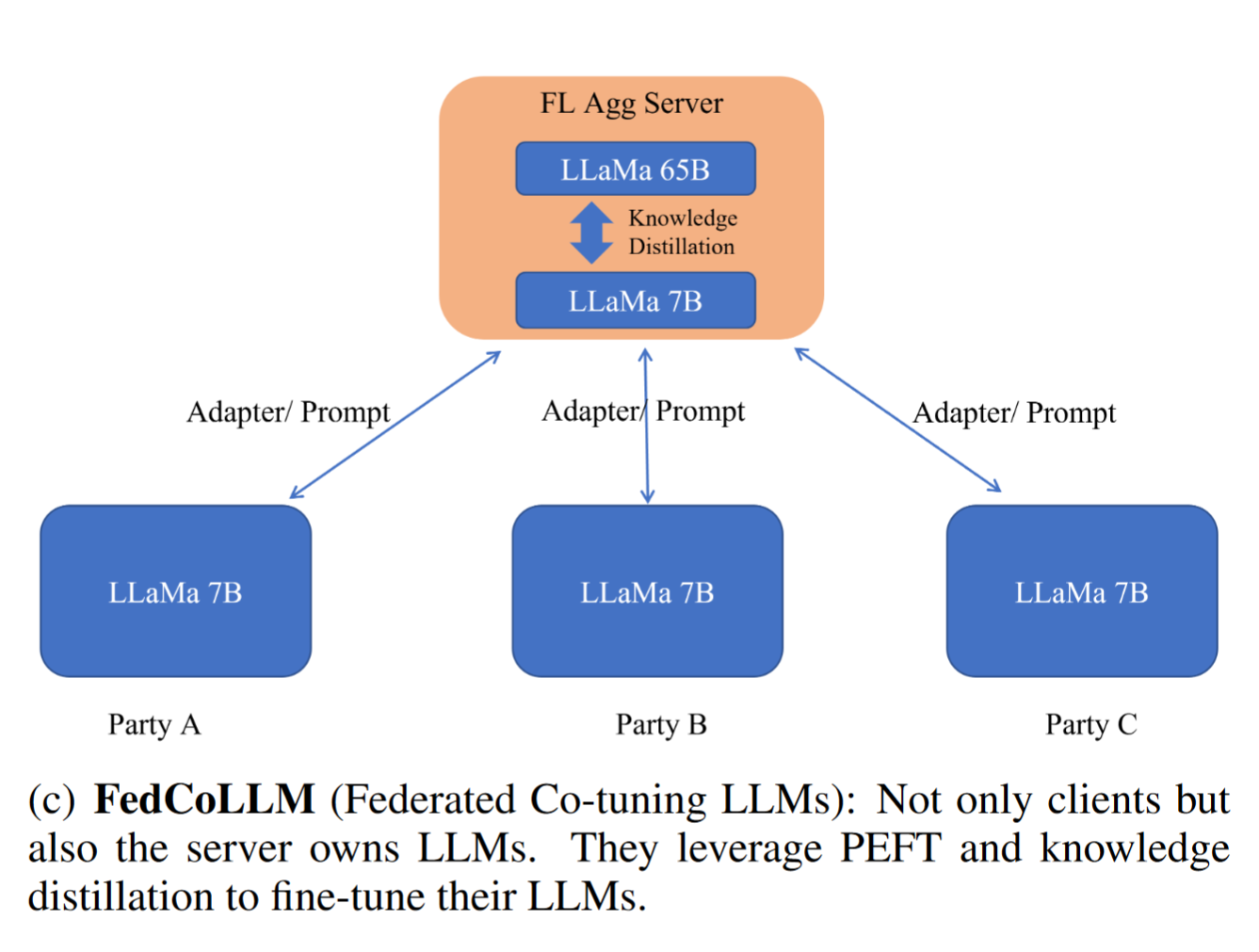
FedCoLLM(Federated Co-tuning LLM)
使用从 server 中蒸馏得到的模型来初始化 clients 的 local models,比随机初始化客户端模型能够获得更好的 global model.
客户端的 local LLMs 提供的 domain knowledge 使得 server 能够在更大的 LLMs 继续训练
共同发展 co-evolve the LLMs of the server and clients.
