A Hierarchical Knowledge Transfer Framework for Heterogeneous Federated Learning
Metadata
- Item Type: [[Conference paper]]
- Authors: [[Yongheng Deng]], [[Ju Ren]], [[Cheng Tang]], [[Feng Lyu]], [[Yang Liu]], [[Yaoxue Zhang]]
- Proceedings Title: [[IEEE INFOCOM 2023 - IEEE Conference on Computer Communications]]
- Date: [[2023-5-17]]
- Date Added: [[2023-10-05]]
- URL: https://ieeexplore.ieee.org/document/10228954/
- DOI: 10.1109/INFOCOM53939.2023.10228954
- Cite key: dengHierarchicalKnowledgeTransfer2023a
- Topics: [[KD]]
, #zotero, #literature-notes, #reference - PDF Attachments
Abstract
Federated learning (FL) enables distributed clients to collaboratively learn a shared model while keeping their raw data private. To mitigate the system heterogeneity issues of FL and overcome the resource constraints of clients, we investigate a novel paradigm in which heterogeneous clients learn uniquely designed models with different architectures, and transfer knowledge to the server to train a larger server model that in turn helps to enhance client models. For efficient knowledge transfer between client models and server model, we propose FedHKT, a Hierarchical Knowledge Transfer framework for FL. The main idea of FedHKT is to allow clients with similar data distributions to collaboratively learn to specialize in certain classes, then the specialized knowledge of clients is aggregated to a super knowledge covering all specialties to train the server model, and finally the server model knowledge is distilled to client models. Specifically, we tailor a hybrid knowledge transfer mechanism for FedHKT, where the model parameters based and knowledge distillation (KD) based methods are respectively used for client-edge and edge-cloud knowledge transfer, which can harness the pros and evade the cons of these two approaches in learning performance and resource efficiency. Besides, to efficiently aggregate knowledge for conducive server model training, we propose a weighted ensemble distillation scheme with serverassisted knowledge selection, which aggregates knowledge by its prediction confidence, selects qualified knowledge during server model training, and uses selected knowledge to help improve client models. Extensive experiments demonstrate the superior performance of FedHKT compared to state-of-the-art baselines.
Zotero links
Notes
Abstract
FedHKT
- Clients with similar data distributions to collaboratively learn to specialize in certain classes
- Server aggregates to a super knowledge covering all specialties to train the server model
- Server model knowledge is distilled to client models
Contributions
Hybrid knowledge transfer mechanism
parameters based for client-edge
knowledge distillation based for edge-cloud basedWeighted ensemble distillation scheme
server assisted knowledge selection, selected qualified knowledge to help improve client models.
Introduction
Parameter-based FL
传参数或者传梯度的聚合,都是属于 parameter-based FL algorithms, 需要 clients 有相同的 structure.
每个client 都用相同的 model structure 的问题:
- 每个 client 在模型训练和通信的过程中有不同的 capabilities, 如果采用相同的模型架构,就只能去适配 the most resource-starved client.
- 在异构情况下训练相同的模型将不可避免地导致 performance gap,会延迟 training time 以及 straggler problem.
Overcome the system heterogeneity:
- Asynchronous learning
- Hyperparameter adaption,微调 batch size,model size等
- Active sampling,选择 resource-eligible 的 clients 参与训练
- Prune global model 为 clients 派生不同结构的 sub-models(子模型仍然受限于 global model)
云服务器的资源并未得到充分利用,因为现在只需要 server 执行聚合
knowledge distillation (KD) which provides a way to transfer knowledge between different-structured models
SOTA:
- 共享模型输出的 knowledge,而不是模型参数,允许 heterogeneous models across clients but no model is trained on the server.
