PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization
Federated learning (FL) has become a prevalent distributed machine learning paradigm with improved privacy. After learning, the resulting federated model should be further personalized to each different client. While several methods have been proposed to achieve personalization, they are typically limited to a single local device, which may incur bias or overfitting since data in a single device is extremely limited. In this paper, we attempt to realize personalization beyond a single client. The motivation is that during the FL process, there may exist many clients with similar data distribution, and thus the personalization performance could be significantly boosted if these similar clients can cooperate with each other. Inspired by this, this paper introduces a new concept called federated adaptation, targeting at adapting the trained model in a federated manner to achieve better personalization results. However, the key challenge for federated adaptation is that we could not outsource any raw data from the client during adaptation, due to privacy concerns. In this paper, we propose PFA, a framework to accomplish Privacy-preserving Federated Adaptation. PFA leverages the sparsity property of neural networks to generate privacy-preserving representations and uses them to efficiently identify clients with similar data distributions. Based on the grouping results, PFA conducts an FL process in a group-wise way on the federated model to accomplish the adaptation. For evaluation, we manually construct several practical FL datasets based on public datasets in order to simulate both the class-imbalance and background-difference conditions. Extensive experiments on these datasets and popular model architectures demonstrate the effectiveness of PFA, outperforming other state-of-the-art methods by a large margin while ensuring user privacy. We will release our code at: https:// github.com/ lebyni/ PFA.
- 笔记
- Zotero links
- PDF Attachments
Liu 等 - 2021 - PFA Privacy-preserving Federated Adaptation for E.pdf
- Cite key: liuPFAPrivacypreservingFederated2021
Note
Data heterogenity
Current methods
- Further fine-tuning the FL model with the local data in eache client.
- Fine-tuning, multi-task learning and KD
Drawbacks
The personalization process in a single device
—-> bias or overfitting
Federated Adaptation
Many clients that own similar data distribution
—> more valuable data —> extend knowledge —> collaboratively adapt the fed model
- Aggregate and benefit from each other
Privacy Preserving
- Extracts the client-related sparsity vector as a privacy-preserving representation
- Uploads to server to distinguish different distributions.
Euclidean Distance to measure the similarity Generate a matrix that describes the distribution similarity degree among clients
- Group-wise FL
Framework PFA
PFE: a Privacy-preserving Feature Extraction module
feature map sparsity to represent the distribution property of clients
FSC: a Feature Similarity Comparison module, Euclidean Distance to measure the similarity
CSM: a Client Scheduling Module, upload its corresponding local trained model and the server selectively groups these models and aggregates them
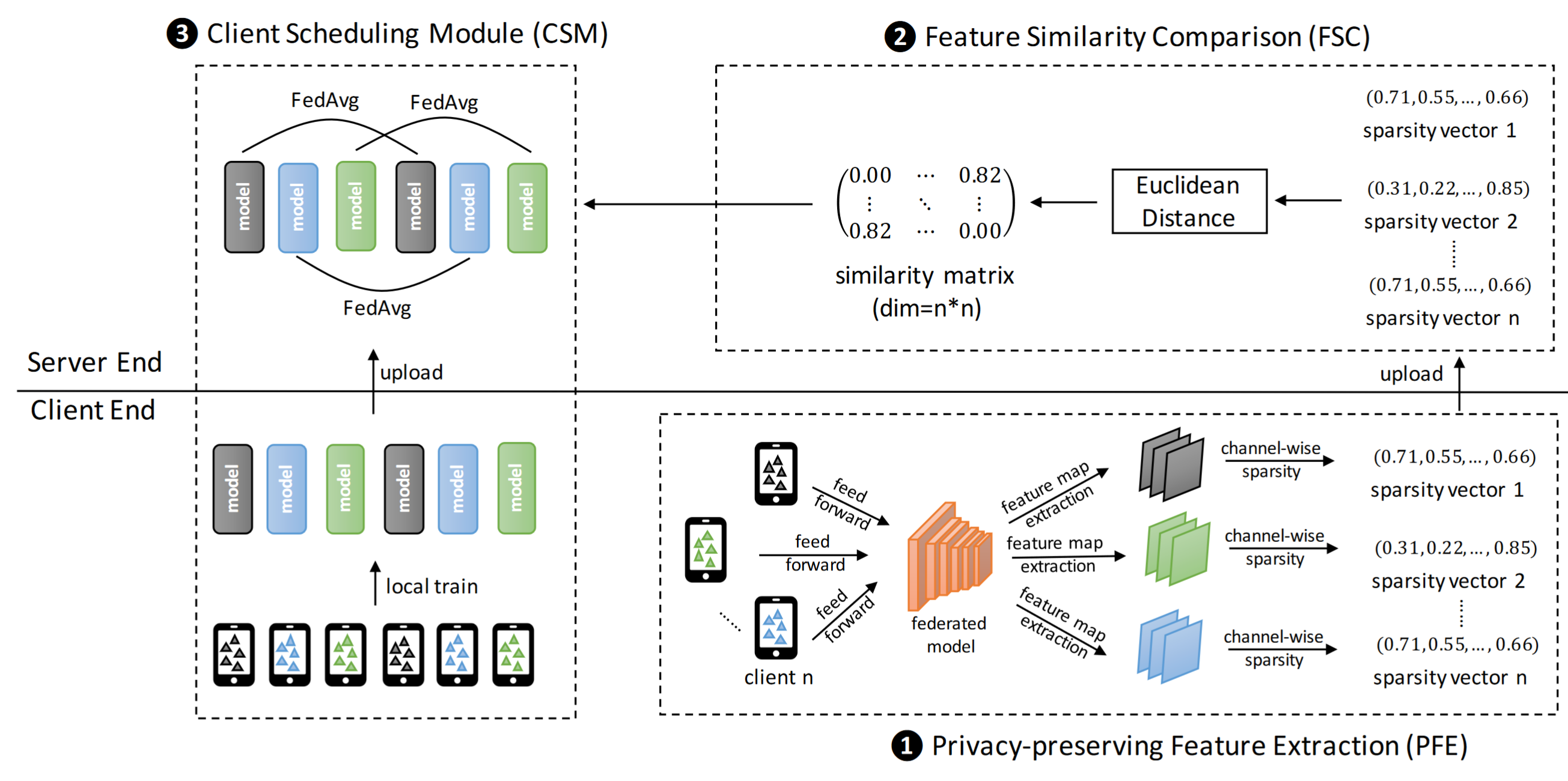
PPFE Privacy-preserving Feature Extraction
FL intermediate channel sparsity can express data distribution information of the client.