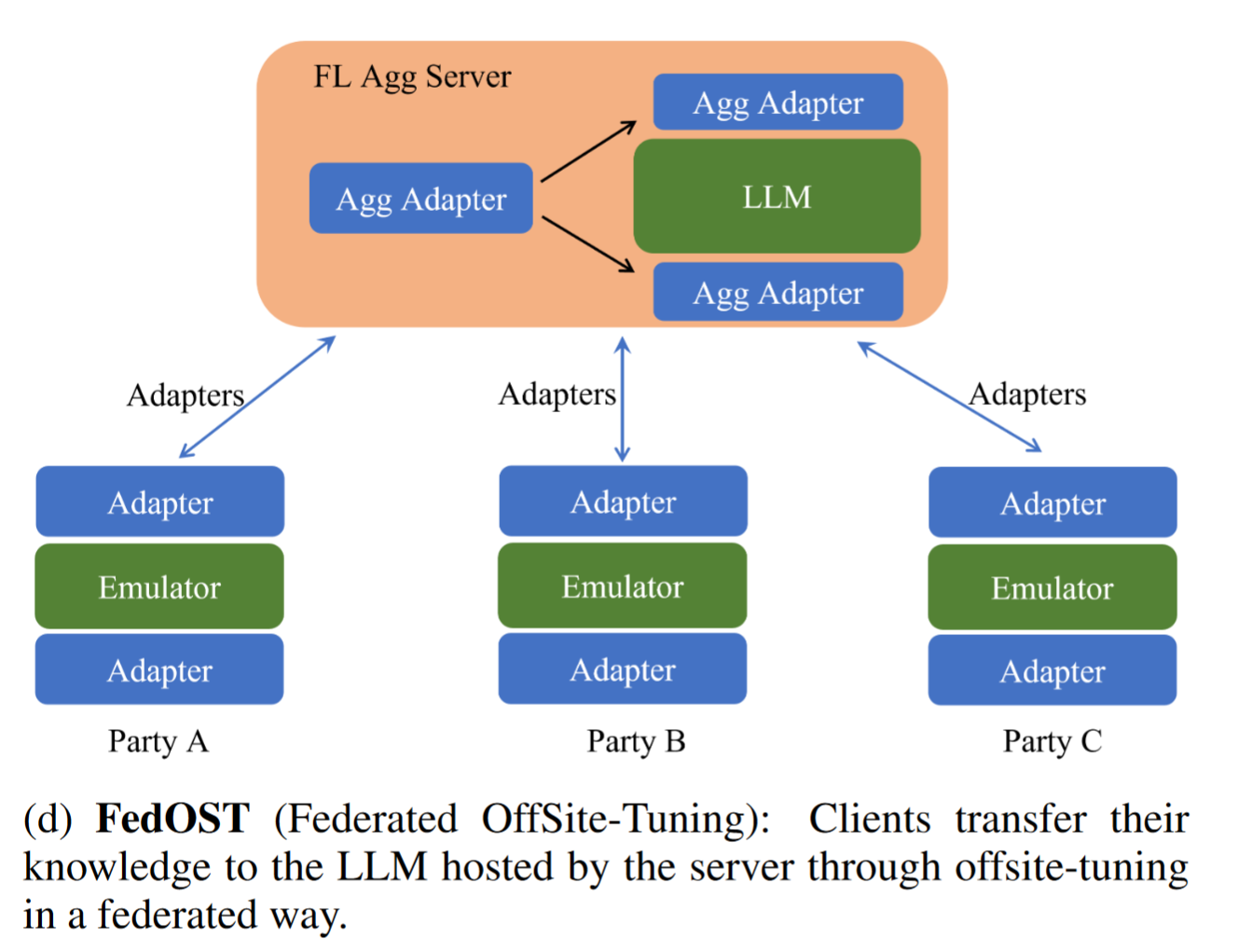
FedOST (Federated OffSite-Tuning)
Offsite-Tuning
a privacypreserving and efficient transfer learning framework
adapt an LLM to downstream tasks without access to the LLM’s full weights
server sends two adaptors and an emulator of its LLM to a client,
client: frozen emulator and using client’s domain-specific data fine-tune adaptors
client sends adaptors back to the server
server plugs adaptors into LLM to form an adapted LLM for the client.
potential to protect the client’s data privacy and the server’s model property.
FedOST
multiple clients collaboratively train two global adaptors
FedOST enhances data privacy by adopting secure aggregation