- 利用clients 的 output 的 knowledge 训练一个 server model
Work
Goal: Train uniquely designed models adapting to their resource capabilities
Efficient knowledge transfer among different-structured client models,using unlabeled public dataset
Limitations
- 每个 client model small and data size or categories are usally limited,提供的 knowledge quality 有限
- Client 异构,导致数据标签分布不均匀,使得客户端模型对于样本的各种标签具有多样化的分类优势,对于一个 sample 的 knowledge output 质量参差不齐
public dataset 又是 unlabeled,难以 evaluation 一个 client 的 knowledge
Method
利用 edge-servers 将 clients 聚类,每个具有相似分布的客户端协作学习共享边缘模型,使其能够专门对某些类别进行分类,即成为领域专家,a domain expert
edge models 输出的 knowledge 发送给 large server, 聚合为 super-knowledge,专门对所有类别进行分类,即成为全局专家,global expert
Comparsion:
基于参数的传输,eg. FedAvg 在 clients 需要更少的计算,在同类数据下性能更好
基于 KD 的传输,通信开销更少,在异构数据下性能更好
基于此,
提出混合 hybrid knowledge transfer,parameters-based 用于 clients-edge,KD-based 用于 edge-cloud
提出 weighted ensemble distillation ,通过预测的结果的置信度来评估 knowledge 的质量,用于权重聚合,获取更高质量的 knowledge
