Ensembled CTR Prediction via Knowledge Distillation
Metadata
- Authors: [[Jieming Zhu]], [[Jinyang Liu]], [[Weiqi Li]], [[Jincai Lai]], [[Xiuqiang He]], [[Liang Chen]], [[Zibin Zheng]]
笔记
Zotero links
- PDF Attachments
2020_Ensembled CTR Prediction via Knowledge DistillationZhu_.pdf
- Cite key: zhuEnsembledCTRPrediction2020
Note
click-through rate (CTR) prediction
currently:complex network architectures,slow down online inference and hinder its adoption in real-time applications.
Contributions:
- Teacher gating
-teacher selection to learn from multiple teachers adaptively. - Early stopping by distillation loss
-alleviates overfitting and enhances utilization of validation data
Goal:
train a unified model from different teacher models
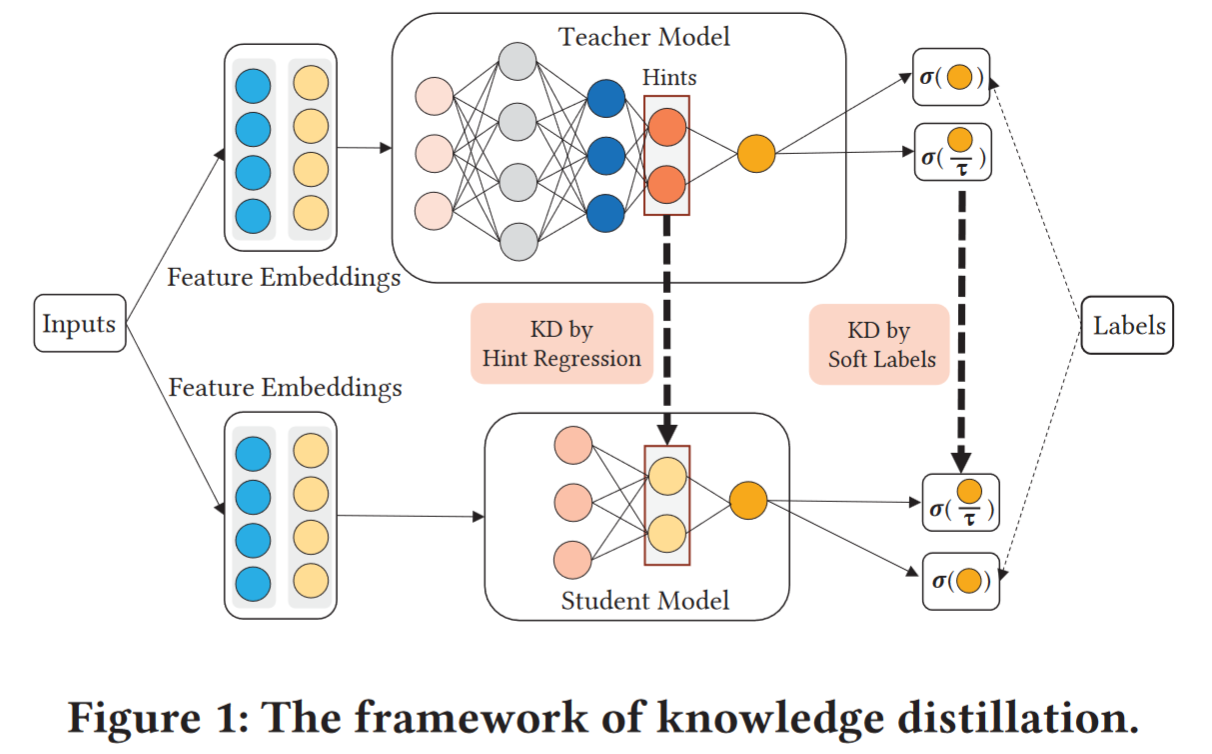
Distillation from One Teacher
Soft label
The probability outputs of the teacher model (i.e., soft labels), which can help to convey the subtle difference between two samples and generalize better than directly learning from hard labels.
