DaFKD: Domain-Aware Federated Knowledge Distillation
#Federated-Learning #GAN #Knowledge-Distillation #CVPR
Metadata
- Item Type: [[Article]]
- Authors: [[Haozhao Wang]], [[Yichen Li]], [[Wenchao Xu]], [[Ruixuan Li]], [[Yufeng Zhan]], [[Zhigang Zeng]]
- Date Added: [[2023-11-03]]
- Topics: [[LLM+KD]]
- PDF Attachments
Abstract
Federated Distillation (FD) has recently attracted increasing attention for its efficiency in aggregating multiple diverse local models trained from statistically heterogeneous data of distributed clients. Existing FD methods generally treat these models equally by merely computing the average of their output soft predictions for some given input distillation sample, which does not take the diversity across all local models into account, thus leading to degraded performance of the aggregated model, especially when some local models learn little knowledge about the sample. In this paper, we propose a new perspective that treats the local data in each client as a specific domain and design a novel domain knowledge aware federated distillation method, dubbed DaFKD, that can discern the importance of each model to the distillation sample, and thus is able to optimize the ensemble of soft predictions from diverse models. Specifically, we employ a domain discriminator for each client, which is trained to identify the correlation factor between the sample and the corresponding domain. Then, to facilitate the training of the domain discriminator while saving communication costs, we propose sharing its partial parameters with the classification model. Extensive experiments on various datasets and settings show that the proposed method can improve the model accuracy by up to 6.02% compared to state-of-the-art baselines.
Zotero links
Notes
Federated Distillation (FD): aggregating multiple diverse data
Existing FD: treat these models equally, merely computing the average soft predictions.
fault: does not take the diversity across all local models into account. (对 knowledge 的 average aggregation,没有考虑本地模型的多样性). —> leading to the degrade performance of the aggregated model
