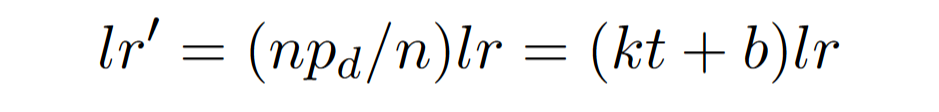BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
Metadata
- Tags: #Bert #Compression
- Authors: [[Canwen Xu]], [[Wangchunshu Zhou]], [[Tao Ge]], [[Furu Wei]], [[Ming Zhou]]
Abstract
In this paper, we propose a novel model compression approach to effectively compress BERT by progressive module replacing. Our approach first divides the original BERT into several modules and builds their compact substitutes. Then, we randomly replace the original modules with their substitutes to train the compact modules to mimic the behavior of the original modules. We progressively increase the probability of replacement through the training. In this way, our approach brings a deeper level of interaction between the original and compact models. Compared to the previous knowledge distillation approaches for BERT compression, our approach does not introduce any additional loss function. Our approach outperforms existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression.
- 笔记
- Zotero links
- PDF Attachments
- Cite key: xuBERTofTheseusCompressingBERT2020a
Note
- Divide the original BERT into several modules and build their substitutes.
- Randomly replace the original modules with their substitutes to mimic the behavior of the origin modules.
Compare to KD, outperforms than KD, no need for loss function.
Transformer-based pretrained models:
- NLU
- NLG
Compression methods:
- Quantization
- Weights Pruning
- Knowledge Distillation (KD)
KD cons:
Welldesigned distillation loss function which forces the student model to behave as the teacher, to minimize the distance between the teacher model and the student model
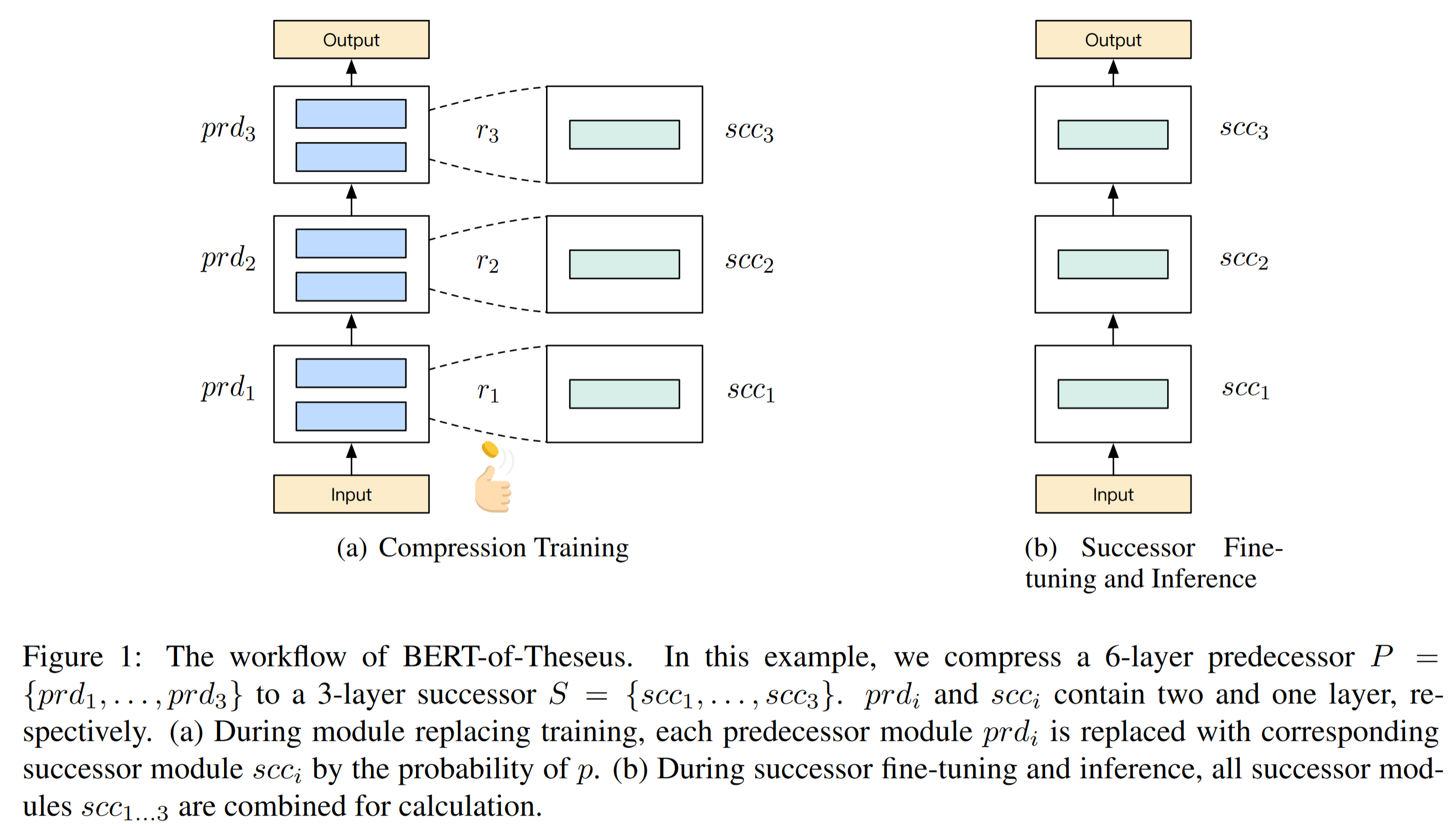
BERT-ofTheseus:
original model –> predecessor
compressed model –> successor
Training:
为每个 predecessor module 指定 substitute
Randomly replace each predecessor module with successor.