提出 server-assisted knowledge selection,在服务器模型训练过程中迭代选择合格的知识,将其发送给 edge,帮助增强 client models and edge models.
Contributions
- Hierarchical knowledge transfer framework among structure-heterogeneous client models and larger server model
- Hybrid knowledge transfer mechnism
- A weighted ensemble distillation scheme
Background and Motivation
KD 能够支持在不同的模型架构下传输 knowledge,parameter-based 只能是相同的模型架构
KD 对于一个 pre-trained large teacher model $w_T$ 传输 knowledge 到一个 small student model $w_S$, 它们有一个共享数据集 $P$
目标是使得 $w_S$ 去近似 teacher model 的输出
KL 散度用于 student model training.
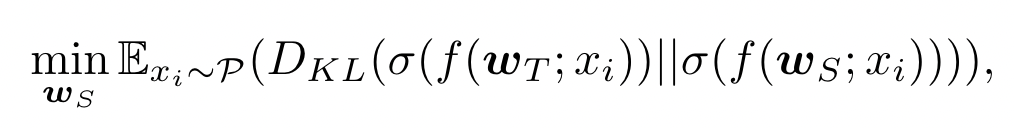
KD 用于 FL,适用于异构客户端模型,客户端和服务器之间共享公共数据集 $D_P$,每个 client 输出的 logit 被发送给 server 聚合,聚合后的 knowledge 用来训练 server 模型
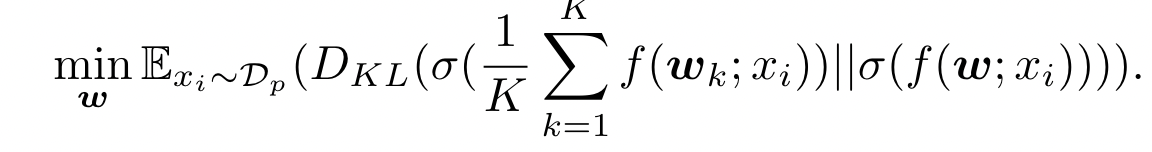
Challenges:
- Knowledge quality 难以保证,clients 的数据是有限的,并且变化较大,model 的 size 是受限的, model is less powerful
- 一个 client 的数据量有限,且数据的种类也有限
- 共享数据集中缺乏 label,无法 evaluate 客户端的质量
System overview
