Metadata
Tags: #Personalizaion #Knowledge-Distillation
Authors: [[Huancheng Chen]], [[Chianing Wang]], [[Haris Vikalo]]
Abstract
Heterogeneity of data distributed across clients limits the performance of global models trained through federated learning, especially in the settings with highly imbalanced class distributions of local datasets. In recent years, personalized federated learning (pFL) has emerged as a potential solution to the challenges presented by heterogeneous data. However, existing pFL methods typically enhance performance of local models at the expense of the global model’s accuracy. We propose FedHKD (Federated Hyper-Knowledge Distillation), a novel FL algorithm in which clients rely on knowledge distillation (KD) to train local models. In particular, each client extracts and sends to the server the means of local data representations and the corresponding soft predictions – information that we refer to as “hyper-knowledge”. The server aggregates this information and broadcasts it to the clients in support of local training. Notably, unlike other KD-based pFL methods, FedHKD does not rely on a public dataset nor it deploys a generative model at the server. We analyze convergence of FedHKD and conduct extensive experiments on visual datasets in a variety of scenarios, demonstrating that FedHKD provides significant improvement in both personalized as well as global model performance compared to state-of-the-art FL methods designed for heterogeneous data settings.
- 笔记
- Zotero links
- PDF Attachments
Chen 等 - 2023 - THE BEST OF BOTH WORLDS ACCURATE GLOBAL AND PERSO.pdf
- Cite key: chenBESTBOTHWORLDS2023a
Note
personalized federated learning (pFL) 用于解决数据异构带来的问题。
但现有的 pFL方法以牺牲 global model 准确率的前提下,增强 local models 的性能
FedHKD (Federated Hyper-Knowledge Distillation)
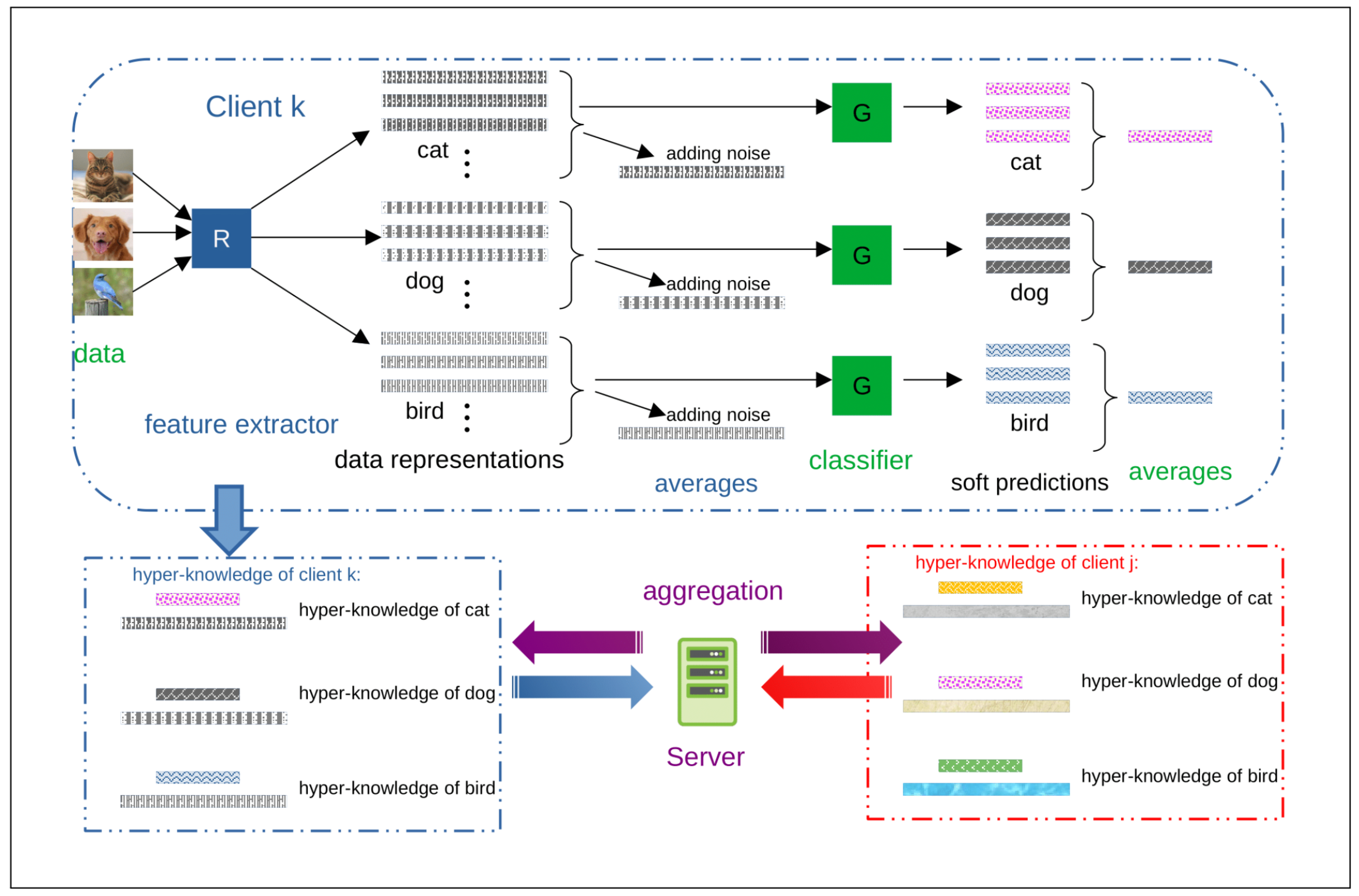
Client:
- Extract the means of local data representations
- Send the corresponding soft predictions
Server:
- Aggregation
- Broadcast.
