SplitFed: When Federated Learning Meets Split Learning
Metadata
- Tags: #/unread
- Authors: [[Chandra Thapa]], [[Pathum Chamikara Mahawaga Arachchige]], [[Seyit Camtepe]], [[Lichao Sun]]
Abstract
Federated learning (FL) and split learning (SL) are two popular distributed machine learning approaches. Both follow a model-to-data scenario; clients train and test machine learning models without sharing raw data. SL provides better model privacy than FL due to the machine learning model architecture split between clients and the server. Moreover, the split model makes SL a better option for resource-constrained environments. However, SL performs slower than FL due to the relay-based training across multiple clients. In this regard, this paper presents a novel approach, named splitfed learning (SFL), that amalgamates the two approaches eliminating their inherent drawbacks, along with a refined architectural configuration incorporating differential privacy and PixelDP to enhance data privacy and model robustness. Our analysis and empirical results demonstrate that (pure) SFL provides similar test accuracy and communication efficiency as SL while significantly decreasing its computation time per global epoch than in SL for multiple clients. Furthermore, as in SL, its communication efficiency over FL improves with the number of clients. Besides, the performance of SFL with privacy and robustness measures is further evaluated under extended experimental settings.
- 笔记
- Zotero links
- PDF Attachments
Thapa 等 - 2022 - SplitFed When Federated Learning Meets Split Lear.pdf
- Cite key: thapaSplitFedWhenFederated2022
Note
Abstract
Split learning
Prons:
- Model architecture split between clients and the server.
- Split learning 更适用于 resource-constrained.
Cons: - Slower, relay-based training across multiple cllients, 接力训练
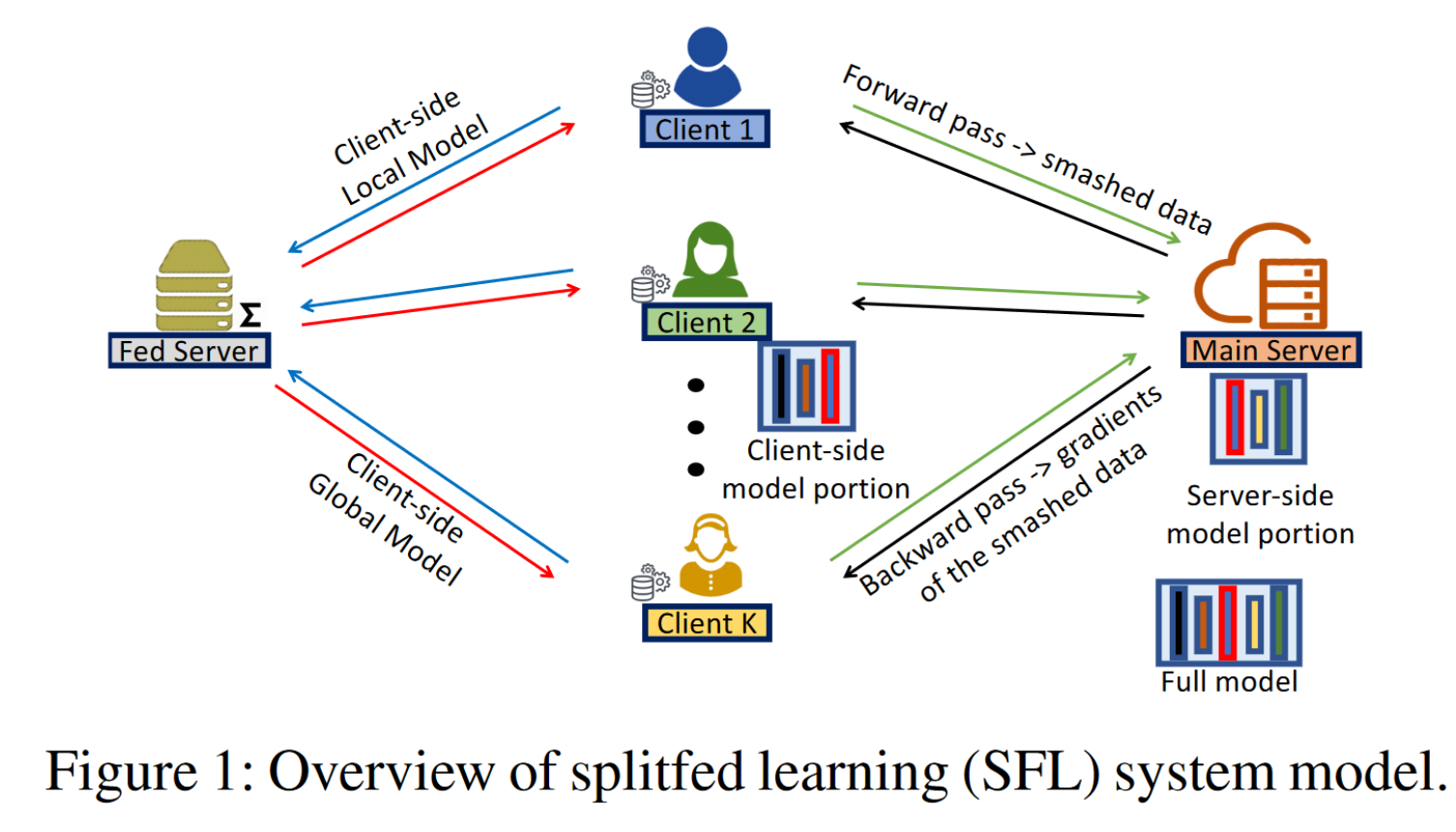
Proposed Framework
Main server,high-performance computing resources.
Fed server, conducts FedAvg on the clientside local updates
Workflow
Clients side
- Forward propagation, parallel
- Pass smashed data to the main server
Main server
- Forward propagation and back-propagation
- Sends gradients of the smashed data to the respective clients
- Updata its main server model
Clients side
- Receive gradients, back-propagation, computes gradients
- DP + gradients , send to the fed server
Fed server
- Conducts the FedAvg of their local updates
- Sends aggregation to all participants
Variants of SFL
Based on Server-side Aggregation
variants of SFL: removing the model aggregation part in the server-side computation module
The forward-backward propagations of the server-side model sequentially with respect to the client’s smashed data
Based on data label sharing
- Share data labels to the server
- Without sharing any data labels to the server
Clients will process 2 client-side model portions, one with the first few layers, another with the laset few layers. Middle layers will be computed at the server-side.

