Parameter-Efficient Transfer Learning for NLP
Metadata
- Tags: #TransferLearning #Adapter
- Authors: [[Neil Houlsby]], [[Andrei Giurgiu]], [[Stanisław Jastrzebski]], [[Bruna Morrone]]
笔记
Zotero links
- PDF Attachments
Houlsby 等 - Parameter-Efficient Transfer Learning for NLP.pdf
- Cite key: houlsbyParameterEfficientTransferLearning
Note
fine-tuning is parameter inefficient
Propose:transfer with adapter modules,a compact and extensible model;
only a few trainable parameters per task
Transfer learning in NLP:
- feature-based transfer
-pre-training real-valued embeddings vectors. The embeddings are then fed to custom downstream models - fine-tuning (better performance)
-copying the weights from a pre-trained network and tuning them on the downstream task.
Adapters:
added between layers
injecting new layers into the original network. The weights of the original network are untouched,
Comparasion:
- Fine-tuning, the new top-layer and the original weights are co-trained
- Adapter-tuning, the parameters of the original network are frozen and therefore may be shared by many tasks.
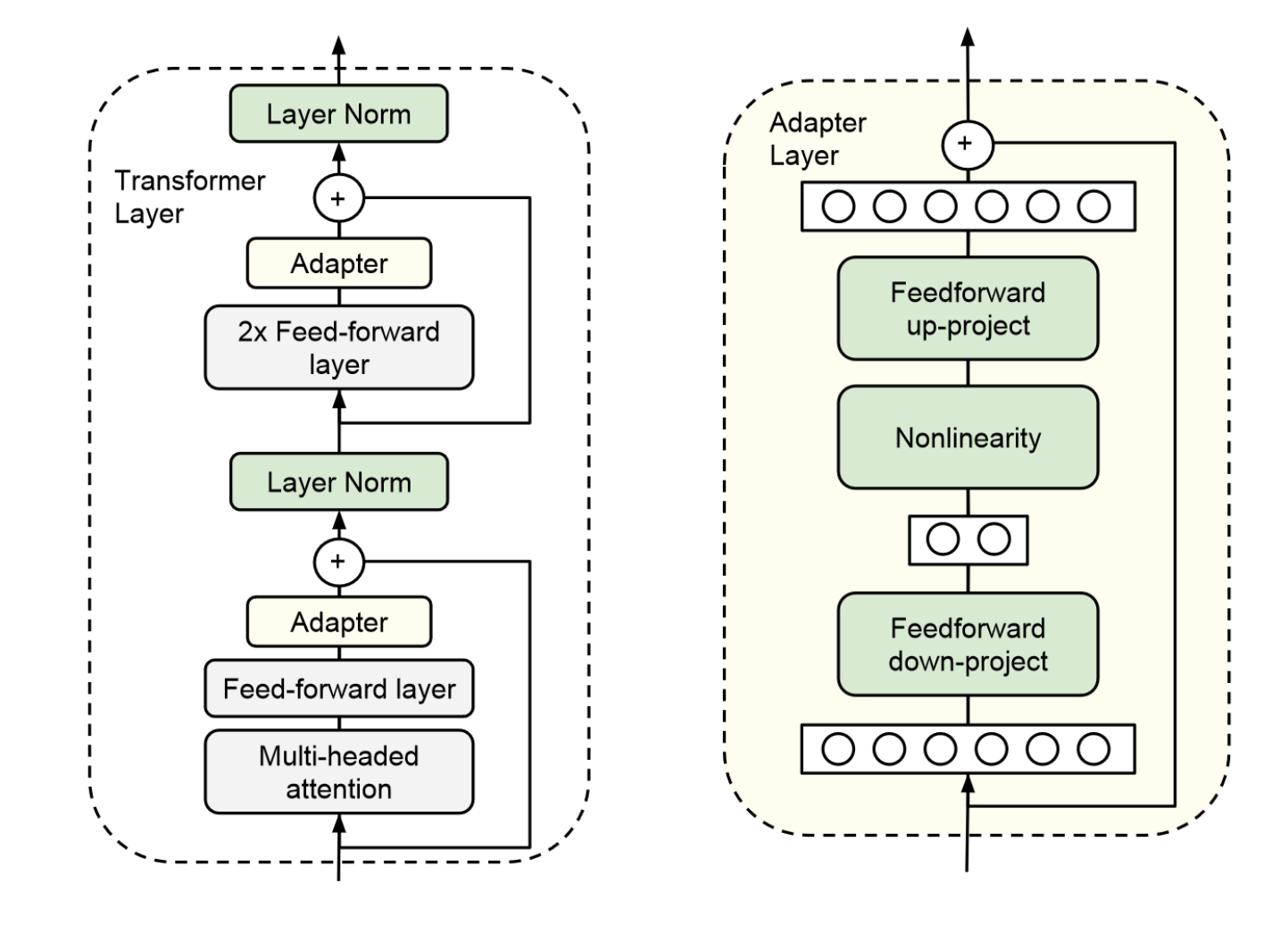
Left: We add the adapter module twice to each Transformer layer
Right: The adapter consists of a bottleneck which contains few parameters relative to the attention and feedforward layers in the original model.