Difference:
大多数基于KD的方案都依赖于一个公共数据集,限制了在实际中的使用。
imporvement:FedHKD does not rely on a public dataset
hyper-knowledge:
- mean representations
- the corresponding mean soft predictions
privacy: differential privacy via the Gaussian mechanism
Knowledge distillation (KD) with a public dataset:
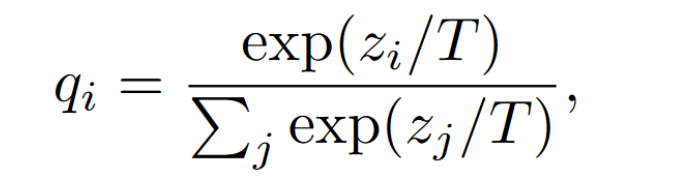
$z_i$ is the $i^{th}$ output of a data sample.
$q_i$ is the $i^{th}$ soft prediction.
$T$ is the temperature parameter.public datasets consumes communication and memory resources.
Feature Extractor and Classifier
models:
- a feature extractor
translating the input raw data (i.e., an image) into latent space representation - a classifier
mapping representations into categorical vectors
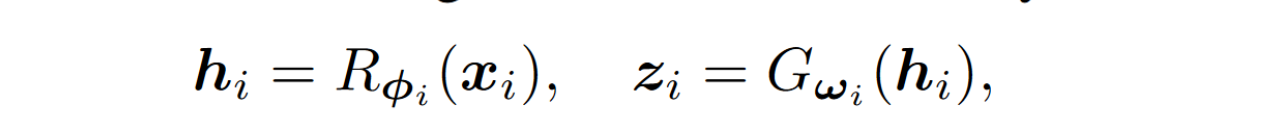
$x_i$ is the raw data of client i
$R_{\phi_i}$ is the embedding functions of feature extractor
$G_{w_i}$ is the classifier
$h_i$ is the representation vector
$z_i$ is the categorical vector
Evaluating and Using Hyper-Knowledge.
client i: mean latent representation of class j
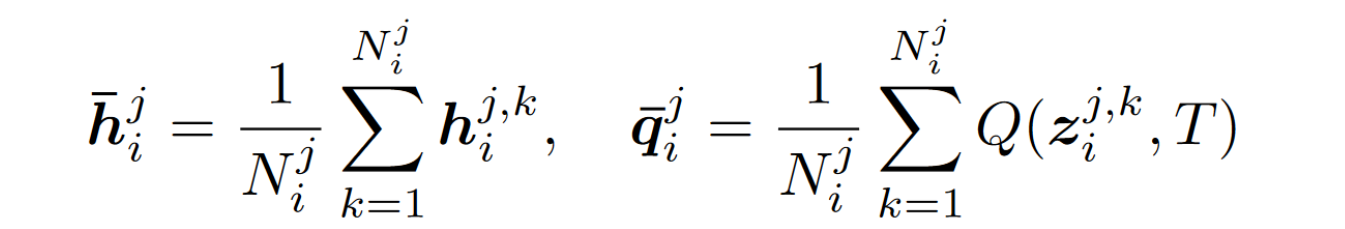
$Q(*,T)$ is the soft target function
$h_i^{j,k}$ : data representation of the $i^{th}$ client’s $k^{th}$ sample with label $j$
$z_i^{j,k}$ : prediction of the $i^{th}$ client’s $k^{th}$ sample with *label $j$
client $i$ hyper-knowledge of class $j$: $\mathcal{K}_i^j = (\overline h_i^j,\overline q_i^j)$.