Non-iid: –> model parameters on different clients are optimized towards diverse directions
FD(Federated Distillation) is proposed to tackle the non-iid problem, aggregating only the output soft predictions.
- model diversity
- bring errors when some clients give wrong predictions
Contributions:
- Domain knowledge aware federated distillation method (DaFKD),根据 distillation sample and the training domain 的相关性来确定模型的重要性
- Treats the local data in each client as a specific domain,识别每个模型对于蒸馏样本的重要性,优化来自不同模型的 ensemble of the soft predictions,减小 wrong soft predictions 的影响
- Domain discriminator for each client, identify the correlation factor between the sample and the corresponding domain. (high importance <– correlation factor is significant)
样本在被包含在 domain 中时,模型会做出更正确的选择
Related Work
huge diverse of the parameters of local models across clients(不同客户的本地模型参数存在巨大差异),local models are optimized to different directions.
Prior works:
- Adding a regularization item in the local objective function such that the divergence of the local model is constrained by the global model. (局部目标函数添加正则化项,使得局部受到全局的约束)
- reducing the variance of local gradient to align the diverse local update.(减少局部梯度的方差以对齐不同的局部更新)
Federated Distillation
- Transfer the knowledge from multiple local models to the global model (将知识从多个局部模型转移到全局模型)
- Aggregating multiple local models to combined models, and then distilling the combined models into one global model (先将clients的模型权重聚合为多个联合模型,然后对联合模型蒸馏,得到全局模型)
但是,上述方法都需要 public dataset - Data generated by the generative models (data-free way)
但是,上述方法直接 average soft predictions,没有考虑模型的多样性 model diversity,可能限制模型的性能。 - 本文考虑 domain knowledge,在 ensemble soft predictions 的时候考虑不同模型的重要性
Methodology
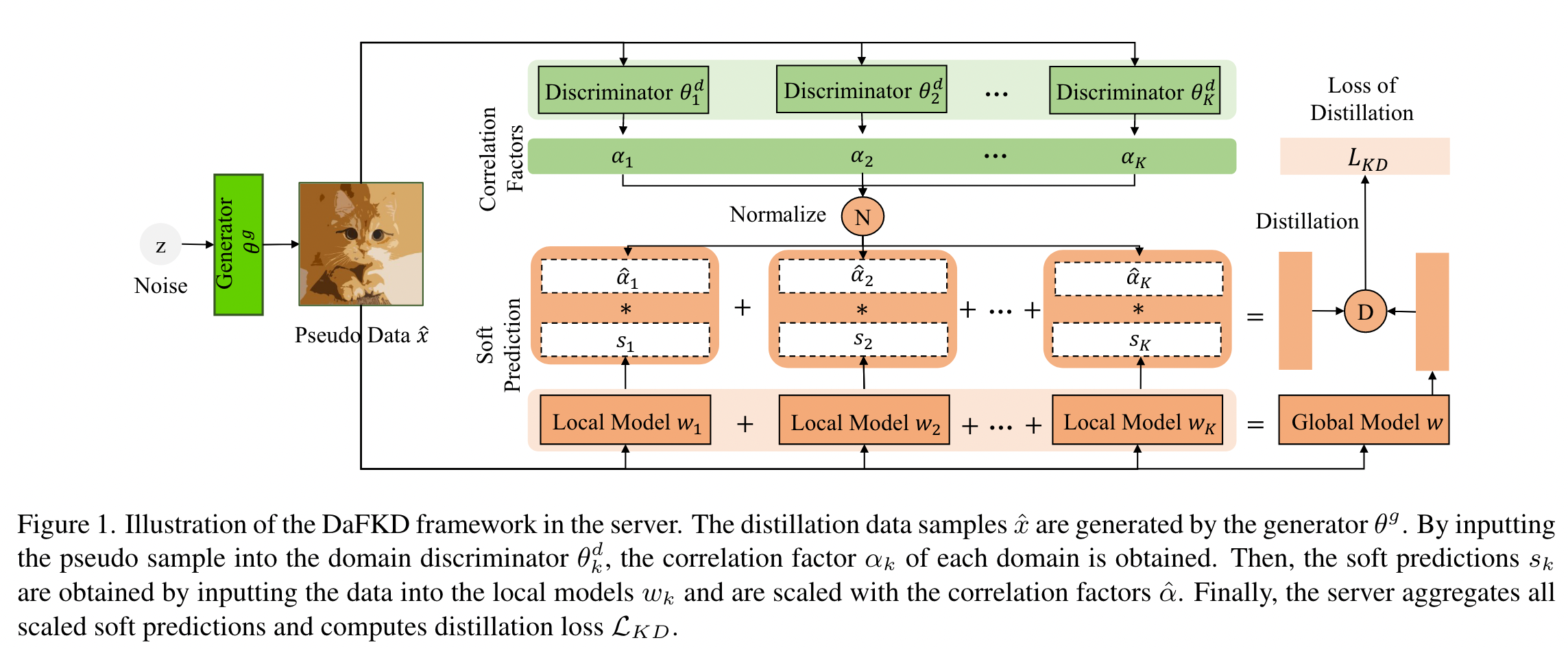
利用 domain discriminator 识别每个 local model 的 importance
local training:
- private dataset
- 以对抗的方式生成 global data。
共享 discriminator 的部分参数给 target classification model。
Objective function:
$L_k(w)$ is local loss of the $k-th$ client
$L_{CE}$ is the cross-entropy loss between the prediction and the ground truth labels.