Privacy Protection at the Client-side
- Differential privacy to the client-side model training
- PixelDP noise layer in the client-side model.
Privacy Protection at the Fed Server
Clipped the gradients
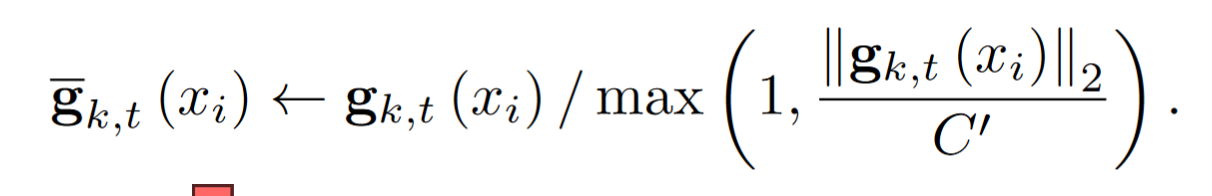
Add noise
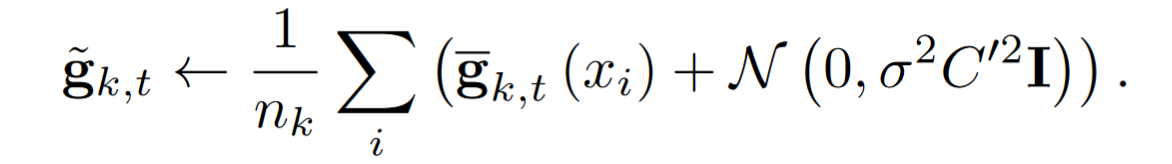
client 对加噪后的梯度进行 update

Privacy Protection on Main Server.
Smashed data to the main server 可能泄露信息
Integrate a noise layer in the client-side model based on the concepts of PixelDP

Conclusion
Faster than SL by parallel processing across clients.
SFL has similar performance compared to SL
Hybrid approach that supports machine learning with resource-constrained devices.