suppose there are n classes:
client i full hyper-knowledge: $\mathcal{K}_i = {\mathcal{K}_i^1,…\mathcal{K}_i^n}$
comparison:
- FedProto only utilizes means of data representations and makes no use of soft predictions. (只利用了表征的均值,没有使用 soft predictions)
Differential Privacy Mechanism
client i transmits noisy version of its hyper-knowledge to the server:
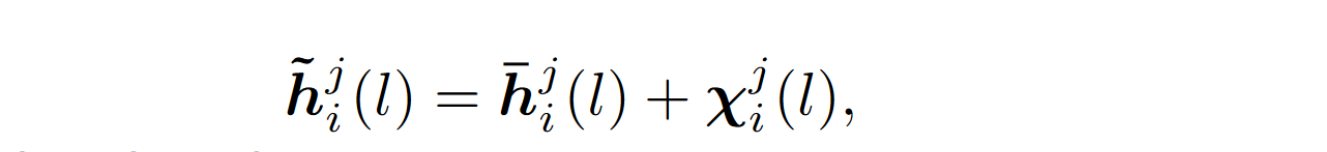
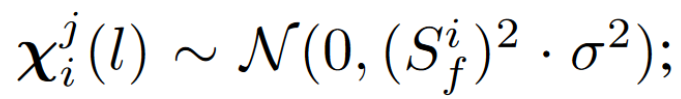
Global Hyper-knowledge aggregation
给 local representation 加了 noise,对于 soft prediction 没有加噪声
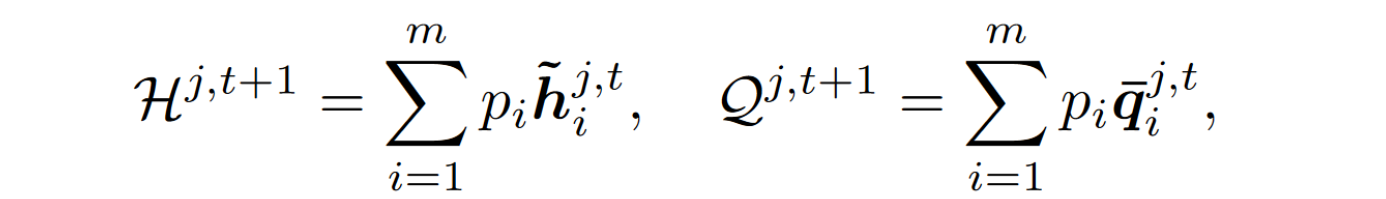
Local training objective
data samples: $(x,y)\in \mathcal{D}_i$
Loss function of client $i$:
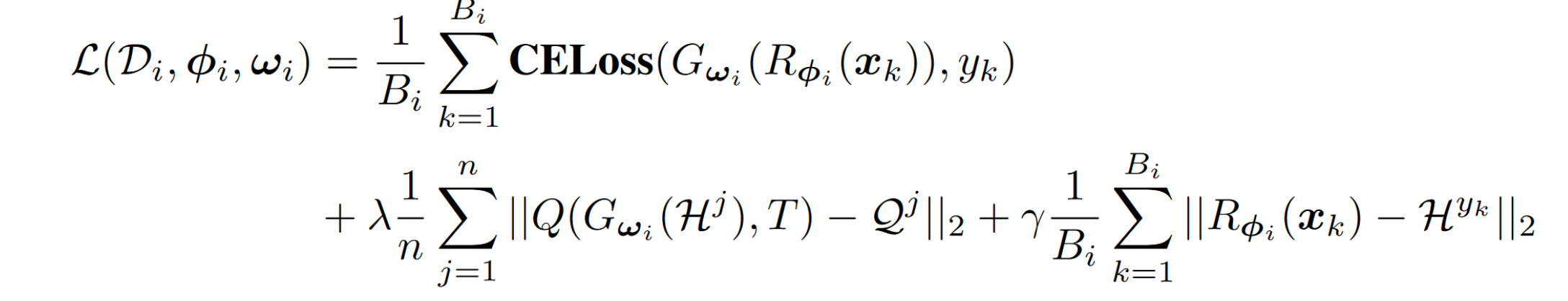