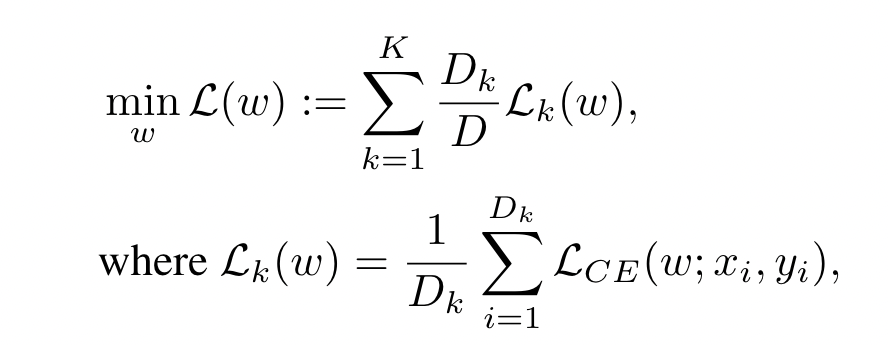
当 sample 在 domain 内部的时候,能够有较高的概率做出正确的 prediction
量化 domain 和给定 sample 之间的相关性 correlation
对抗生成网络:
Discriminator 用来区分生成的数据是否是从目标数据集的分布中采样的
本文训练的 discriminator 用来计算局部数据集与蒸馏样本的相关性
为每个客户端 k 设定 personalized discriminator $\theta_k^d$
为每个 client 使用全局共享的 generator $\theta^g$
- 客户端 k pulls the generator $\theta^g$ ,从分布 $p_z$ 中 sample noise,生成伪数据集 $\hat D_k$
- 客户端 k 给 private dataset $D_k$ 标签 positive,给 pseudo dataset $\hat D_k$ 标签 negative
- 客户端 k 训练自己的 domain discriminator $\theta_k^d$ (判别器)
训练 discriminator 的损失函数如下:
$f(\theta_k^d;x_i)$ 代表 $x_i$ 是真实数据的概率
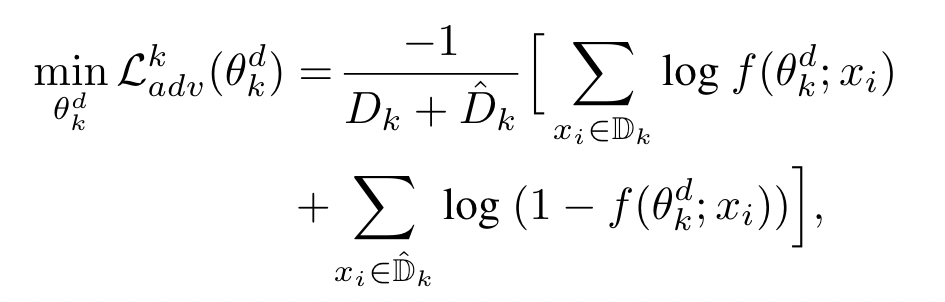
在训练完 discriminator 之后, client 训练 generator $\theta_k^g$ ,最大化 loss function 如下:
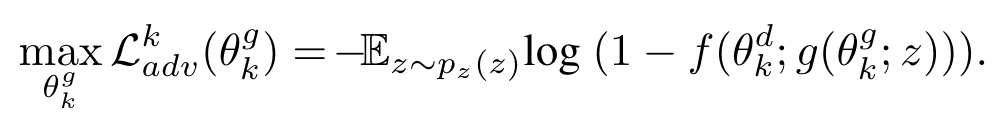
在训练完 local generator $\theta_k^g$ 之后,server 收到参与方 clients 的 generator 来聚合得到一个新的 global generator $\theta^g$
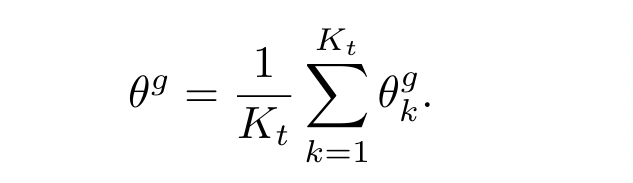
Global perspective, adversarial loss function:
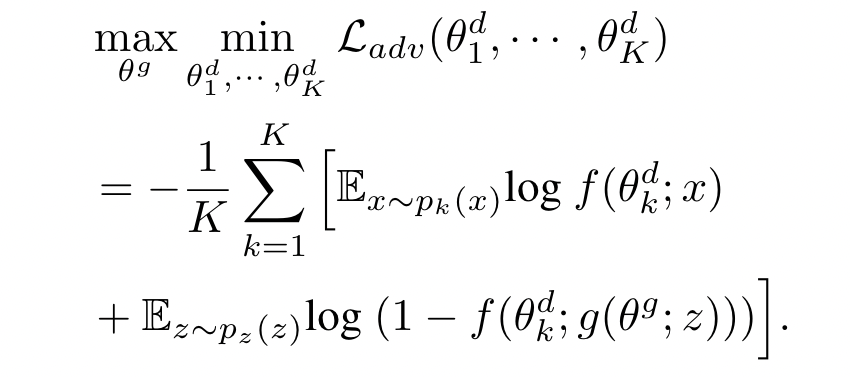
