FedGEMS Federated Learning of Larger Server Models via Selective Knowledge Fusion
Metadata
- Authors: [[Sijie Cheng]], [[Jingwen Wu]], [[Yanghua Xiao]], [[Yang Liu]], [[Yang Liu]]
- Date: [[2021-12-07]]
- Date Added: [[2023-10-04]]
- URL: http://arxiv.org/abs/2110.11027
- DOI: 10.48550/arXiv.2110.11027
- Cite key: chengFedGEMSFederatedLearning2021
- Topics: [[KD]]
- Tags: #Selective-Knowledge-Fusion #Federated-Learning
- PDF Attachments
Abstract
Today data is often scattered among billions of resource-constrained edge devices with security and privacy constraints. Federated Learning (FL) has emerged as a viable solution to learn a global model while keeping data private, but the model complexity of FL is impeded by the computation resources of edge nodes. In this work, we investigate a novel paradigm to take advantage of a powerful server model to break through model capacity in FL. By selectively learning from multiple teacher clients and itself, a server model develops in-depth knowledge and transfers its knowledge back to clients in return to boost their respective performance. Our proposed framework achieves superior performance on both server and client models and provides several advantages in a unified framework, including flexibility for heterogeneous client architectures, robustness to poisoning attacks, and communication efficiency between clients and server on various image classification tasks.
Zotero links
Highlights and Annotations
- [[FedGEMS Federated Learning of Larger Server Models via Selective Knowledge Fusion - Comment Under review as a conference paper at ICLR 2022]]
Notes
Abstract