$B_i$ the number of samples
n is the number of classes
$| |_2$ denotes Euclidean norm
$Q(,T)$ soft target function with temperature T
第一项是经验风险, predictions 和 ground-truth labels
后面两项是利用 hyper knowledge 的正则项 (邻近/距离函数)
第二项 force the local classifier to output similar soft predictions when given global data representations
第三项 force the features extractor to output similar data representations when given local data samples

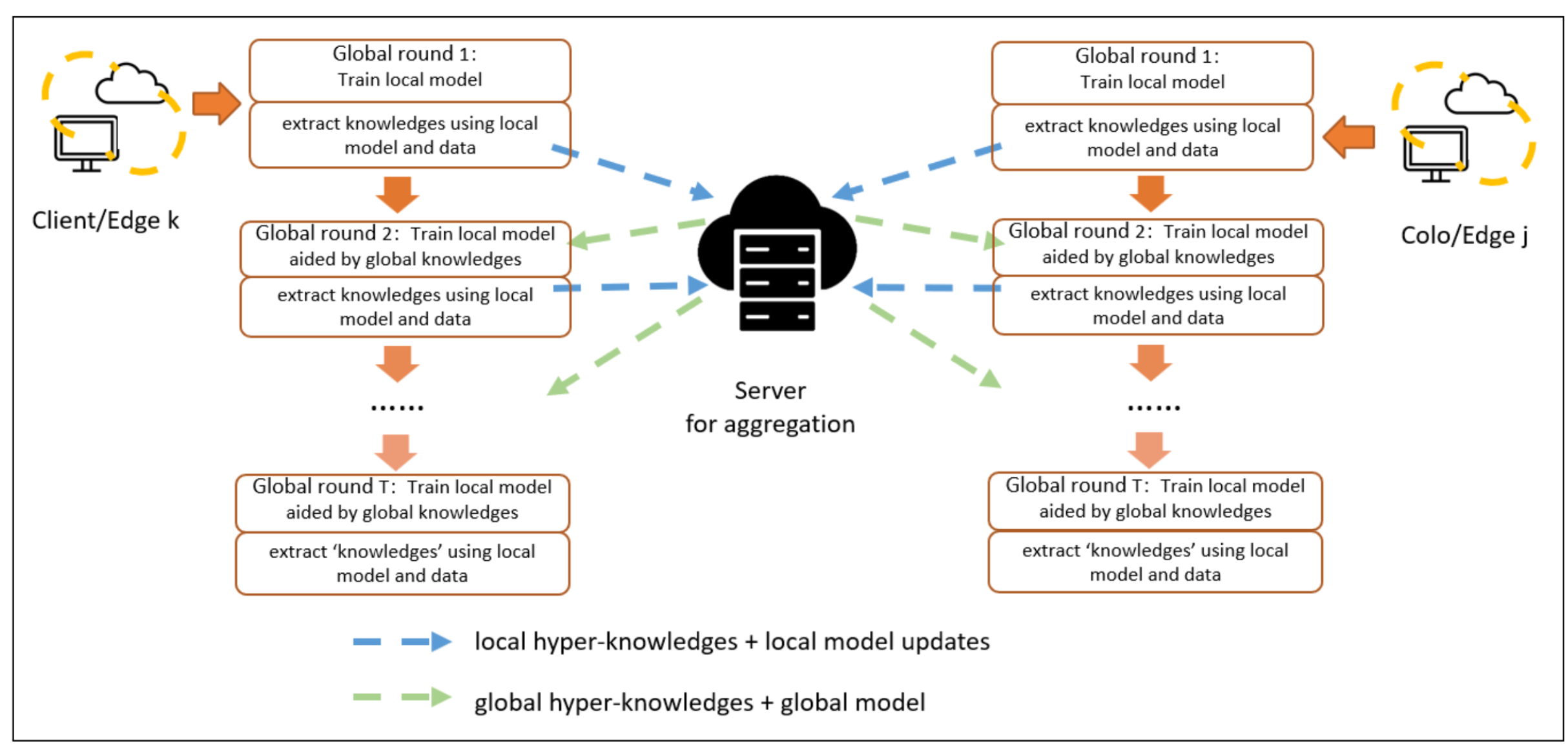
Conclusion
- 实现了无 public dataset 的知识蒸馏,原因是 server 在起初没有 model,直接聚合client knowledge,然后
- 其实这里并没有global model,global model 是直接从 clients 做的权重的模型参数聚合(相当于直接把clients 的模型参数发送给了server)
- 此类情况的 global model 是否应该存在,因为 server 只是做了知识的聚合,真正的更新发生在 clients