local generator 上传到 server 的时候可能会泄漏信息,
prior works
- generating feature maps instead of the original data
- differential privacy
This paper
- allowing the generator to output intermediate features
Domain-aware Federated Distillation
Round t, client k 在本地训练 $w_t^k$ ,将 local model $w_t^k$ 以及 domain discriminator $\theta_k^d$ 发送给 server
server 对 local models 平均聚合
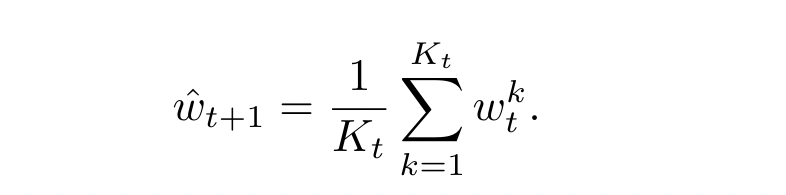
server 使用 global generator $\theta^g$ 生成 pseudo dataset $\hat D^g$ 作为 distillation data
对于每个 distillation sample $x_i\in \hat D^g$ ,server 根据 domain discriminator $\theta_k^g$ 计算每个 local model $w_t^k$ 的重要性 $\alpha_{k,i} = f(\theta_k^{\theta};x_i)$ ,并 normalize probability
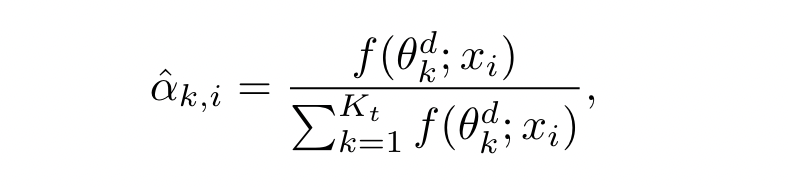
- server 讲 pseudo sample $x_i$ 输入给每个 local model $w_t^k$ 和 average model $\hat w_{t+1}$
- server 使用 importance $\hat \alpha_{k,i}$ 应用 ensemble knowledge distillation 来获取 global model $w_{t+1}$
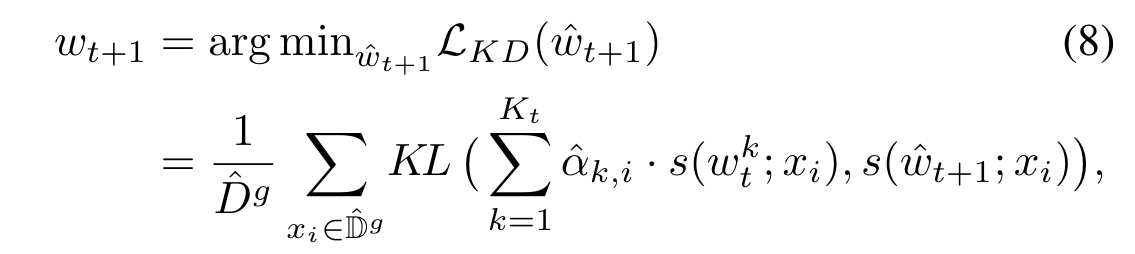
KL(·) is to compute the Kullback-Leibler divergence (KL-divergence)