Sparsity
The $i_{th}$ Client, data $D_i = (x_1^i, x_2^i,…x_N^i)$
$F(x_p^i)\in R^{H\times W\times C}$ is feature map extracted from a ReLU layer.
$H\times W$ is map size, $C$ is the channel nums.
For a channel sparsity:
A sample $x_p^i$
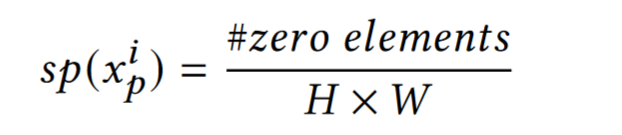
Average each sample $x_j^i$ in $D_i$
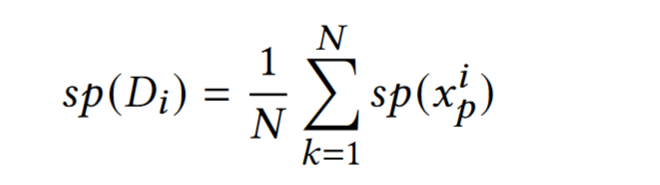
- Randomly select $q$ channels $(c_1,c_2,…c_q)$ in the FL model
- Extract $i_{th}$ client sparsity to form a sparsity vector $R_i$
- Generate a representation and upload to the server.
Feature Similarity Comparison
Euclidean Distance as the metric.
The $i_{th}$ client and the representation $R_i$
The $j_{th}$ client and the representation $R_j$
Similarity
$E_i^k$ is the $k_{th}$ element in $R_i$
$R_i$ has $q$ elements (pich q channels)
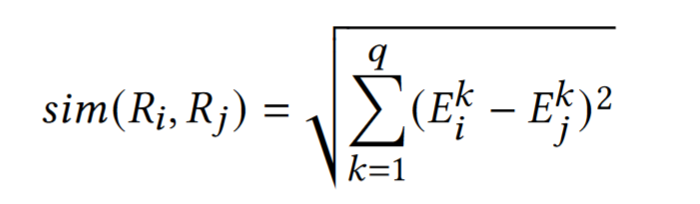
Generate matrix $S$
$S_{i,j}$ is the similarity between the $i_{th}$ and the $j_{th}$ client
But not effiency ….. ($N^2$ times )
we only calculate the similarity with respect to one client rather than the whole clients.
- Randomly select the representation $R_z$ of the $z_{th}$ client
- Calculate the Eudiean Distance between it and other representations, a final similarity vector
If sim($R_z,R_t$) is low, we believe the $t_{th}$ client has similar data distribution to the $z_{th}$ client
If sim($R_z$,$R_t$) and sim($R_z$,$R_u$) is close, we believe $t_{th}$ and $u_{th}$ are similar
Client Scheduling Module
Task: Pick out a series of clients with similar data distribution and utilizing them to cooperatively personalize the federated model.
partition the whole clients into different groups
(Each group –> a certain data distribution)
1、local train.
2、upload local models and grouped according to the similarity matrix.
similar models –> similar distribution
3、FedAvg in each group,making the resulting model customized to a certain distribution.
Related work
Federated Learning and Personalization
提出了 user clustering 用户聚类的想法,相似的用户被分到一起,独自为每个 group 训练一个 model。
缺点:需要每个用户的原始数据实现聚类
Wang 等提出迁移学习实现个性化,训练的联合模型的部分或全部参数在本地数据上重新学习(即微调),而不与用户数据进行任何交换。
Jiang 等也进行微调,构建个性化联邦模型,但该模型通过 meta-learning 生成。
Yu 等进一步扩展了之前的工作,系统地评估三个个性化联邦的性能,fine-tuning, multi-task learning, knowledge distillation。
本文通过 Federated adaptation,利用其他客户端中存在的更有用的知识,消除个性化过程中的过度拟合问题或训练偏差。
Sparsity of CNNs
现有工作利用 activation map 的稀疏性,加速 CNN。
本文尝试使用稀疏性来区别不同分布的客户,这与以稀疏化作为加速的目的不同。
Privacy Protection of User Data.
SMC需要大量的计算能力和通信成本,这对于客户端来说是无法接受的。
对于DP,我们基于稀疏性的表示可以很容易地添加到噪声中以满足DP的原则,
Conclusion
1、扩展了限制在单个设备中的现有个性化技术
2、提出PFA,利用 sparsity vector 比较 clients 的相似度,来对clients 分组