large server 有选择性地从多个teacher clients 中学习
server 把自己的 knowledge 传输回 clients
Introduction
FedGKT 是 large server 一次向一个 small teacher 学习的,没有从多个 teachers 学到一致性的 knowledge
现有的 KD 都假设 server 与 clients 模型是相同的架构
Related work
KD 通过 logits 传输 knowledge,而不是传输 parameters
在多个 teacher models 的指导下,Student model 能够有更好的能力
- FedMD 采用 labeled public dataset and averaged logits 传输 knowledge
- FedDF 提出 ensemble distillation, 通过聚合来自 clients 的 logits and models 来完成 model fusion.
- Cronus and DS-FL 利用 soft labels 的 public dataset 以及 local private dataset 来完成 local training.
Methodology
client 有自己的本地模型,这个本地模型可以是相同的,也可以是不同的
server 和 clients 都可以访问的一个公开且有label的数据集
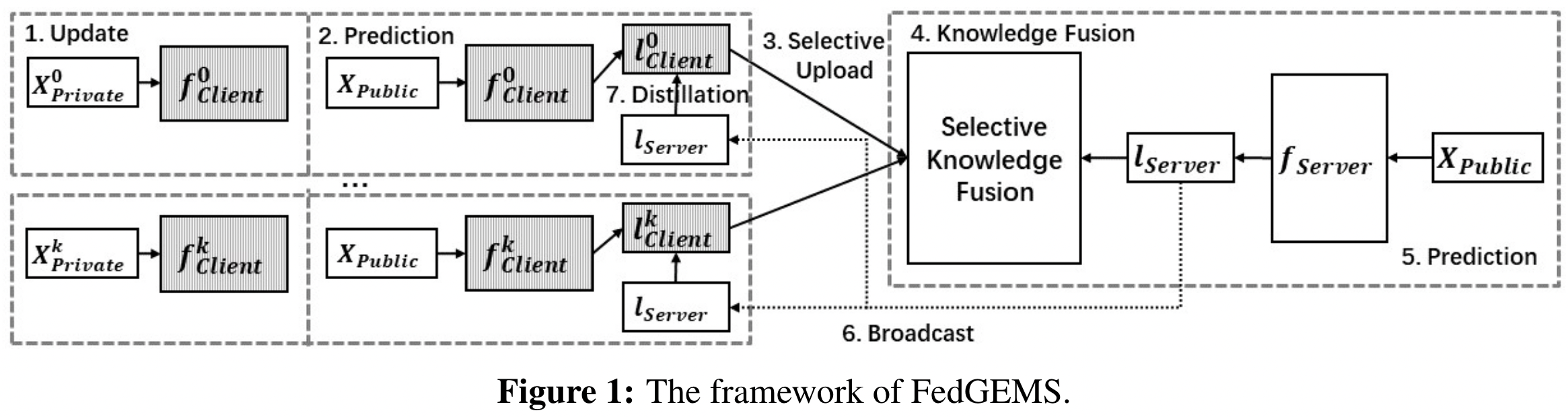
FedGEM:
1、clients 在本地使用 private datasets 训练多个 epochs,然后在 public datasets 做预测,得到 logits, 作为 knowledge 传输给 server
2、server 聚合 clients 的 logits,在 fused knowledge 引导下训练 server model,并将 logits 传输回 clients
3、clients 对收到 server 的 logits 做知识蒸馏,并继续在 private datasets 上面做训练
多次交互迭代训练,获得大型服务器模型和高性能客户端模型
FedGEMS:
server 有选择地加权挑选 knowledgeable clients 来聚合
在客户端模型异构或者存在恶意攻击者的情况下,clients 的 knowledge 可能对 server 的 model 性能产生负面影响,通过 selective 策略,选择 positive knowledge 融合到 server model
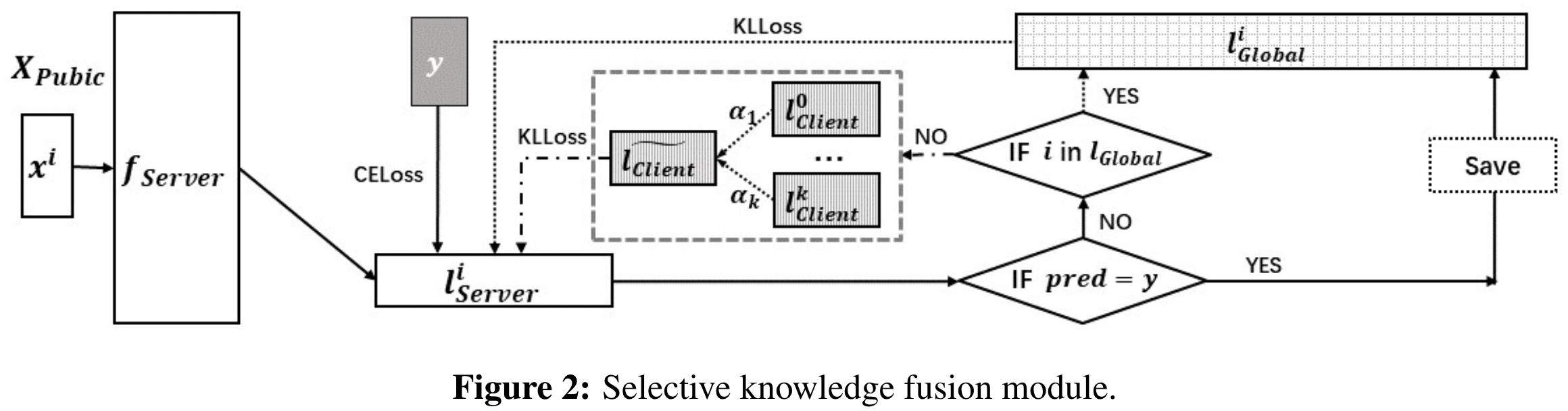
Server side
Selective knowledge fusion
Self-distillation of server knowledge
server 先在 public datasets 做预测,evaluation,并根据预测是否正确,划分为 $S_{correct}$ 和 $S_{Incorrect}$
对于预测正确的样本,即 $S_{Correct}$ 直接使用交叉熵来训练 server model,并把得到的 logits $l_S^i$ 保存到 global pool 中 $l_{GLobal}^i$,用于后续在 self-distillation 中恢复 memory
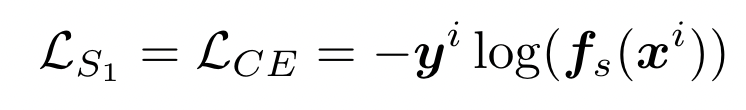
对于预测错误的样本,server 首先判断这个样本是否在 $l_{Global}^i$ 中,如果不在,则说明 server 自己能力有限,不能训练得到正确的 label,那么需要 clients 的 collective knowledge 作为 teacher;如果存在,则说明 server 之前保存这个能力,通过 self-distillation 恢复出来