Client side:
Heterogeneity-aware clustering algorithm
- 对数据分布类似的 clients 分组,识别特定的 classes
- Edge model transfers the knowledge on the shared public dataset to the server
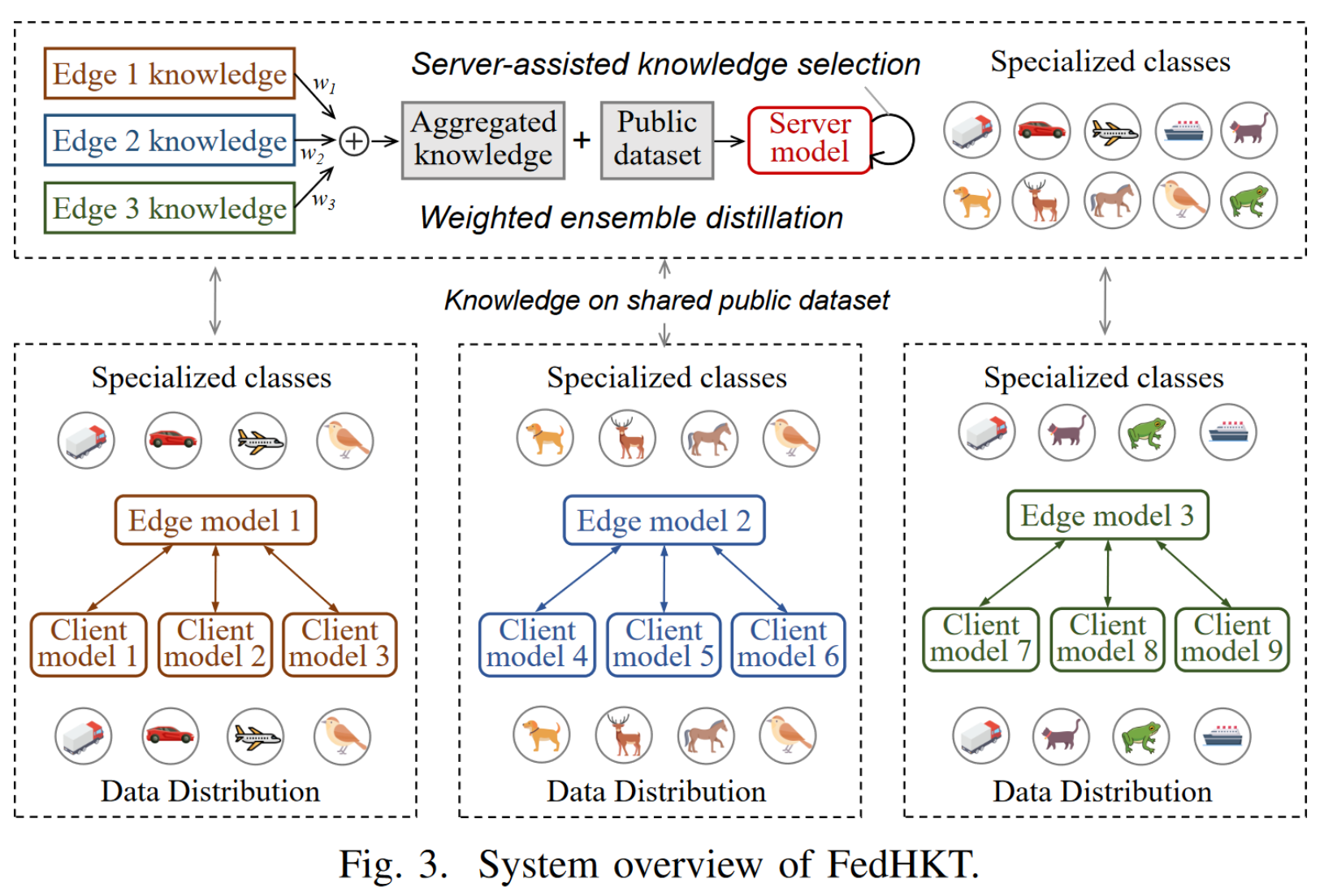
Server side:
weighted ensemble distillation
首先对 client 发来的 knowledge evaluation,计算置信度,执行 knowledge aggregation,获得涵盖所有 edge models 的 super knowledge,用于作为监督信息训练 server model 以识别更多的信息
server-assisted knowledge selection
在 server 训练的过程中,迭代寻找高质量的 knowledge,发送给 edge,提升 edge 的分类性能
Design of FedHKT
Clustering: FedHKT 的聚类内部 clients 的数据是同类的,类间 inter-cluster 的数据分布是异构的
FedAvg is computation-efficient
KD is communication-efficient (logits size and the number of samples)
Client-edge homogeneous data distributions –> FedAvg
Edge-cloud heterogeneous data distributions –> KD
calculate the distance bewteeen tow model weights,但是模型架构不同,会影响 distance
测量依据是: similarity of the client models outputs 来量化 client’s data distribution similarity