Discussion
每个 client 都可以获取 global generator,当 noise seed 一致时候,可以在每个 client 生成共享的蒸馏数据集
为了保护隐私,每个client 可以直接上传 soft predictions weighted by importance to the server
Partial Parameters Sharing
domain discriminator 是由 local dataset 训练得到,性能可能由于 local dataset 的size 过小而恶化
multi-task learning ,在不同任务之间共享 encoder 可以相互促进,因此共享 discriminator $\theta_k^d$ 的部分参数给 classification model $w^k$
共享层的好处是,discriminator 也上传到服务器的时候,可以降低通信成本
This paper 在两个模型中,共享 the front model layers (前面的层都是用来提取特征 extract features)
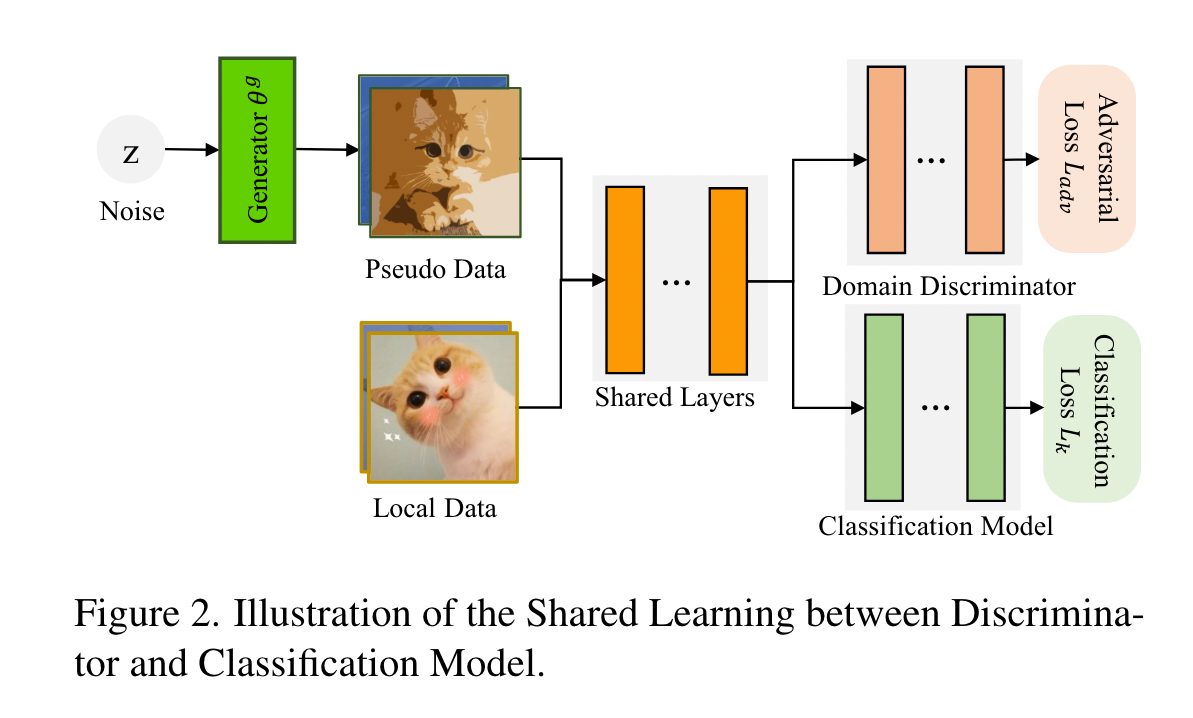
discriminator and classification model 以一种联合的方式训练:
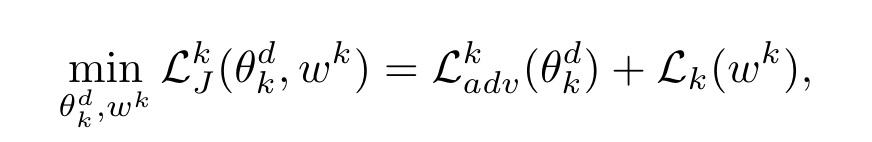
Algorithm:

- 每一轮都要训练生成器、判别器,并要同 local model 一起发送给 server ,一方面会导致每轮的通信量比较大,另一方面会导致隐私问题(没有对 local model 做保护)
- 给每个 client 的 local model 一个 importance,从判别器对 pseudo sample $x_i$ 的判定结果,是否类似某个 local domain 来赋值
- server 本是没有模型的,是对所有的 local model parameters 聚合后的模型,作为 global model 来蒸馏
- 重要性可以由 server 计算(需要上传 discriminator),也可以由 client 计算(不需要上传 discriminator)