self-distillation 的目标:
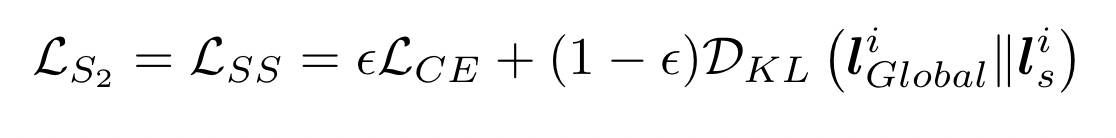
优点: self-distillation 得到的model,比通过不同的架构的模型得到的准确率好,且极大减少了通信
Client Side
Selective ensemble distillation
根据相对重要性,客户端加权选择
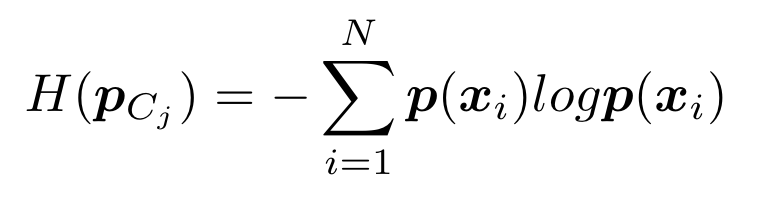
根据客户端对 $S_{Incorrect}$ 的预测结果,对其进行划分, reliable 和 unreliable
unreliable 的权重设置 0
reliable 的 clients 我们认为它们是可靠的,并使用它们的熵 $H(p_{C_j} )$ 作为置信度的度量
(熵越低,置信度越差,所以这里是倒数)
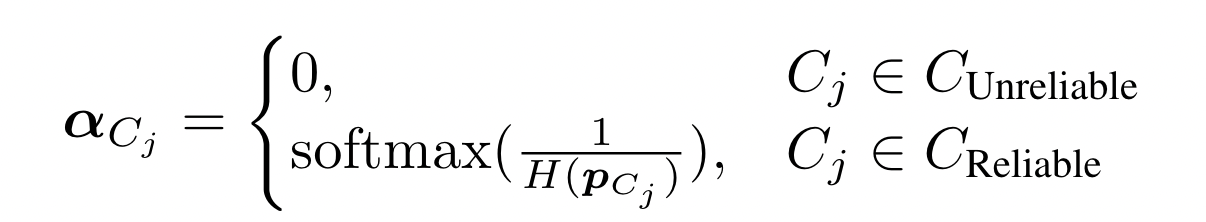
对于预测错误的样本,server 要从 teacher clients 中提取知识: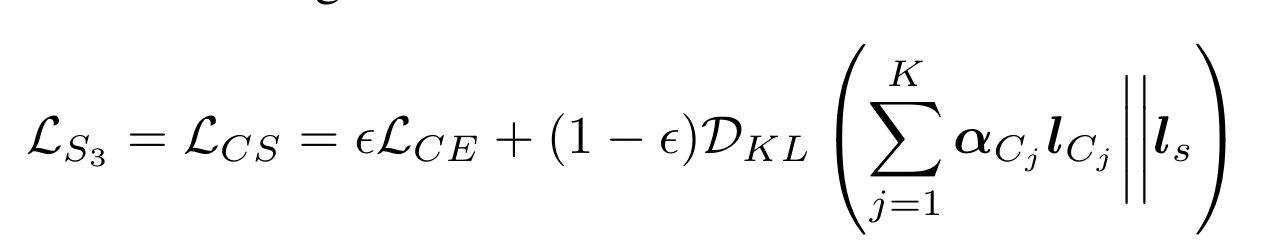
Training on clients
每个 client 收到 server 对 public datasets 的 loss,然后从 logits 提取知识,并计算交叉熵以在公共数据集上进行训练。
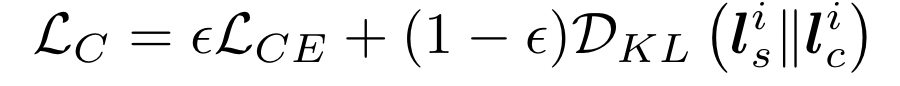
进一步采用交叉熵损失在其本地私有数据集上进行训练,以更好地适应其目标分布。

Experiments
异构设置:
- non-iid 采用 Dirichlet distribution
- model 的异构性
Baselines:
- Stand-Alone: server 和 clients 各自在本地数据集上训练 $X^0$ $X^k$
- Centralized clients: 模型中整个 private 数据集上训练 ${X^1+ X^2+…+X^k}$
- Centralized-All:Server 和 clients 在整个数据集上执行中心化的训练 ${X^0 + X^1+ X^2+…+X^k}$ ,这是性能的上界
Conclusion
large deeper server model 能够更加有效 fuse and accumulate knowledge
selective and weighted criterion 只选择 positive knowledge to defense poision attacks
experiments result : better performance, robustness
Disadvantage: dependence of public datasets
Thoughts
实验做的非常完善,对比既有 baselines 又有近两年的很多方案
knowledge 通常好像是值 logits,从之前的传输 parameters 到 传输 gradients,到传输 embedding,再到 logits
探究了不同的 server 模型大小的影响,以及不同客户端数量的影响
做了消融实验,探究了各个部分的影响
针对的防御是 poisoning attacks, 对于几种常见的数据中毒攻击 PAE、LIE、OFOM 做了鲁棒性验证
做了通信量的对比,验证了更少的通信开销
直观展示了在 self-training 的过程中,通过 self-distillation 和 ensemble distillation 需要的 knowledge 量的变化