Fine-tune and Inference:
Combine all successor modules to be the successor model for inference.
Large predecessor model ——> A compact successor model
Theseus Compression(TC) vs KD
Both encourages the compressed model to behave like the original
Difference:
1、TC only use the task-specific loss function, but KD use task-specific loss, together with one or multiple distillation losses as its optimization objective.
(TC只需要特定于任务的损失,但是KD在此基础上还需要一个或者多个蒸馏损失作为优化目标)
2、选择不同的 loss functions and balancing the weights of each loss 是很费力的
3、KD 是只使用 teacher model 进行推理,TC 可以允许 teacher 和 student 关联工作,实现 gradient-level interaction.
4、混合 predecessor 和 successor 能够增加额外的正则化,similar to Droout.
第 i+1 个 module 的输出:.
$r_{i+1}$ 是第 i+1 个 module 被替换的概率,$r_{i+1} -Bernoulli(p)$
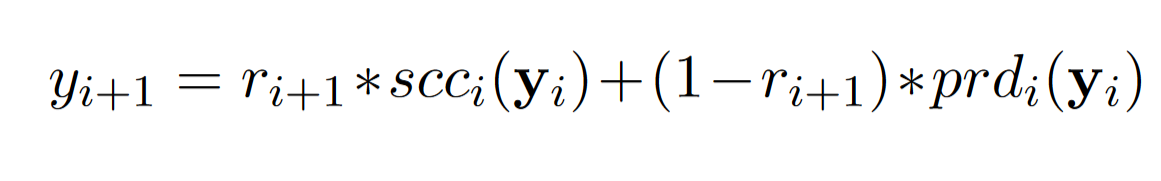
module 的替换是随机的,因此 adds extra noises,为后续添加了正则化 (类似于 Dropout)
Training objective:
$z_j$ 代表真实标签
$c$ 代表类标签
$x_j$ 是第 j 个训练样本
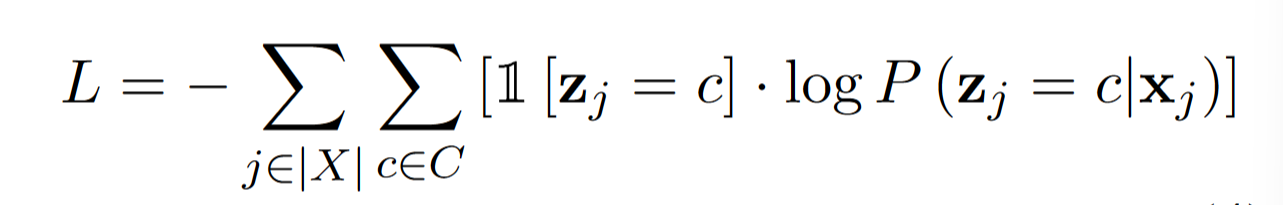
BP 的时候, predecessors modules 的 weights 都是 frozen 的
使用 successors 的 weights 计算梯度
设计一个替换调度程序来动态调整替换率 p
线性函数 $\theta(t)$
k 是系数,b 是基本替换率
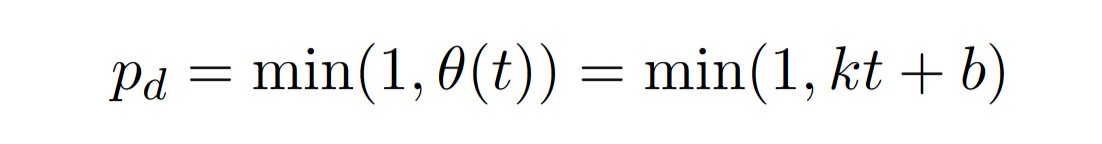
这样替换可以保证训练由易到难的过程,助于平滑学习过程,鼓励模型主动学习预测,并逐步过渡到微调阶段,如图右所示
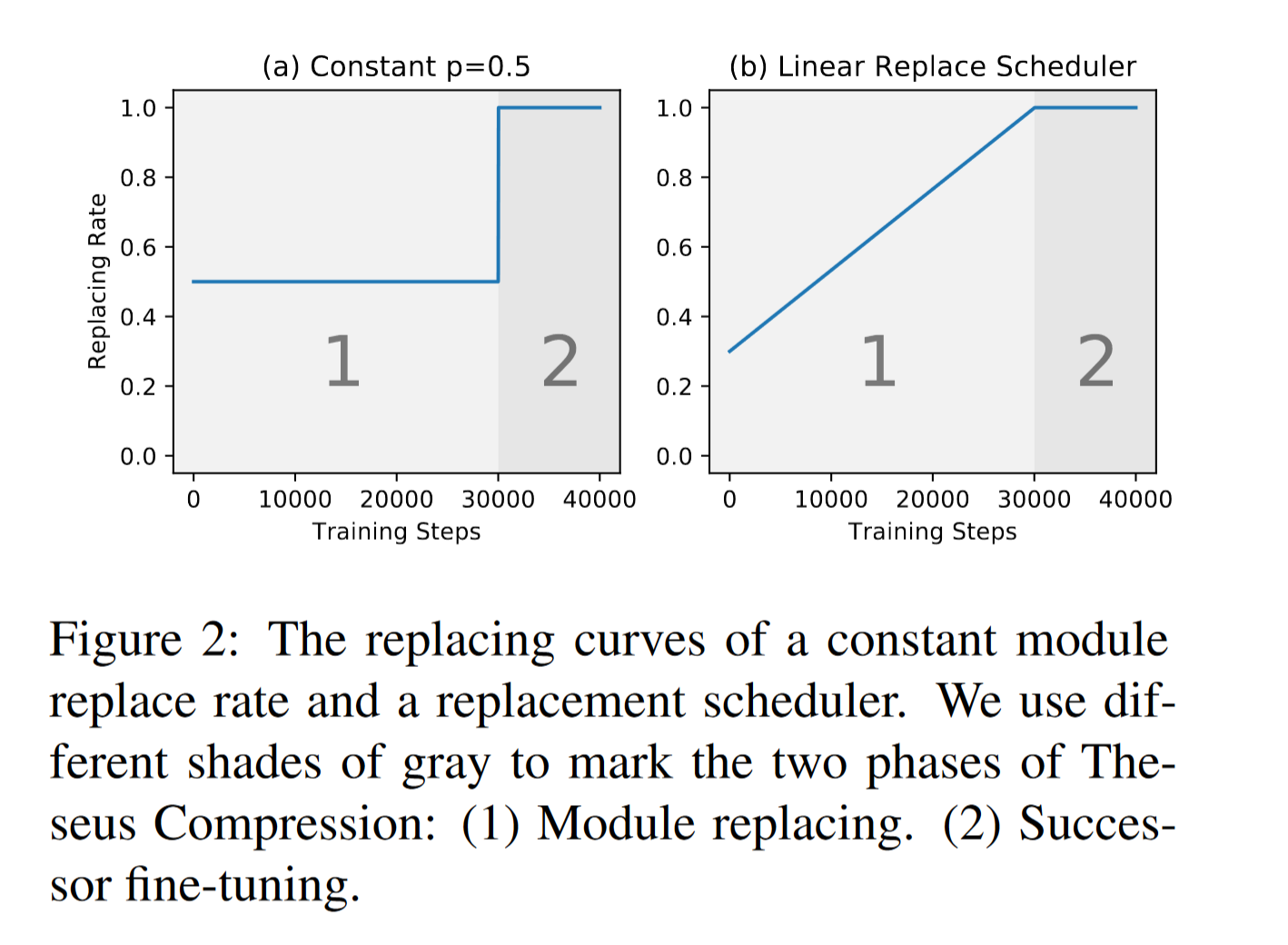
学习率随之动态变化,类似a warm-up mechanism
lr 是固定的学习率
lr’ 是考虑所有后续模块的等效学习率