KD by soft labels
$z_T$ and $z_S$ denote the logits of both models
$\tau$ is temperature (温度参数),to produce a softer probability distribution of labels.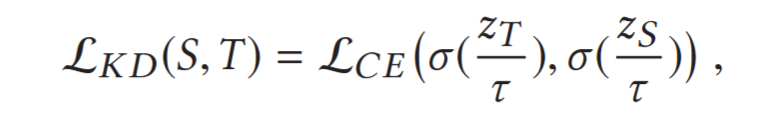
Combines the supervision of hard labels $y$ and soft labels.
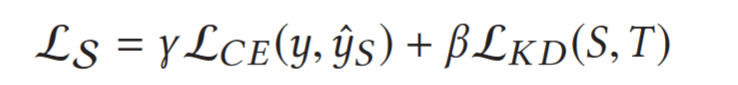
$L_{CE}$ is the cross entropy function as follows.
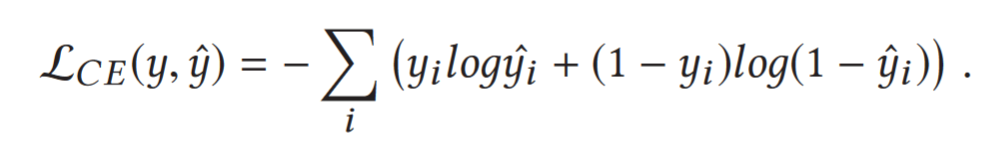
Hint regression
learning from representations
intermediate representation vector from a teacher’s hidden layer
the student’s representation vector $v_S$ and force $v_S$ to approximate $v_T$ with linear regression.
$W$ is transformation matrix,因为这两个向量的 size(维度) 可能不同
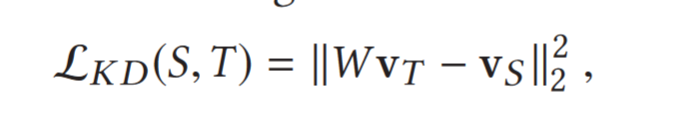
Distillation from Multiple Teachers
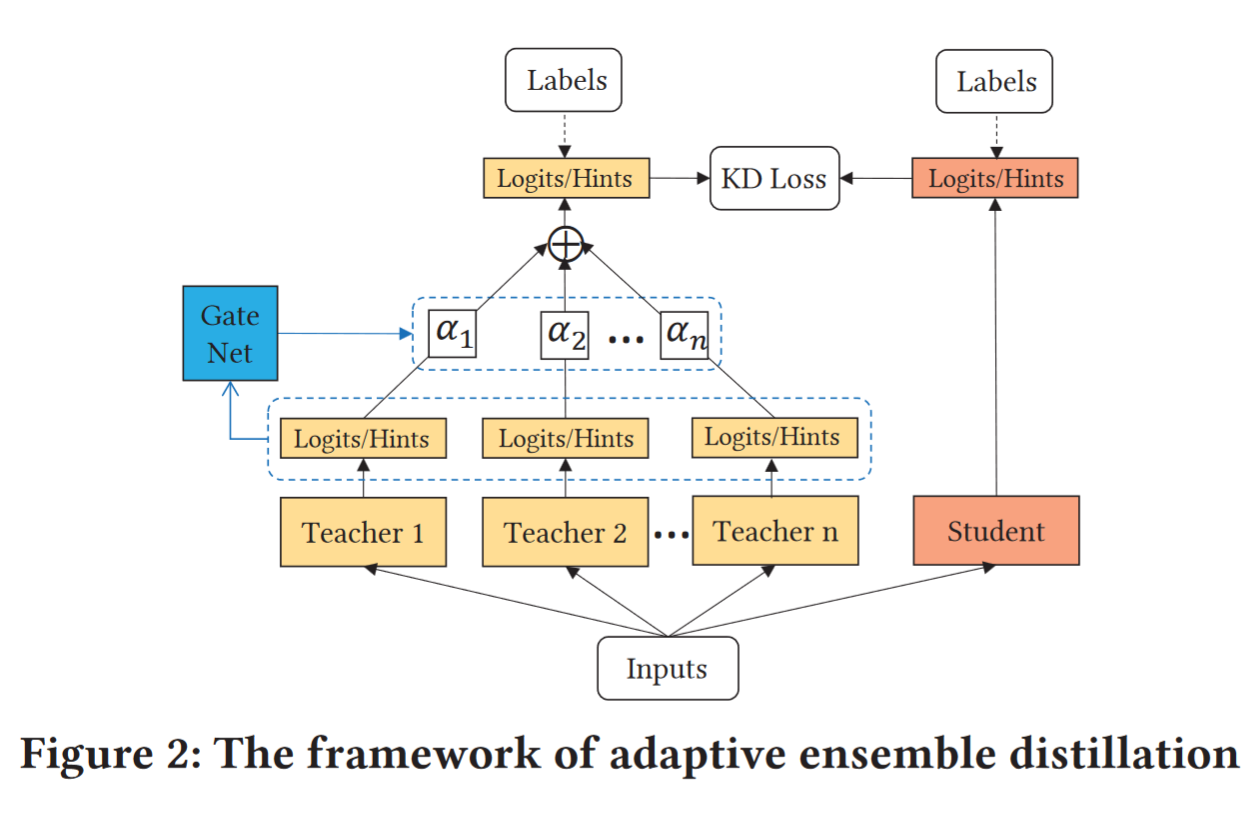
we extend our KD framework from a single teacher to multiple teachers.
average individual teacher models to make a stronger ensemble teacher
cons:not all teachers can provide equally important knowledge on each sample
solution:to dynamically adjust their contributions
Adaptive distillation loss:
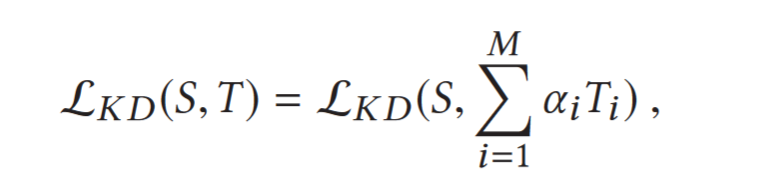
M is the num of teachers, $\alpha_i$ is the contribution of the teacher i.
Teacher gating network
learn αi dynamically and make it adaptive to different data samples
employ a softmax function as the gating function
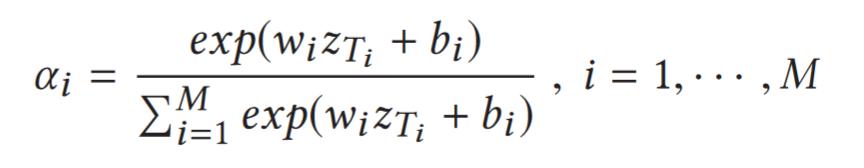
${w_i,b_i}_{i=1}^M$ are the parameters to learn.
uses all teachers’ outputs to determine the relative importance of each other.
Training
pre-train
train the teacher and student models in two phases
co-train
both teacher and student models are trained jointly while the back-propagation of the distillation loss is unidirectional so that the student model learns from the teacher, but not vice versa.
Early stopping via distillation loss.
use the distillation loss from the teacher model as the signal for early stopping
Early stopping is adopted when stop improving in three consecutive epochs.
Experiments
soft label + pre-train 的性能要优于使用 hard label 或者 co-train 的性能
Teacher 数量越多,训练效果越好,但是这个增量或者加速度逐渐变小
Teacher models 在不同数据集上训练,比使用不同网络结构的 teacher model 训练出来的 student model 的效果好