$S_c$ 是计算两个预训练模型 k 和 l 的输出的 consine similarity
获得相似度矩阵来聚类
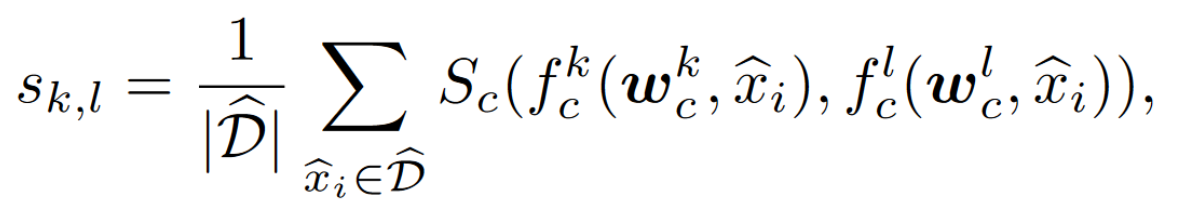
edge models 先聚合 intra-cluster 的 parameters,把输出的 logits $f_e^v(w_e^v,\hat D)$ 发送给 server
Weighted ensemble distillation
计算置信度,即计算预测概率的熵
概率的计算方法
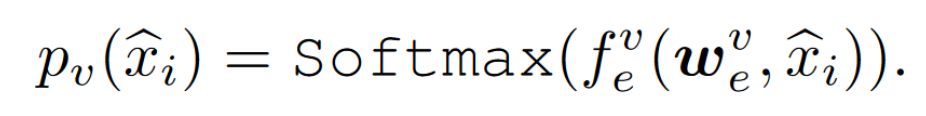
C 是分类的数量
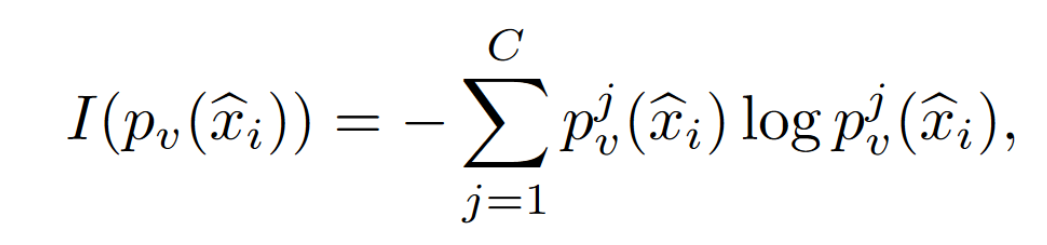
低熵代表高置信度,给低熵的 client 更高的聚合权重
权重定义
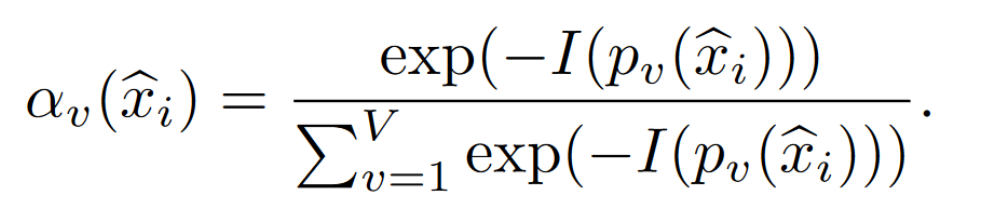
V 是 edge models 的数量,confidence-weighted averaging method to aggregate
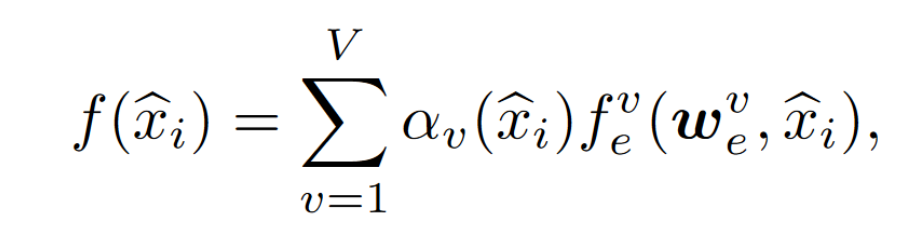
得到聚合后的 server 模型,对于 unlabeled samole $\hat x_i$ 进行预测,得到伪标签 $\hat y_i$ pseudo-label
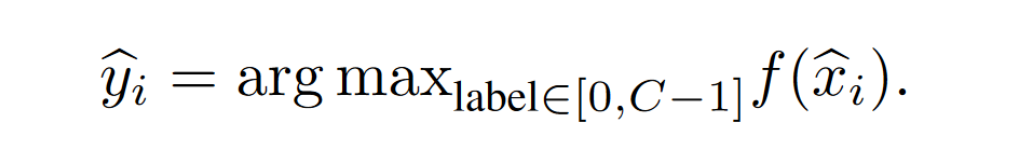
使用 public dataset 的数据和对应的伪标签,训练 server model $f_s(w_s)$
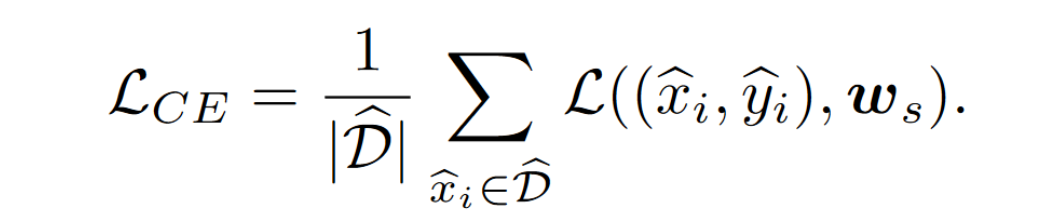
结合 clients 聚合的 logits 以及自己预测之后计算的 logits,计算KL散度
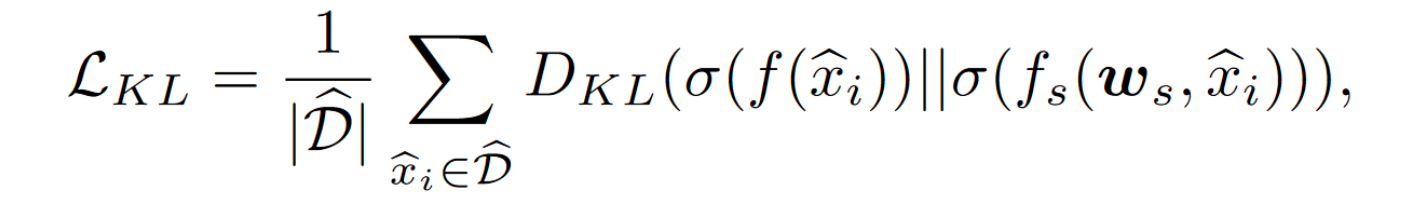
server 训练的目标函数
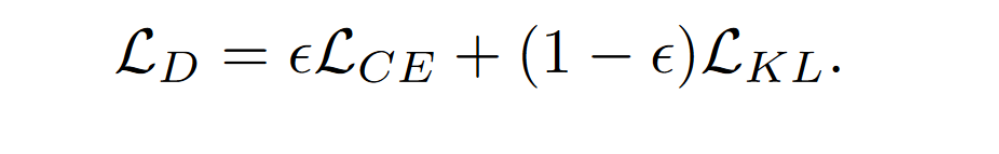
Server-assisted knowledge selection
pick high-quality knowledge.

